 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
An Anchor Learning Approach for Citation Field Learning
Sep 07, 2023Citation field learning is to segment a citation string into fields of interest such as author, title, and venue. Extracting such fields from citations is crucial for citation indexing, researcher profile analysis, etc. User-generated resources like academic homepages and Curriculum Vitae, provide rich citation field information. However, extracting fields from these resources is challenging due to inconsistent citation styles, incomplete sentence syntax, and insufficient training data. To address these challenges, we propose a novel algorithm, CIFAL (citation field learning by anchor learning), to boost the citation field learning performance. CIFAL leverages the anchor learning, which is model-agnostic for any Pre-trained Language Model, to help capture citation patterns from the data of different citation styles. The experiments demonstrate that CIFAL outperforms state-of-the-art methods in citation field learning, achieving a 2.83% improvement in field-level F1-scores. Extensive analysis of the results further confirms the effectiveness of CIFAL quantitatively and qualitatively.
CLOWER: A Pre-trained Language Model with Contrastive Learning over Word and Character Representations
Aug 23, 2022

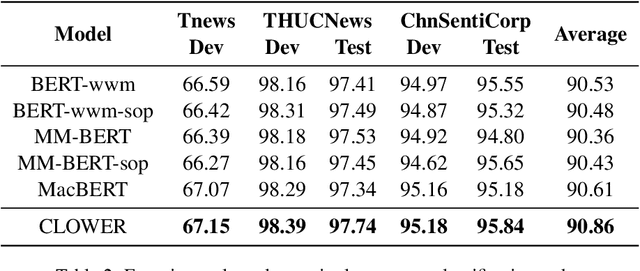
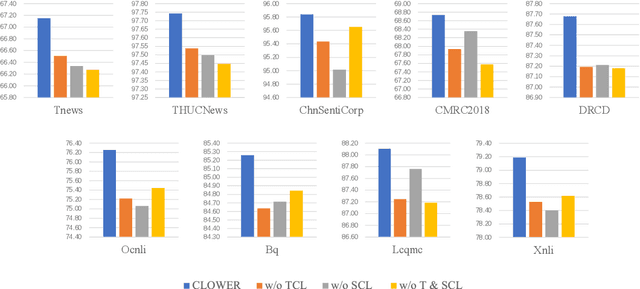
Pre-trained Language Models (PLMs) have achieved remarkable performance gains across numerous downstream tasks in natural language understanding. Various Chinese PLMs have been successively proposed for learning better Chinese language representation. However, most current models use Chinese characters as inputs and are not able to encode semantic information contained in Chinese words. While recent pre-trained models incorporate both words and characters simultaneously, they usually suffer from deficient semantic interactions and fail to capture the semantic relation between words and characters. To address the above issues, we propose a simple yet effective PLM CLOWER, which adopts the Contrastive Learning Over Word and charactER representations. In particular, CLOWER implicitly encodes the coarse-grained information (i.e., words) into the fine-grained representations (i.e., characters) through contrastive learning on multi-grained information. CLOWER is of great value in realistic scenarios since it can be easily incorporated into any existing fine-grained based PLMs without modifying the production pipelines.Extensive experiments conducted on a range of downstream tasks demonstrate the superior performance of CLOWER over several state-of-the-art baselines.
A non-hierarchical attention network with modality dropout for textual response generation in multimodal dialogue systems
Oct 20, 2021
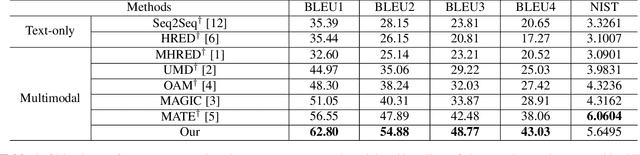
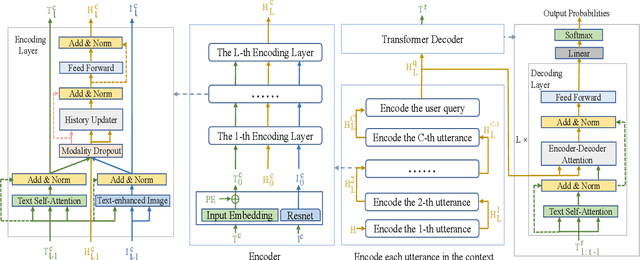

Existing text- and image-based multimodal dialogue systems use the traditional Hierarchical Recurrent Encoder-Decoder (HRED) framework, which has an utterance-level encoder to model utterance representation and a context-level encoder to model context representation. Although pioneer efforts have shown promising performances, they still suffer from the following challenges: (1) the interaction between textual features and visual features is not fine-grained enough. (2) the context representation can not provide a complete representation for the context. To address the issues mentioned above, we propose a non-hierarchical attention network with modality dropout, which abandons the HRED framework and utilizes attention modules to encode each utterance and model the context representation. To evaluate our proposed model, we conduct comprehensive experiments on a public multimodal dialogue dataset. Automatic and human evaluation demonstrate that our proposed model outperforms the existing methods and achieves state-of-the-art performance.