 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlpha-RTL: Test-Time Training for RTL Hardware Optimization
Jun 03, 2026Large language models (LLMs) have shown increasing promise in generating functionally correct register-transfer-level (RTL) hardware designs. Recent systems improve further through EDA-integrated reinforcement learning with syntax, simulation, and PPA rewards, but train a general RTL generator before deployment while test-time approaches search with a frozen policy. We instead perform reinforcement learning at test time, allowing the LLM policy to adapt to executable EDA feedback for the specific RTL problem at hand. We propose TTT-RTL, to our knowledge the first per-design test-time training framework that closes the loop between an LLM policy and an EDA pipeline for RTL optimization. TTT-RTL samples candidate implementations, verifies them through syntax checking and simulation, scores valid designs using synthesis-derived PPA product, reuses high-reward variants through a PUCT-indexed design-state pool, and updates the policy with an entropic policy-gradient objective. To stabilize policy updates under sparse or plateaued rewards, we introduce an adaptive KL-budget controller that adjusts the entropy constraint using reference KL, effective sample size, and reward saturation signals. On RTLLM v2.0 under Nangate 45nm, TTT-RTL reduces the geometric-mean PPA product by 65.1% over the reference, outperforming the strongest published frozen-policy agent baseline at 26.1%. On an industrial XuanTie C910 FPU leading-zero-anticipation unit under Sky130, TTT-RTL achieves a 59.4% ADP reduction, and ablations confirm that policy adaptation, state reuse, and KL-budget control each contribute. These results suggest that test-time training with executable EDA feedback can move LLM-based RTL generation beyond functional correctness toward physically optimized hardware.
RouteLMT: Learned Sample Routing for Hybrid LLM Translation Deployment
Apr 24, 2026Large Language Models (LLMs) have achieved remarkable performance in Machine Translation (MT), but deploying them at scale remains prohibitively expensive. A widely adopted remedy is the hybrid system paradigm, which balances cost and quality by serving most requests with a small model and selectively routing a fraction to a large model. However, existing routing strategies often rely on heuristics, external predictors, or absolute quality estimation, which fail to capture whether the large model actually provides a worthwhile improvement over the small one. In this paper, we formulate routing as a budget allocation problem and identify marginal gain, i.e., the large model's improvement over the small model, as the optimal signal for budgeted decisions. Building on this, we propose \textbf{RouteLMT} (routing for LLM-based MT), an efficient in-model router that predicts this expected gain by probing the small translators prompt-token representation, without requiring external models or hypothesis decoding. Extensive experiments demonstrate that our RouteLMT outperforms heuristics, quality/difficulty estimation baselines, achieving a superior quality-budget Pareto frontier. Furthermore, we analyze regression risks and show that a simple guarded variant can mitigate severe quality losses.
When Scaling Fails: Mitigating Audio Perception Decay of LALMs via Multi-Step Perception-Aware Reasoning
Feb 28, 2026Test-Time Scaling has shown notable efficacy in addressing complex problems through scaling inference compute. However, within Large Audio-Language Models (LALMs), an unintuitive phenomenon exists: post-training models for structured reasoning trajectories results in marginal or even negative gains compared to post-training for direct answering. To investigate it, we introduce CAFE, an evaluation framework designed to precisely quantify audio reasoning errors. Evaluation results reveal LALMs struggle with perception during reasoning and encounter a critical bottleneck: reasoning performance suffers from audio perception decay as reasoning length extends. To address it, we propose MPAR$^2$, a paradigm that encourages dynamic perceptual reasoning and decomposes complex questions into perception-rich sub-problems. Leveraging reinforcement learning, MPAR$^2$ improves perception performance on CAFE from 31.74% to 63.51% and effectively mitigates perception decay, concurrently enhancing reasoning capabilities to achieve a significant 74.59% accuracy on the MMAU benchmark. Further analysis demonstrates that MPAR$^2$ reinforces LALMs to attend to audio input and dynamically adapts reasoning budget to match task complexity.
