 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Layer Optimization for Fault-Tolerant Deep Learning
Dec 21, 2023Fault-tolerant deep learning accelerator is the basis for highly reliable deep learning processing and critical to deploy deep learning in safety-critical applications such as avionics and robotics. Since deep learning is known to be computing- and memory-intensive, traditional fault-tolerant approaches based on redundant computing will incur substantial overhead including power consumption and chip area. To this end, we propose to characterize deep learning vulnerability difference across both neurons and bits of each neuron, and leverage the vulnerability difference to enable selective protection of the deep learning processing components from the perspective of architecture layer and circuit layer respectively. At the same time, we observe the correlation between model quantization and bit protection overhead of the underlying processing elements of deep learning accelerators, and propose to reduce the bit protection overhead by adding additional quantization constrain without compromising the model accuracy. Finally, we employ Bayesian optimization strategy to co-optimize the correlated cross-layer design parameters at algorithm layer, architecture layer, and circuit layer to minimize the hardware resource consumption while fulfilling multiple user constraints including reliability, accuracy, and performance of the deep learning processing at the same time.
Exploring Winograd Convolution for Cost-effective Neural Network Fault Tolerance
Aug 16, 2023



Winograd is generally utilized to optimize convolution performance and computational efficiency because of the reduced multiplication operations, but the reliability issues brought by winograd are usually overlooked. In this work, we observe the great potential of winograd convolution in improving neural network (NN) fault tolerance. Based on the observation, we evaluate winograd convolution fault tolerance comprehensively from different granularities ranging from models, layers, and operation types for the first time. Then, we explore the use of inherent fault tolerance of winograd convolution for cost-effective NN protection against soft errors. Specifically, we mainly investigate how winograd convolution can be effectively incorporated with classical fault-tolerant design approaches including triple modular redundancy (TMR), fault-aware retraining, and constrained activation functions. According to our experiments, winograd convolution can reduce the fault-tolerant design overhead by 55.77\% on average without any accuracy loss compared to standard convolution, and further reduce the computing overhead by 17.24\% when the inherent fault tolerance of winograd convolution is considered. When it is applied on fault-tolerant neural networks enhanced with fault-aware retraining and constrained activation functions, the resulting model accuracy generally shows significant improvement in presence of various faults.
Deep Learning Accelerator in Loop Reliability Evaluation for Autonomous Driving
Jun 20, 2023

The reliability of deep learning accelerators (DLAs) used in autonomous driving systems has significant impact on the system safety. However, the DLA reliability is usually evaluated with low-level metrics like mean square errors of the output which remains rather different from the high-level metrics like total distance traveled before failure in autonomous driving. As a result, the high-level reliability metrics evaluated at the post-silicon stage may still lead to DLA design revision and result in expensive reliable DLA design iterations targeting at autonomous driving. To address the problem, we proposed a DLA-in-loop reliability evaluation platform to enable system reliability evaluation at the early DLA design stage.
MRFI: An Open Source Multi-Resolution Fault Injection Framework for Neural Network Processing
Jun 20, 2023
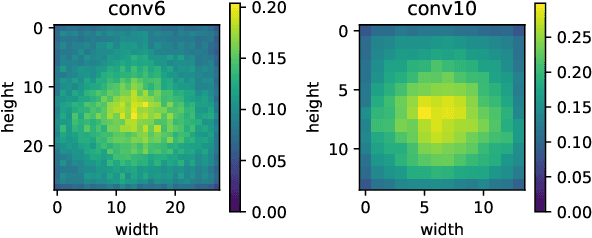


To ensure resilient neural network processing on even unreliable hardware, comprehensive reliability analysis against various hardware faults is generally required before the deep neural network models are deployed, and efficient error injection tools are highly demanded. However, most existing fault injection tools remain rather limited to basic fault injection to neurons and fail to provide fine-grained vulnerability analysis capability. In addition, many of the fault injection tools still need to change the neural network models and make the fault injection closely coupled with normal neural network processing, which further complicates the use of the fault injection tools and slows down the fault simulation. In this work, we propose MRFI, a highly configurable multi-resolution fault injection tool for deep neural networks. It enables users to modify an independent fault configuration file rather than neural network models for the fault injection and vulnerability analysis. Particularly, it integrates extensive fault analysis functionalities from different perspectives and enables multi-resolution investigation of the vulnerability of neural networks. In addition, it does not modify the major neural network computing framework of PyTorch. Hence, it allows parallel processing on GPUs naturally and exhibits fast fault simulation according to our experiments.
