 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopoHR: Hierarchical Centerline Representation for Cyclic Topology Reasoning in Driving Scenes with Point-to-Instance Relations
Apr 27, 2026Topology reasoning is crucial for autonomous driving. Current methods primarily focus on instance-level learning for centerline detection, followed by a sequential module for topology reasoning that relies on simplified MLP layers. Moreover, they often neglect the importance of \textit{point-to-instance} (P2I) relationships in topology reasoning. To address these limitations, we present TopoHR (Topological Hierarchical Representation), a novel end-to-end framework that establishes cyclic interaction between centerline detection and topology reasoning, allowing them to iteratively enhance each other. Specifically, we introduce a hierarchical centerline representation including point queries, instance queries, and semantic representations. These multi-level features are seamlessly integrated and fused within a hierarchical centerline decoder. Furthermore, we design a hierarchical topology reasoning module that captures both fine-grained P2I relationships and global instance-to-instance (I2I) connections within a unified architecture. With these novel components, TopoHR ensures accurate and robust topology reasoning. On the OpenLane-V2 benchmark, TopoHR refreshes state-of-the-art performance with significant improvements. Notably, compared with previous best results, TopoHR achieves +3.8 in $\mathrm{DET}_{\text{l}}$, +5.4 in $\mathrm{TOP}_{\text{ll}}$ on $\text{subset_A}$ and +11.0 in $\mathrm{DET}_{\text{l}}$, +7.9 in $\mathrm{TOP}_{\text{ll}}$ on $\text{subset_B}$, validating the effectiveness of the proposed components. The code will be shared publicly at https://github.com/Yifeng-Bai/TopoHR.git.
TriMoE: Augmenting GPU with AMX-Enabled CPU and DIMM-NDP for High-Throughput MoE Inference via Offloading
Mar 01, 2026To deploy large Mixture-of-Experts (MoE) models cost-effectively, offloading-based single-GPU heterogeneous inference is crucial. While GPU-CPU architectures that offload cold experts are constrained by host memory bandwidth, emerging GPU-NDP architectures utilize DIMM-NDP to offload non-hot experts. However, non-hot experts are not a homogeneous memory-bound group: a significant subset of warm experts exists is severely penalized by high GPU I/O latency yet can saturate NDP compute throughput, exposing a critical compute gap. We present TriMoE, a novel GPU-CPU-NDP architecture that fills this gap by synergistically leveraging AMX-enabled CPU to precisely map hot, warm, and cold experts onto their optimal compute units. We further introduce a bottleneck-aware expert scheduling policy and a prediction-driven dynamic relayout/rebalancing scheme. Experiments demonstrate that TriMoE achieves up to 2.83x speedup over state-of-the-art solutions.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
LLaTTE: Scaling Laws for Multi-Stage Sequence Modeling in Large-Scale Ads Recommendation
Jan 27, 2026We present LLaTTE (LLM-Style Latent Transformers for Temporal Events), a scalable transformer architecture for production ads recommendation. Through systematic experiments, we demonstrate that sequence modeling in recommendation systems follows predictable power-law scaling similar to LLMs. Crucially, we find that semantic features bend the scaling curve: they are a prerequisite for scaling, enabling the model to effectively utilize the capacity of deeper and longer architectures. To realize the benefits of continued scaling under strict latency constraints, we introduce a two-stage architecture that offloads the heavy computation of large, long-context models to an asynchronous upstream user model. We demonstrate that upstream improvements transfer predictably to downstream ranking tasks. Deployed as the largest user model at Meta, this multi-stage framework drives a 4.3\% conversion uplift on Facebook Feed and Reels with minimal serving overhead, establishing a practical blueprint for harnessing scaling laws in industrial recommender systems.