APR: Penalizing Structural Redundancy in Large Reasoning Models via Anchor-based Process Rewards
Jan 31, 2026Test-Time Scaling (TTS) has significantly enhanced the capabilities of Large Reasoning Models (LRMs) but introduces a critical side-effect known as Overthinking. We conduct a preliminary study to rethink this phenomenon from a fine-grained perspective. We observe that LRMs frequently conduct repetitive self-verification without revision even after obtaining the final answer during the reasoning process. We formally define this specific position where the answer first stabilizes as the Reasoning Anchor. By analyzing pre- and post-anchor reasoning behaviors, we uncover the structural redundancy fixed in LRMs: the meaningless repetitive verification after deriving the first complete answer, which we term the Answer-Stable Tail (AST). Motivated by this observation, we propose Anchor-based Process Reward (APR), a structure-aware reward shaping method that localizes the reasoning anchor and penalizes exclusively the post-anchor AST. Leveraging the policy optimization algorithm suitable for length penalties, our APR models achieved the performance-efficiency Pareto frontier at 1.5B and 7B scales averaged across five mathematical reasoning datasets while requiring significantly fewer computational resources for RL training.
Beyond English: Toward Inclusive and Scalable Multilingual Machine Translation with LLMs
Nov 10, 2025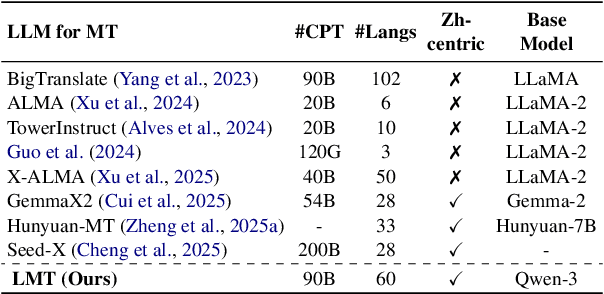
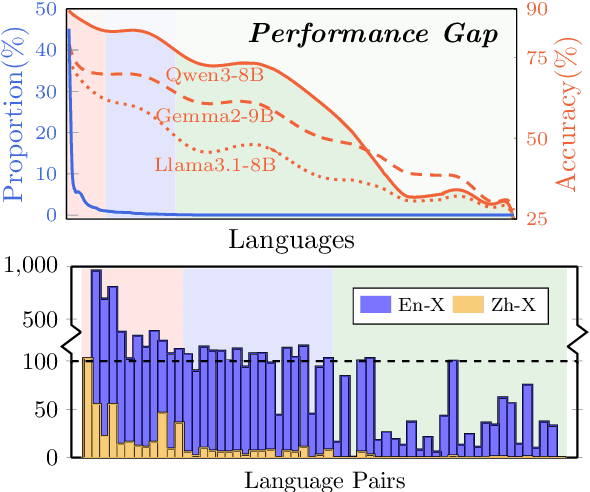
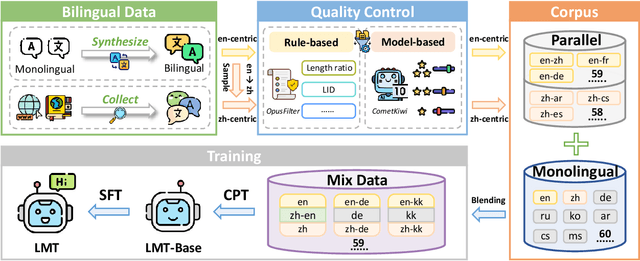
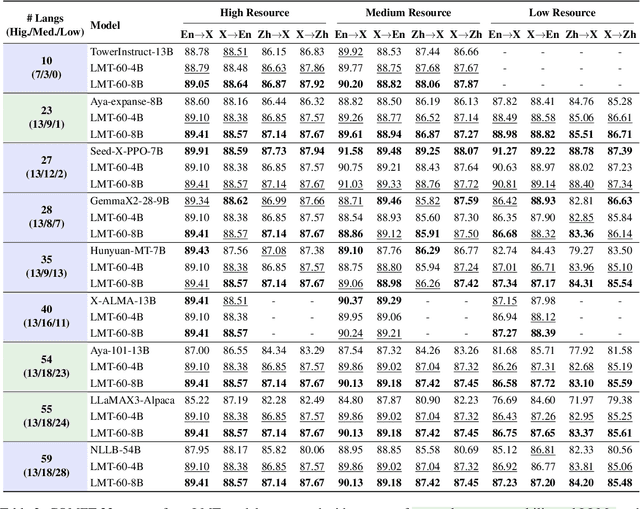
Large language models have significantly advanced Multilingual Machine Translation (MMT), yet the broad language coverage, consistent translation quality, and English-centric bias remain open challenges. To address these challenges, we introduce \textbf{LMT}, a suite of \textbf{L}arge-scale \textbf{M}ultilingual \textbf{T}ranslation models centered on both Chinese and English, covering 60 languages and 234 translation directions. During development, we identify a previously overlooked phenomenon of \textbf{directional degeneration}, where symmetric multi-way fine-tuning data overemphasize reverse directions (X $\to$ En/Zh), leading to excessive many-to-one mappings and degraded translation quality. We propose \textbf{Strategic Downsampling}, a simple yet effective method to mitigate this degeneration. In addition, we design \textbf{Parallel Multilingual Prompting (PMP)}, which leverages typologically related auxiliary languages to enhance cross-lingual transfer. Through rigorous data curation and refined adaptation strategies, LMT achieves SOTA performance among models of comparable language coverage, with our 4B model (LMT-60-4B) surpassing the much larger Aya-101-13B and NLLB-54B models by a substantial margin. We release LMT in four sizes (0.6B/1.7B/4B/8B) to catalyze future research and provide strong baselines for inclusive, scalable, and high-quality MMT \footnote{\href{https://github.com/NiuTrans/LMT}{https://github.com/NiuTrans/LMT}}.
