 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRTLSeek: Boosting the LLM-Based RTL Generation with Multi-Stage Diversity-Oriented Reinforcement Learning
Mar 29, 2026Register Transfer Level (RTL) design translates high-level specifications into hardware using HDLs such as Verilog. Although LLM-based RTL generation is promising, the scarcity of functionally verifiable high-quality data limits both accuracy and diversity. Existing post-training typically produces a single HDL implementation per specification, lacking awareness of RTL variations needed for different design goals. We propose RTLSeek, a post-training paradigm that applies rule-based Diversity-Oriented Reinforcement Learning to improve RTL correctness and diversity. Our Diversity-Centric Multi-Objective Reward Scheduling integrates expert knowledge with EDA feedback, and a three-stage framework maximizes the utility of limited data. Experiments on the RTLLM benchmark show that RTLSeek surpasses prior methods, with ablation results confirming that encouraging broader design-space exploration improves RTL quality and achieves the principle of "the more generated, the better results." Implementation framework, including the dataset, source code, and model weights, is shown at https://anonymous.4open.science/r/DAC2026ID71-ACB4/.
From Buffers to Registers: Unlocking Fine-Grained FlashAttention with Hybrid-Bonded 3D NPU Co-Design
Feb 11, 2026Transformer-based models dominate modern AI workloads but exacerbate memory bottlenecks due to their quadratic attention complexity and ever-growing model sizes. Existing accelerators, such as Groq and Cerebras, mitigate off-chip traffic with large on-chip caches, while algorithmic innovations such as FlashAttention fuse operators to avoid materializing large attention matrices. However, as off-chip traffic decreases, our measurements show that on-chip SRAM accesses account for over 60% of energy in long-sequence workloads, making cache access the new bottleneck. We propose 3D-Flow, a hybrid-bonded, 3D-stacked spatial accelerator that enables register-to-register communication across vertically partitioned PE tiers. Unlike 2D multi-array architectures limited by NoC-based router-to-router transfers, 3D-Flow leverages sub-10 um vertical TSVs to sustain cycle-level operator pipelining with minimal overhead. On top of this architecture, we design 3D-FlashAttention, a fine-grained scheduling method that balances latency across tiers, forming a bubble-free vertical dataflow without on-chip SRAM roundtrips. Evaluations on Transformer workloads (OPT and QWEN models) show that our 3D spatial accelerator reduces 46-93% energy consumption and achieves 1.4x-7.6x speedups compared to state-of-the-art 2D and 3D designs.
Understanding and Mitigating Errors of LLM-Generated RTL Code
Aug 07, 2025Despite the promising potential of large language model (LLM) based register-transfer-level (RTL) code generation, the overall success rate remains unsatisfactory. Errors arise from various factors, with limited understanding of specific failure causes hindering improvement. To address this, we conduct a comprehensive error analysis and manual categorization. Our findings reveal that most errors stem not from LLM reasoning limitations, but from insufficient RTL programming knowledge, poor understanding of circuit concepts, ambiguous design descriptions, or misinterpretation of complex multimodal inputs. Leveraging in-context learning, we propose targeted error correction techniques. Specifically, we construct a domain-specific knowledge base and employ retrieval-augmented generation (RAG) to supply necessary RTL knowledge. To mitigate ambiguity errors, we introduce design description rules and implement a rule-checking mechanism. For multimodal misinterpretation, we integrate external tools to convert inputs into LLM-compatible meta-formats. For remaining errors, we adopt an iterative debugging loop (simulation-error localization-correction). Integrating these techniques into an LLM-based framework significantly improves performance. We incorporate these error correction techniques into a foundational LLM-based RTL code generation framework, resulting in significantly improved performance. Experimental results show that our enhanced framework achieves 91.0\% accuracy on the VerilogEval benchmark, surpassing the baseline code generation approach by 32.7\%, demonstrating the effectiveness of our methods.
