 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Alignment Training for Large Language Models
Paper and Code

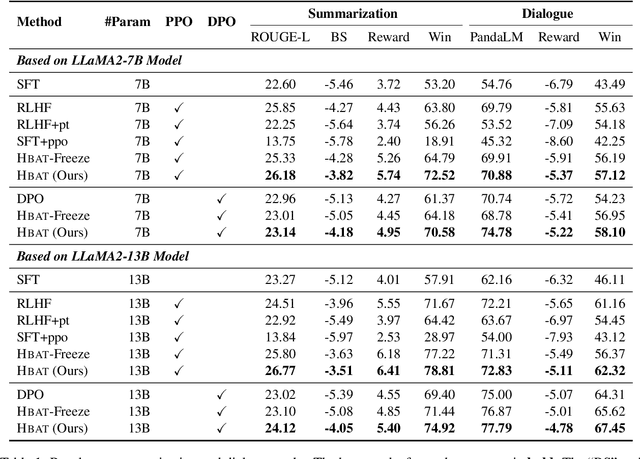
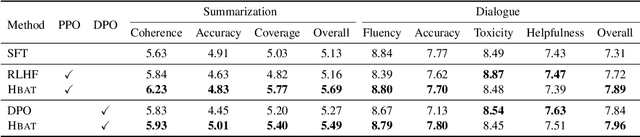
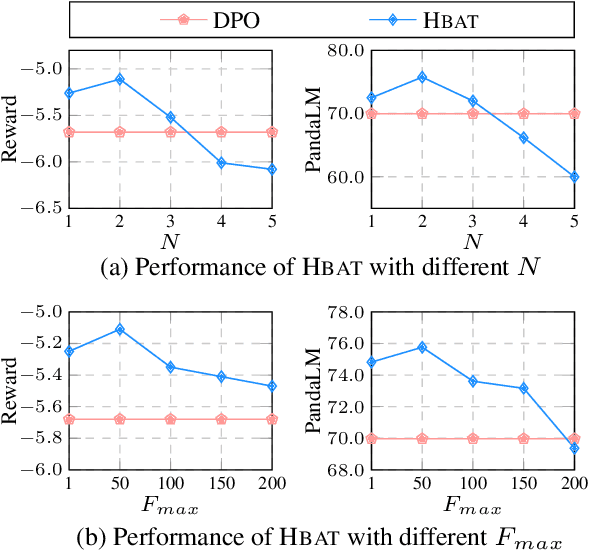
Alignment training is crucial for enabling large language models (LLMs) to cater to human intentions and preferences. It is typically performed based on two stages with different objectives: instruction-following alignment and human-preference alignment. However, aligning LLMs with these objectives in sequence suffers from an inherent problem: the objectives may conflict, and the LLMs cannot guarantee to simultaneously align with the instructions and human preferences well. To response to these, in this work, we propose a Hybrid Alignment Training (Hbat) approach, based on alternating alignment and modified elastic weight consolidation methods. The basic idea is to alternate between different objectives during alignment training, so that better collaboration can be achieved between the two alignment tasks.We experiment with Hbat on summarization and dialogue tasks. Experimental results show that the proposed \textsc{Hbat} can significantly outperform all baselines. Notably, Hbat yields consistent performance gains over the traditional two-stage alignment training when using both proximal policy optimization and direct preference optimization.