SUBQRAG: sub-question driven dynamic graph rag
Oct 09, 2025Graph Retrieval-Augmented Generation (Graph RAG) effectively builds a knowledge graph (KG) to connect disparate facts across a large document corpus. However, this broad-view approach often lacks the deep structured reasoning needed for complex multi-hop question answering (QA), leading to incomplete evidence and error accumulation. To address these limitations, we propose SubQRAG, a sub-question-driven framework that enhances reasoning depth. SubQRAG decomposes a complex question into an ordered chain of verifiable sub-questions. For each sub-question, it retrieves relevant triples from the graph. When the existing graph is insufficient, the system dynamically expands it by extracting new triples from source documents in real time. All triples used in the reasoning process are aggregated into a "graph memory," forming a structured and traceable evidence path for final answer generation. Experiments on three multi-hop QA benchmarks demonstrate that SubQRAG achieves consistent and significant improvements, especially in Exact Match scores.
One Size Does Not Fit All: A Distribution-Aware Sparsification for More Precise Model Merging
Aug 08, 2025Model merging has emerged as a compelling data-free paradigm for multi-task learning, enabling the fusion of multiple fine-tuned models into a single, powerful entity. A key technique in merging methods is sparsification, which prunes redundant parameters from task vectors to mitigate interference. However, prevailing approaches employ a ``one-size-fits-all'' strategy, applying a uniform sparsity ratio that overlooks the inherent structural and statistical heterogeneity of model parameters. This often leads to a suboptimal trade-off, where critical parameters are inadvertently pruned while less useful ones are retained. To address this limitation, we introduce \textbf{TADrop} (\textbf{T}ensor-wise \textbf{A}daptive \textbf{Drop}), an adaptive sparsification strategy that respects this heterogeneity. Instead of a global ratio, TADrop assigns a tailored sparsity level to each parameter tensor based on its distributional properties. The core intuition is that tensors with denser, more redundant distributions can be pruned aggressively, while sparser, more critical ones are preserved. As a simple and plug-and-play module, we validate TADrop by integrating it with foundational, classic, and SOTA merging methods. Extensive experiments across diverse tasks (vision, language, and multimodal) and models (ViT, BEiT) demonstrate that TADrop consistently and significantly boosts their performance. For instance, when enhancing a leading merging method, it achieves an average performance gain of 2.0\% across 8 ViT-B/32 tasks. TADrop provides a more effective way to mitigate parameter interference by tailoring sparsification to the model's structure, offering a new baseline for high-performance model merging.