PAPI: Exploiting Dynamic Parallelism in Large Language Model Decoding with a Processing-In-Memory-Enabled Computing System
Feb 21, 2025Large language models (LLMs) are widely used for natural language understanding and text generation. An LLM model relies on a time-consuming step called LLM decoding to generate output tokens. Several prior works focus on improving the performance of LLM decoding using parallelism techniques, such as batching and speculative decoding. State-of-the-art LLM decoding has both compute-bound and memory-bound kernels. Some prior works statically identify and map these different kernels to a heterogeneous architecture consisting of both processing-in-memory (PIM) units and computation-centric accelerators. We observe that characteristics of LLM decoding kernels (e.g., whether or not a kernel is memory-bound) can change dynamically due to parameter changes to meet user and/or system demands, making (1) static kernel mapping to PIM units and computation-centric accelerators suboptimal, and (2) one-size-fits-all approach of designing PIM units inefficient due to a large degree of heterogeneity even in memory-bound kernels. In this paper, we aim to accelerate LLM decoding while considering the dynamically changing characteristics of the kernels involved. We propose PAPI (PArallel Decoding with PIM), a PIM-enabled heterogeneous architecture that exploits dynamic scheduling of compute-bound or memory-bound kernels to suitable hardware units. PAPI has two key mechanisms: (1) online kernel characterization to dynamically schedule kernels to the most suitable hardware units at runtime and (2) a PIM-enabled heterogeneous computing system that harmoniously orchestrates both computation-centric processing units and hybrid PIM units with different computing capabilities. Our experimental results on three broadly-used LLMs show that PAPI achieves 1.8$\times$ and 11.1$\times$ speedups over a state-of-the-art heterogeneous LLM accelerator and a state-of-the-art PIM-only LLM accelerator, respectively.
A Fully Hardware Implemented Accelerator Design in ReRAM Analog Computing without ADCs
Dec 27, 2024Emerging ReRAM-based accelerators process neural networks via analog Computing-in-Memory (CiM) for ultra-high energy efficiency. However, significant overhead in peripheral circuits and complex nonlinear activation modes constrain system energy efficiency improvements. This work explores the hardware implementation of the Sigmoid and SoftMax activation functions of neural networks with stochastically binarized neurons by utilizing sampled noise signals from ReRAM devices to achieve a stochastic effect. We propose a complete ReRAM-based Analog Computing Accelerator (RACA) that accelerates neural network computation by leveraging stochastically binarized neurons in combination with ReRAM crossbars. The novel circuit design removes significant sources of energy/area efficiency degradation, i.e., the Digital-to-Analog and Analog-to-Digital Converters (DACs and ADCs) as well as the components to explicitly calculate the activation functions. Experimental results show that our proposed design outperforms traditional architectures across all overall performance metrics without compromising inference accuracy.
OpenLS-DGF: An Adaptive Open-Source Dataset Generation Framework for Machine Learning Tasks in Logic Synthesis
Nov 16, 2024



This paper introduces OpenLS-DGF, an adaptive logic synthesis dataset generation framework, to enhance machine learning~(ML) applications within the logic synthesis process. Previous dataset generation flows were tailored for specific tasks or lacked integrated machine learning capabilities. While OpenLS-DGF supports various machine learning tasks by encapsulating the three fundamental steps of logic synthesis: Boolean representation, logic optimization, and technology mapping. It preserves the original information in both Verilog and machine-learning-friendly GraphML formats. The verilog files offer semi-customizable capabilities, enabling researchers to insert additional steps and incrementally refine the generated dataset. Furthermore, OpenLS-DGF includes an adaptive circuit engine that facilitates the final dataset management and downstream tasks. The generated OpenLS-D-v1 dataset comprises 46 combinational designs from established benchmarks, totaling over 966,000 Boolean circuits. OpenLS-D-v1 supports integrating new data features, making it more versatile for new challenges. This paper demonstrates the versatility of OpenLS-D-v1 through four distinct downstream tasks: circuit classification, circuit ranking, quality of results (QoR) prediction, and probability prediction. Each task is chosen to represent essential steps of logic synthesis, and the experimental results show the generated dataset from OpenLS-DGF achieves prominent diversity and applicability. The source code and datasets are available at https://github.com/Logic-Factory/ACE/blob/master/OpenLS-DGF/readme.md.