Natural language is not enough: Benchmarking multi-modal generative AI for Verilog generation
Jul 11, 2024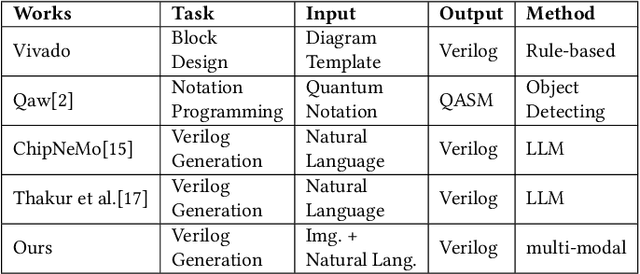
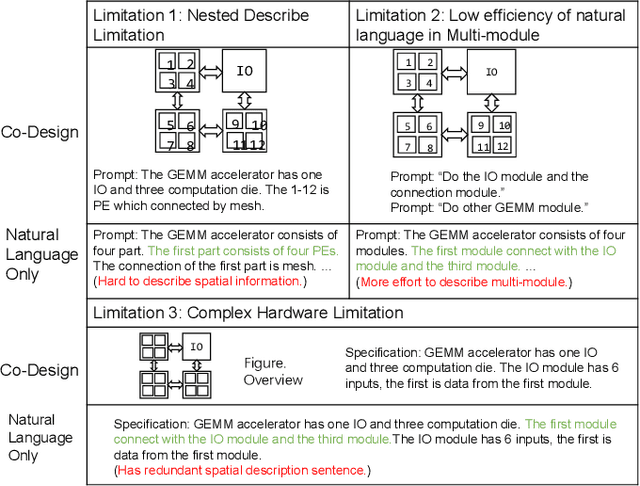
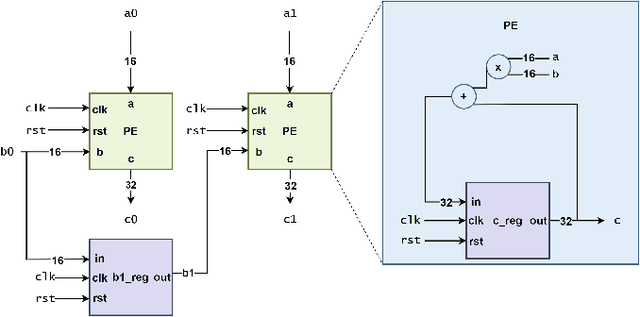
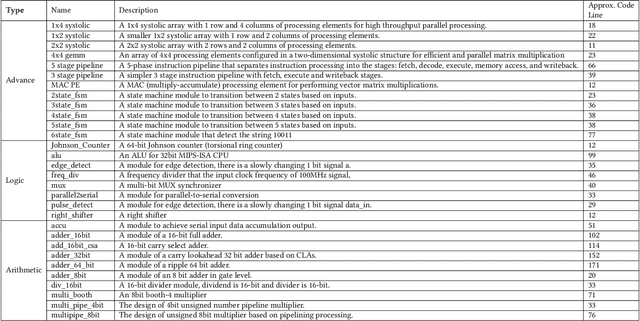
Natural language interfaces have exhibited considerable potential in the automation of Verilog generation derived from high-level specifications through the utilization of large language models, garnering significant attention. Nevertheless, this paper elucidates that visual representations contribute essential contextual information critical to design intent for hardware architectures possessing spatial complexity, potentially surpassing the efficacy of natural-language-only inputs. Expanding upon this premise, our paper introduces an open-source benchmark for multi-modal generative models tailored for Verilog synthesis from visual-linguistic inputs, addressing both singular and complex modules. Additionally, we introduce an open-source visual and natural language Verilog query language framework to facilitate efficient and user-friendly multi-modal queries. To evaluate the performance of the proposed multi-modal hardware generative AI in Verilog generation tasks, we compare it with a popular method that relies solely on natural language. Our results demonstrate a significant accuracy improvement in the multi-modal generated Verilog compared to queries based solely on natural language. We hope to reveal a new approach to hardware design in the large-hardware-design-model era, thereby fostering a more diversified and productive approach to hardware design.
Data is all you need: Finetuning LLMs for Chip Design via an Automated design-data augmentation framework
Mar 17, 2024
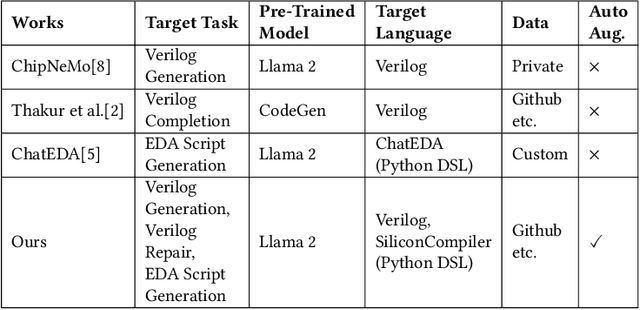


Recent advances in large language models have demonstrated their potential for automated generation of hardware description language (HDL) code from high-level prompts. Researchers have utilized fine-tuning to enhance the ability of these large language models (LLMs) in the field of Chip Design. However, the lack of Verilog data hinders further improvement in the quality of Verilog generation by LLMs. Additionally, the absence of a Verilog and Electronic Design Automation (EDA) script data augmentation framework significantly increases the time required to prepare the training dataset for LLM trainers. This paper proposes an automated design-data augmentation framework, which generates high-volume and high-quality natural language aligned with Verilog and EDA scripts. For Verilog generation, it translates Verilog files to an abstract syntax tree and then maps nodes to natural language with a predefined template. For Verilog repair, it uses predefined rules to generate the wrong verilog file and then pairs EDA Tool feedback with the right and wrong verilog file. For EDA Script generation, it uses existing LLM(GPT-3.5) to obtain the description of the Script. To evaluate the effectiveness of our data augmentation method, we finetune Llama2-13B and Llama2-7B models using the dataset generated by our augmentation framework. The results demonstrate a significant improvement in the Verilog generation tasks with LLMs. Moreover, the accuracy of Verilog generation surpasses that of the current state-of-the-art open-source Verilog generation model, increasing from 58.8% to 70.6% with the same benchmark. Our 13B model (ChipGPT-FT) has a pass rate improvement compared with GPT-3.5 in Verilog generation and outperforms in EDA script (i.e., SiliconCompiler) generation with only 200 EDA script data.