RTLMarker: Protecting LLM-Generated RTL Copyright via a Hardware Watermarking Framework
Jan 05, 2025



Recent advances of large language models in the field of Verilog generation have raised several ethical and security concerns, such as code copyright protection and dissemination of malicious code. Researchers have employed watermarking techniques to identify codes generated by large language models. However, the existing watermarking works fail to protect RTL code copyright due to the significant syntactic and semantic differences between RTL code and software code in languages such as Python. This paper proposes a hardware watermarking framework RTLMarker that embeds watermarks into RTL code and deeper into the synthesized netlist. We propose a set of rule-based Verilog code transformations , ensuring the watermarked RTL code's syntactic and semantic correctness. In addition, we consider an inherent tradeoff between watermark transparency and watermark effectiveness and jointly optimize them. The results demonstrate RTLMarker's superiority over the baseline in RTL code watermarking.
Natural language is not enough: Benchmarking multi-modal generative AI for Verilog generation
Jul 11, 2024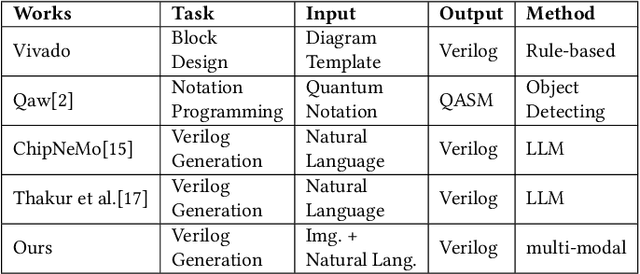
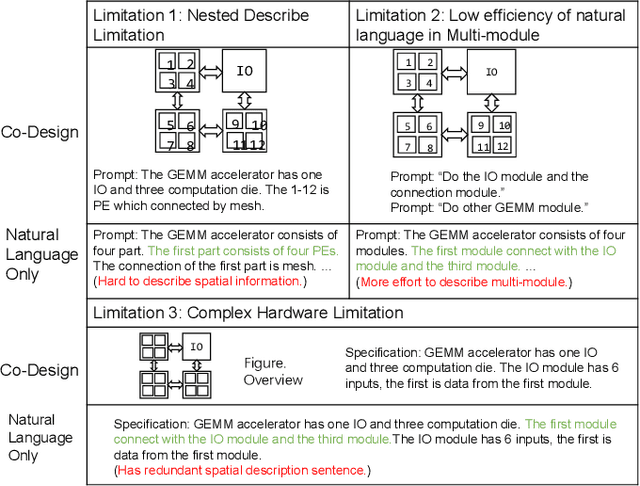
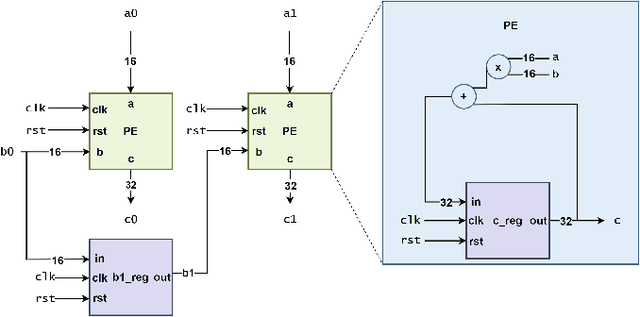
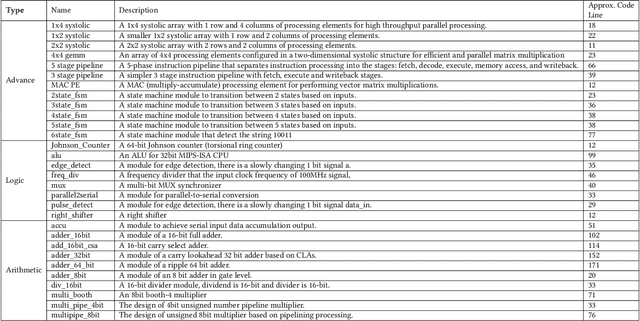
Natural language interfaces have exhibited considerable potential in the automation of Verilog generation derived from high-level specifications through the utilization of large language models, garnering significant attention. Nevertheless, this paper elucidates that visual representations contribute essential contextual information critical to design intent for hardware architectures possessing spatial complexity, potentially surpassing the efficacy of natural-language-only inputs. Expanding upon this premise, our paper introduces an open-source benchmark for multi-modal generative models tailored for Verilog synthesis from visual-linguistic inputs, addressing both singular and complex modules. Additionally, we introduce an open-source visual and natural language Verilog query language framework to facilitate efficient and user-friendly multi-modal queries. To evaluate the performance of the proposed multi-modal hardware generative AI in Verilog generation tasks, we compare it with a popular method that relies solely on natural language. Our results demonstrate a significant accuracy improvement in the multi-modal generated Verilog compared to queries based solely on natural language. We hope to reveal a new approach to hardware design in the large-hardware-design-model era, thereby fostering a more diversified and productive approach to hardware design.