An Adaptive Open-Source Dataset Generation Framework for Machine Learning Tasks in Logic Synthesis
Nov 14, 2024This paper introduces an adaptive logic synthesis dataset generation framework designed to enhance machine learning applications within the logic synthesis process. Unlike previous dataset generation flows that were tailored for specific tasks or lacked integrated machine learning capabilities, the proposed framework supports a comprehensive range of machine learning tasks by encapsulating the three fundamental steps of logic synthesis: Boolean representation, logic optimization, and technology mapping. It preserves the original information in the intermediate files that can be stored in both Verilog and Graphmal format. Verilog files enable semi-customizability, allowing researchers to add steps and incrementally refine the generated dataset. The framework also includes an adaptive circuit engine to facilitate the loading of GraphML files for final dataset packaging and sub-dataset extraction. The generated OpenLS-D dataset comprises 46 combinational designs from established benchmarks, totaling over 966,000 Boolean circuits, with each design containing 21,000 circuits generated from 1000 synthesis recipes, including 7000 Boolean networks, 7000 ASIC netlists, and 7000 FPGA netlists. Furthermore, OpenLS-D supports integrating newly desired data features, making it more versatile for new challenges. The utility of OpenLS-D is demonstrated through four distinct downstream tasks: circuit classification, circuit ranking, quality of results (QoR) prediction, and probability prediction. Each task highlights different internal steps of logic synthesis, with the datasets extracted and relabeled from the OpenLS-D dataset using the circuit engine. The experimental results confirm the dataset's diversity and extensive applicability. The source code and datasets are available at https://github.com/Logic-Factory/ACE/blob/master/OpenLS-D/readme.md.
Boolean-aware Boolean Circuit Classification: A Comprehensive Study on Graph Neural Network
Nov 13, 2024Boolean circuit is a computational graph that consists of the dynamic directed graph structure and static functionality. The commonly used logic optimization and Boolean matching-based transformation can change the behavior of the Boolean circuit for its graph structure and functionality in logic synthesis. The graph structure-based Boolean circuit classification can be grouped into the graph classification task, however, the functionality-based Boolean circuit classification remains an open problem for further research. In this paper, we first define the proposed matching-equivalent class based on its ``Boolean-aware'' property. The Boolean circuits in the proposed class can be transformed into each other. Then, we present a commonly study framework based on graph neural network~(GNN) to analyze the key factors that can affect the Boolean-aware Boolean circuit classification. The empirical experiment results verify the proposed analysis, and it also shows the direction and opportunity to improve the proposed problem. The code and dataset will be released after acceptance.
IICPilot: An Intelligent Integrated Circuit Backend Design Framework Using Open EDA
Jul 17, 2024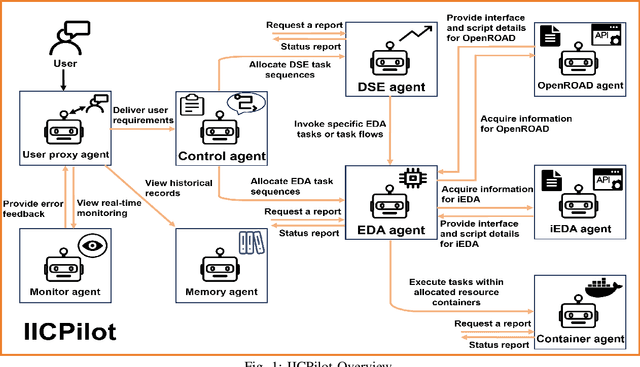

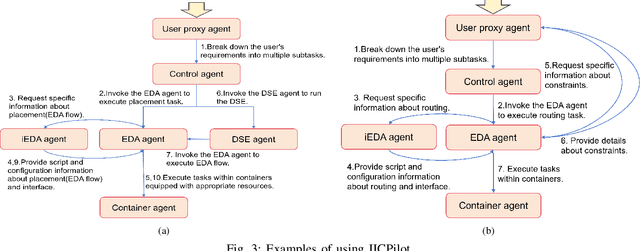

Open-source EDA tools are rapidly advancing, fostering collaboration, innovation, and knowledge sharing within the EDA community. However, the growing complexity of these tools, characterized by numerous design parameters and heuristics, poses a significant barrier to their widespread adoption. This complexity is particularly pronounced in integrated circuit (IC) backend designs, which place substantial demands on engineers' expertise in EDA tools. To tackle this challenge, we introduce IICPilot, an intelligent IC backend design system based on LLM technology. IICPilot automates various backend design procedures, including script generation, EDA tool invocation, design space exploration of EDA parameters, container-based computing resource allocation, and exception management. By automating these tasks, IICPilot significantly lowers the barrier to entry for open-source EDA tools. Specifically, IICPilot utilizes LangChain's multi-agent framework to efficiently handle distinct design tasks, enabling flexible enhancements independently. Moreover, IICPilot separates the backend design workflow from specific open-source EDA tools through a unified EDA calling interface. This approach allows seamless integration with different open-source EDA tools like OpenROAD and iEDA, streamlining the backend design and optimization across the EDA tools.