Statistical Modeling of Soft Error Influence on Neural Networks
Oct 12, 2022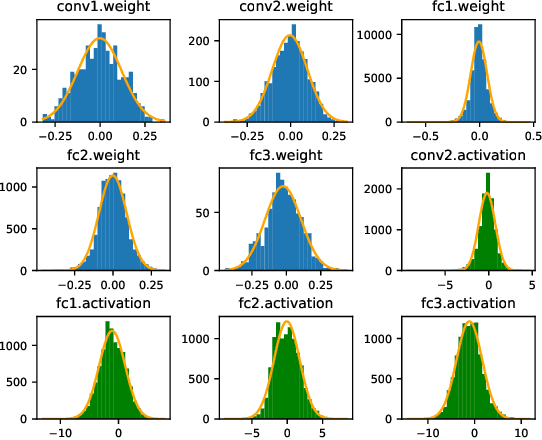
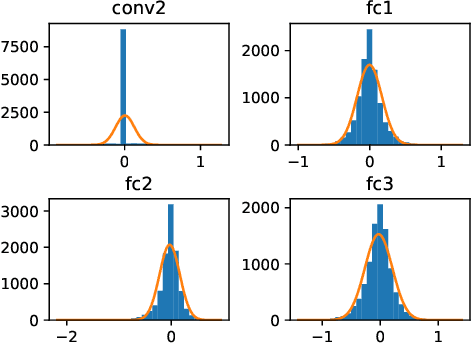
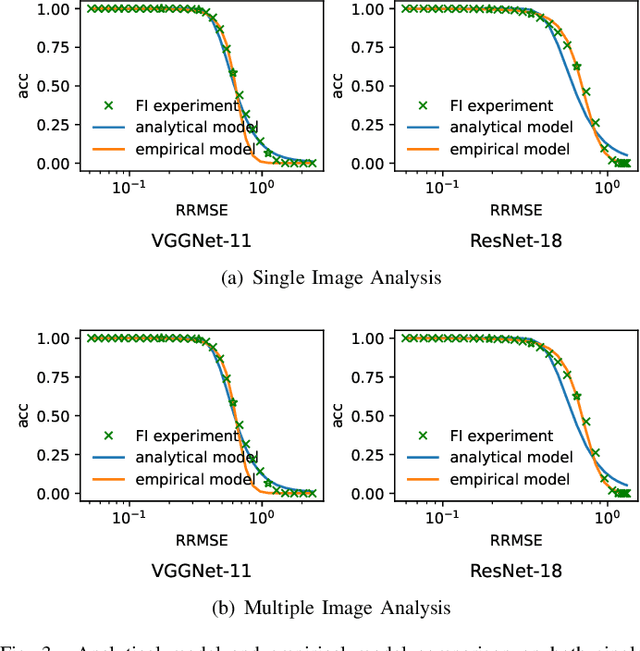
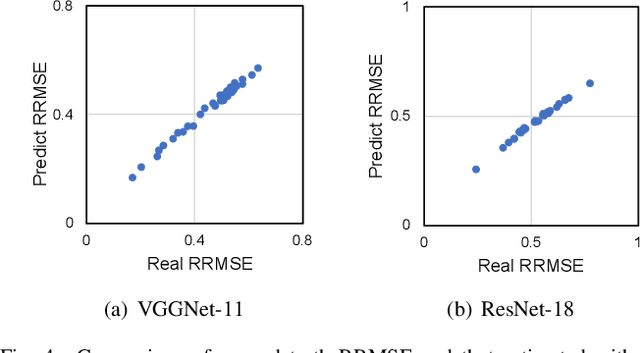
Soft errors in large VLSI circuits pose dramatic influence on computing- and memory-intensive neural network (NN) processing. Understanding the influence of soft errors on NNs is critical to protect against soft errors for reliable NN processing. Prior work mainly rely on fault simulation to analyze the influence of soft errors on NN processing. They are accurate but usually specific to limited configurations of errors and NN models due to the prohibitively slow simulation speed especially for large NN models and datasets. With the observation that the influence of soft errors propagates across a large number of neurons and accumulates as well, we propose to characterize the soft error induced data disturbance on each neuron with normal distribution model according to central limit theorem and develop a series of statistical models to analyze the behavior of NN models under soft errors in general. The statistical models reveal not only the correlation between soft errors and NN model accuracy, but also how NN parameters such as quantization and architecture affect the reliability of NNs. The proposed models are compared with fault simulation and verified comprehensively. In addition, we observe that the statistical models that characterize the soft error influence can also be utilized to predict fault simulation results in many cases and we explore the use of the proposed statistical models to accelerate fault simulations of NNs. According to our experiments, the accelerated fault simulation shows almost two orders of magnitude speedup with negligible simulation accuracy loss over the baseline fault simulations.
