 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopoHR: Hierarchical Centerline Representation for Cyclic Topology Reasoning in Driving Scenes with Point-to-Instance Relations
Apr 27, 2026Topology reasoning is crucial for autonomous driving. Current methods primarily focus on instance-level learning for centerline detection, followed by a sequential module for topology reasoning that relies on simplified MLP layers. Moreover, they often neglect the importance of \textit{point-to-instance} (P2I) relationships in topology reasoning. To address these limitations, we present TopoHR (Topological Hierarchical Representation), a novel end-to-end framework that establishes cyclic interaction between centerline detection and topology reasoning, allowing them to iteratively enhance each other. Specifically, we introduce a hierarchical centerline representation including point queries, instance queries, and semantic representations. These multi-level features are seamlessly integrated and fused within a hierarchical centerline decoder. Furthermore, we design a hierarchical topology reasoning module that captures both fine-grained P2I relationships and global instance-to-instance (I2I) connections within a unified architecture. With these novel components, TopoHR ensures accurate and robust topology reasoning. On the OpenLane-V2 benchmark, TopoHR refreshes state-of-the-art performance with significant improvements. Notably, compared with previous best results, TopoHR achieves +3.8 in $\mathrm{DET}_{\text{l}}$, +5.4 in $\mathrm{TOP}_{\text{ll}}$ on $\text{subset_A}$ and +11.0 in $\mathrm{DET}_{\text{l}}$, +7.9 in $\mathrm{TOP}_{\text{ll}}$ on $\text{subset_B}$, validating the effectiveness of the proposed components. The code will be shared publicly at https://github.com/Yifeng-Bai/TopoHR.git.
CurveFormer++: 3D Lane Detection by Curve Propagation with Temporal Curve Queries and Attention
Feb 09, 2024In autonomous driving, 3D lane detection using monocular cameras is an important task for various downstream planning and control tasks. Recent CNN and Transformer approaches usually apply a two-stage scheme in the model design. The first stage transforms the image feature from a front image into a bird's-eye-view (BEV) representation. Subsequently, a sub-network processes the BEV feature map to generate the 3D detection results. However, these approaches heavily rely on a challenging image feature transformation module from a perspective view to a BEV representation. In our work, we present CurveFormer++, a single-stage Transformer-based method that does not require the image feature view transform module and directly infers 3D lane detection results from the perspective image features. Specifically, our approach models the 3D detection task as a curve propagation problem, where each lane is represented by a curve query with a dynamic and ordered anchor point set. By employing a Transformer decoder, the model can iteratively refine the 3D lane detection results. A curve cross-attention module is introduced in the Transformer decoder to calculate similarities between image features and curve queries of lanes. To handle varying lane lengths, we employ context sampling and anchor point restriction techniques to compute more relevant image features for a curve query. Furthermore, we apply a temporal fusion module that incorporates selected informative sparse curve queries and their corresponding anchor point sets to leverage historical lane information. In the experiments, we evaluate our approach for the 3D lane detection task on two publicly available real-world datasets. The results demonstrate that our method provides outstanding performance compared with both CNN and Transformer based methods. We also conduct ablation studies to analyze the impact of each component in our approach.