Natural language is not enough: Benchmarking multi-modal generative AI for Verilog generation
Jul 11, 2024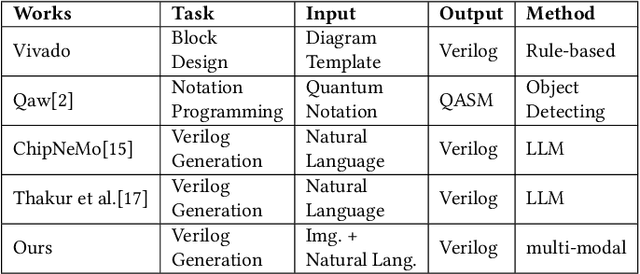
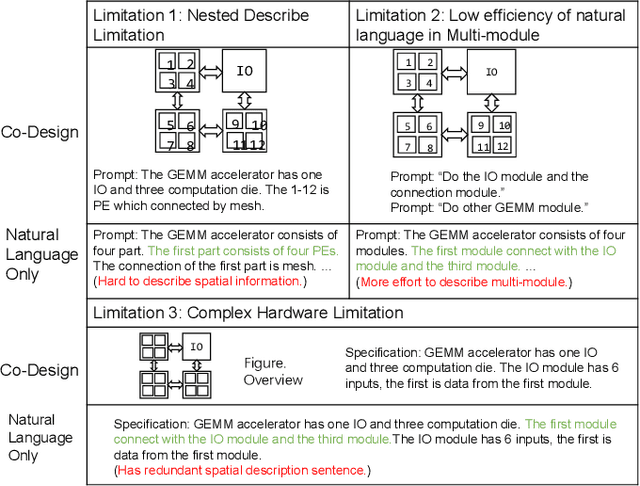
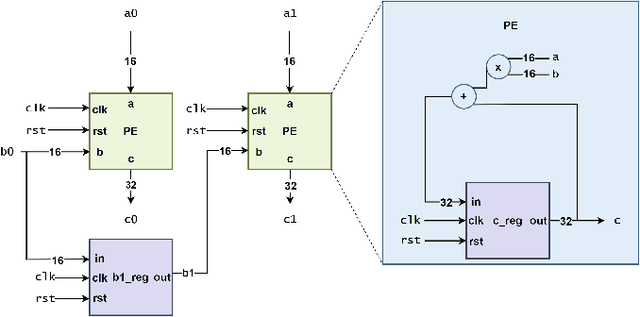
Natural language interfaces have exhibited considerable potential in the automation of Verilog generation derived from high-level specifications through the utilization of large language models, garnering significant attention. Nevertheless, this paper elucidates that visual representations contribute essential contextual information critical to design intent for hardware architectures possessing spatial complexity, potentially surpassing the efficacy of natural-language-only inputs. Expanding upon this premise, our paper introduces an open-source benchmark for multi-modal generative models tailored for Verilog synthesis from visual-linguistic inputs, addressing both singular and complex modules. Additionally, we introduce an open-source visual and natural language Verilog query language framework to facilitate efficient and user-friendly multi-modal queries. To evaluate the performance of the proposed multi-modal hardware generative AI in Verilog generation tasks, we compare it with a popular method that relies solely on natural language. Our results demonstrate a significant accuracy improvement in the multi-modal generated Verilog compared to queries based solely on natural language. We hope to reveal a new approach to hardware design in the large-hardware-design-model era, thereby fostering a more diversified and productive approach to hardware design.