CurveFormer++: 3D Lane Detection by Curve Propagation with Temporal Curve Queries and Attention
Feb 09, 2024In autonomous driving, 3D lane detection using monocular cameras is an important task for various downstream planning and control tasks. Recent CNN and Transformer approaches usually apply a two-stage scheme in the model design. The first stage transforms the image feature from a front image into a bird's-eye-view (BEV) representation. Subsequently, a sub-network processes the BEV feature map to generate the 3D detection results. However, these approaches heavily rely on a challenging image feature transformation module from a perspective view to a BEV representation. In our work, we present CurveFormer++, a single-stage Transformer-based method that does not require the image feature view transform module and directly infers 3D lane detection results from the perspective image features. Specifically, our approach models the 3D detection task as a curve propagation problem, where each lane is represented by a curve query with a dynamic and ordered anchor point set. By employing a Transformer decoder, the model can iteratively refine the 3D lane detection results. A curve cross-attention module is introduced in the Transformer decoder to calculate similarities between image features and curve queries of lanes. To handle varying lane lengths, we employ context sampling and anchor point restriction techniques to compute more relevant image features for a curve query. Furthermore, we apply a temporal fusion module that incorporates selected informative sparse curve queries and their corresponding anchor point sets to leverage historical lane information. In the experiments, we evaluate our approach for the 3D lane detection task on two publicly available real-world datasets. The results demonstrate that our method provides outstanding performance compared with both CNN and Transformer based methods. We also conduct ablation studies to analyze the impact of each component in our approach.
CurveFormer: 3D Lane Detection by Curve Propagation with Curve Queries and Attention
Sep 16, 2022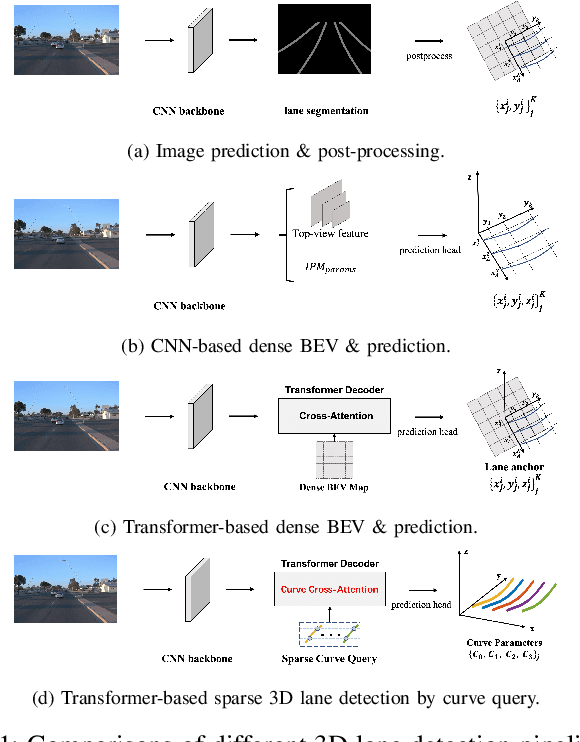
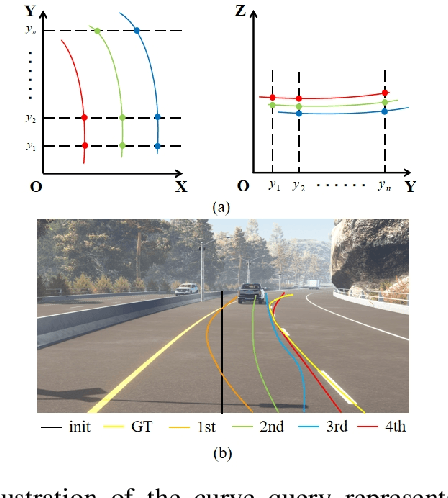
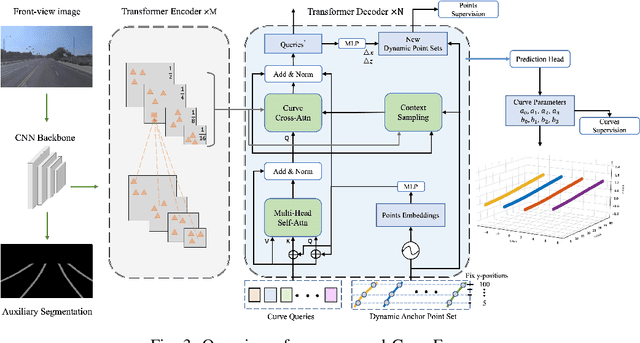
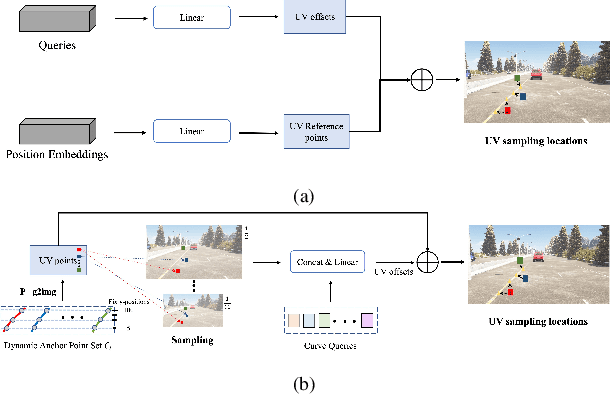