CurveFormer: 3D Lane Detection by Curve Propagation with Curve Queries and Attention
Sep 16, 2022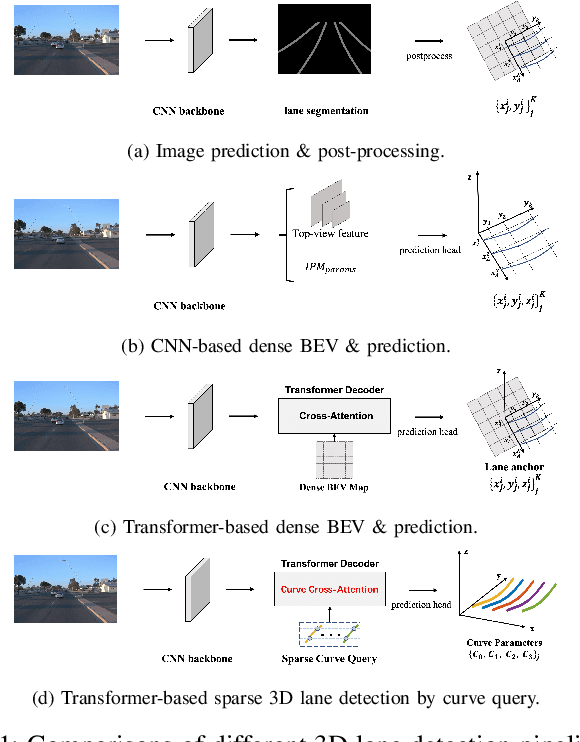
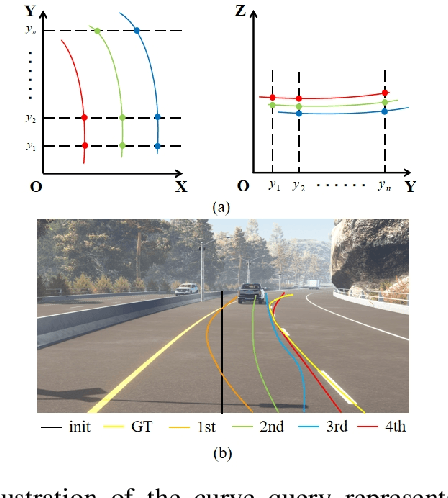
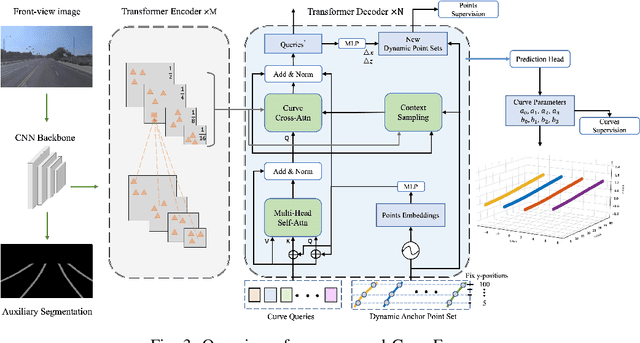
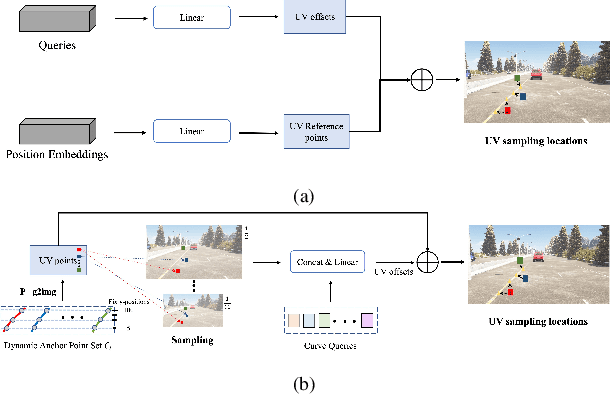
3D lane detection is an integral part of autonomous driving systems. Previous CNN and Transformer-based methods usually first generate a bird's-eye-view (BEV) feature map from the front view image, and then use a sub-network with BEV feature map as input to predict 3D lanes. Such approaches require an explicit view transformation between BEV and front view, which itself is still a challenging problem. In this paper, we propose CurveFormer, a single-stage Transformer-based method that directly calculates 3D lane parameters and can circumvent the difficult view transformation step. Specifically, we formulate 3D lane detection as a curve propagation problem by using curve queries. A 3D lane query is represented by a dynamic and ordered anchor point set. In this way, queries with curve representation in Transformer decoder iteratively refine the 3D lane detection results. Moreover, a curve cross-attention module is introduced to compute the similarities between curve queries and image features. Additionally, a context sampling module that can capture more relative image features of a curve query is provided to further boost the 3D lane detection performance. We evaluate our method for 3D lane detection on both synthetic and real-world datasets, and the experimental results show that our method achieves promising performance compared with the state-of-the-art approaches. The effectiveness of each component is validated via ablation studies as well.