Hybrid Alignment Training for Large Language Models
Jun 21, 2024
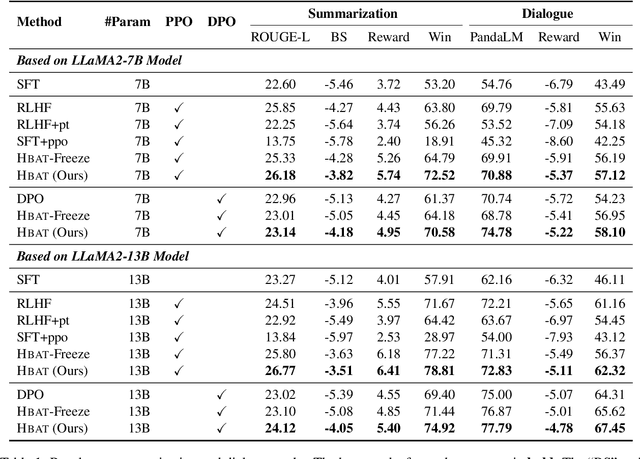
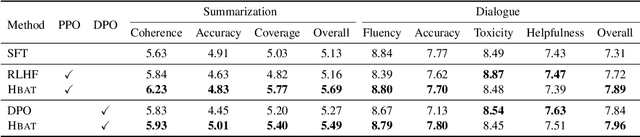
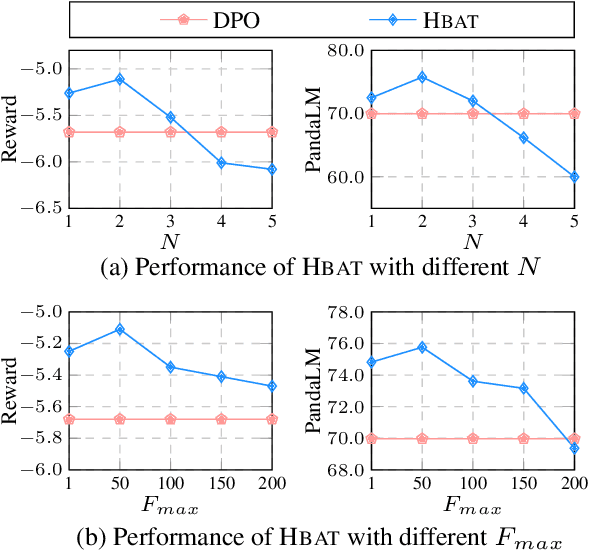
Alignment training is crucial for enabling large language models (LLMs) to cater to human intentions and preferences. It is typically performed based on two stages with different objectives: instruction-following alignment and human-preference alignment. However, aligning LLMs with these objectives in sequence suffers from an inherent problem: the objectives may conflict, and the LLMs cannot guarantee to simultaneously align with the instructions and human preferences well. To response to these, in this work, we propose a Hybrid Alignment Training (Hbat) approach, based on alternating alignment and modified elastic weight consolidation methods. The basic idea is to alternate between different objectives during alignment training, so that better collaboration can be achieved between the two alignment tasks.We experiment with Hbat on summarization and dialogue tasks. Experimental results show that the proposed \textsc{Hbat} can significantly outperform all baselines. Notably, Hbat yields consistent performance gains over the traditional two-stage alignment training when using both proximal policy optimization and direct preference optimization.