3D lane detection is an integral part of autonomous driving systems. Previous CNN and Transformer-based methods usually first generate a bird's-eye-view (BEV) feature map from the front view image, and then use a sub-network with BEV feature map as input to predict 3D lanes. Such approaches require an explicit view transformation between BEV and front view, which itself is still a challenging problem. In this paper, we propose CurveFormer, a single-stage Transformer-based method that directly calculates 3D lane parameters and can circumvent the difficult view transformation step. Specifically, we formulate 3D lane detection as a curve propagation problem by using curve queries. A 3D lane query is represented by a dynamic and ordered anchor point set. In this way, queries with curve representation in Transformer decoder iteratively refine the 3D lane detection results. Moreover, a curve cross-attention module is introduced to compute the similarities between curve queries and image features. Additionally, a context sampling module that can capture more relative image features of a curve query is provided to further boost the 3D lane detection performance. We evaluate our method for 3D lane detection on both synthetic and real-world datasets, and the experimental results show that our method achieves promising performance compared with the state-of-the-art approaches. The effectiveness of each component is validated via ablation studies as well.
BEVSegFormer: Bird's Eye View Semantic Segmentation From Arbitrary Camera Rigs
Mar 13, 2022


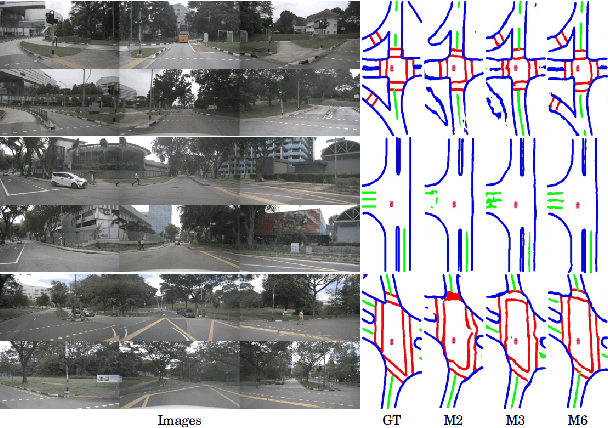
Semantic segmentation in bird's eye view (BEV) is an important task for autonomous driving. Though this task has attracted a large amount of research efforts, it is still challenging to flexibly cope with arbitrary (single or multiple) camera sensors equipped on the autonomous vehicle. In this paper, we present BEVSegFormer, an effective transformer-based method for BEV semantic segmentation from arbitrary camera rigs. Specifically, our method first encodes image features from arbitrary cameras with a shared backbone. These image features are then enhanced by a deformable transformer-based encoder. Moreover, we introduce a BEV transformer decoder module to parse BEV semantic segmentation results. An efficient multi-camera deformable attention unit is designed to carry out the BEV-to-image view transformation. Finally, the queries are reshaped according the layout of grids in the BEV, and upsampled to produce the semantic segmentation result in a supervised manner. We evaluate the proposed algorithm on the public nuScenes dataset and a self-collected dataset. Experimental results show that our method achieves promising performance on BEV semantic segmentation from arbitrary camera rigs. We also demonstrate the effectiveness of each component via ablation study.