Winograd Convolution: A Perspective from Fault Tolerance
Feb 17, 2022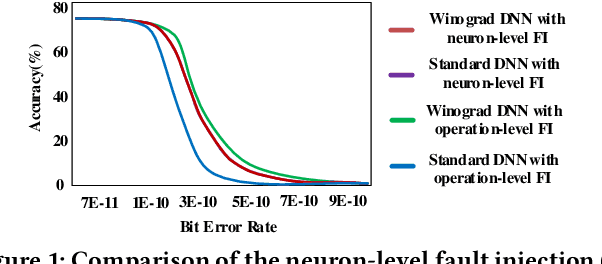
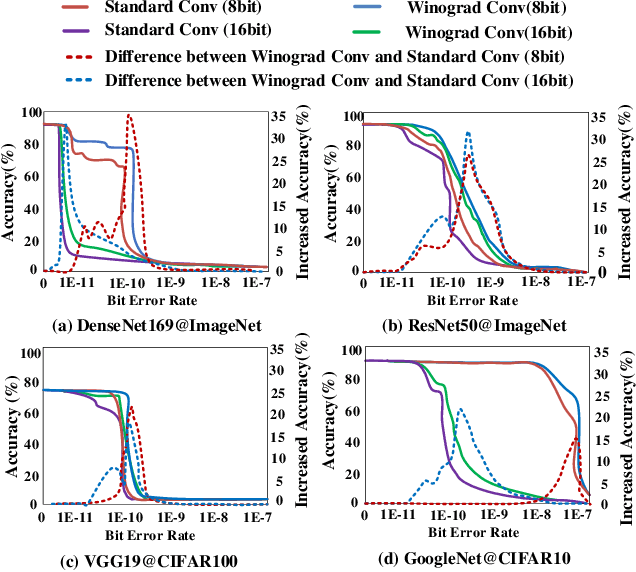
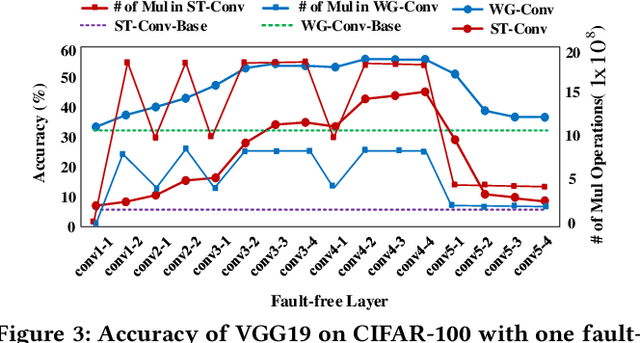
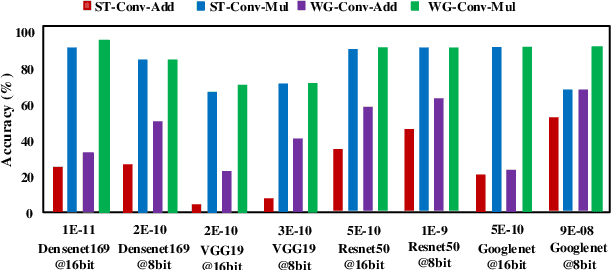
Winograd convolution is originally proposed to reduce the computing overhead by converting multiplication in neural network (NN) with addition via linear transformation. Other than the computing efficiency, we observe its great potential in improving NN fault tolerance and evaluate its fault tolerance comprehensively for the first time. Then, we explore the use of fault tolerance of winograd convolution for either fault-tolerant or energy-efficient NN processing. According to our experiments, winograd convolution can be utilized to reduce fault-tolerant design overhead by 27.49\% or energy consumption by 7.19\% without any accuracy loss compared to that without being aware of the fault tolerance