 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Anchor Learning Approach for Citation Field Learning
Sep 07, 2023Citation field learning is to segment a citation string into fields of interest such as author, title, and venue. Extracting such fields from citations is crucial for citation indexing, researcher profile analysis, etc. User-generated resources like academic homepages and Curriculum Vitae, provide rich citation field information. However, extracting fields from these resources is challenging due to inconsistent citation styles, incomplete sentence syntax, and insufficient training data. To address these challenges, we propose a novel algorithm, CIFAL (citation field learning by anchor learning), to boost the citation field learning performance. CIFAL leverages the anchor learning, which is model-agnostic for any Pre-trained Language Model, to help capture citation patterns from the data of different citation styles. The experiments demonstrate that CIFAL outperforms state-of-the-art methods in citation field learning, achieving a 2.83% improvement in field-level F1-scores. Extensive analysis of the results further confirms the effectiveness of CIFAL quantitatively and qualitatively.
NameRec*: Highly Accurate and Fine-grained Person Name Recognition
Mar 23, 2021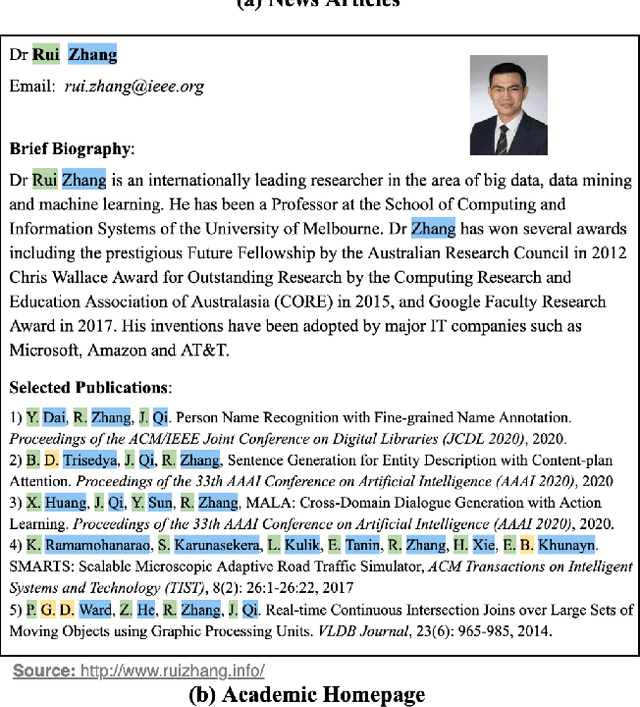
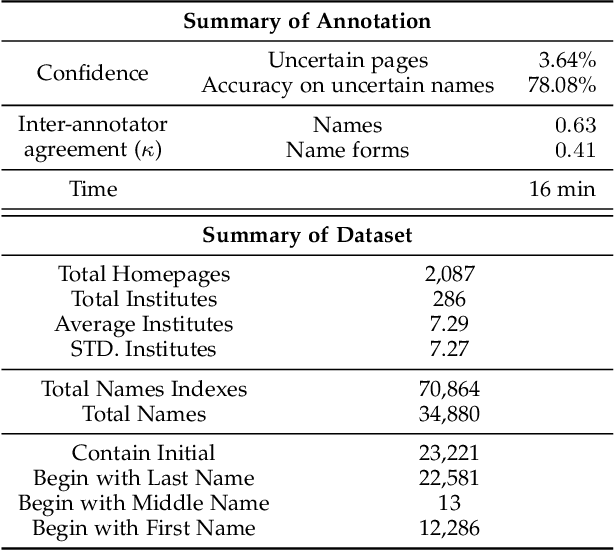
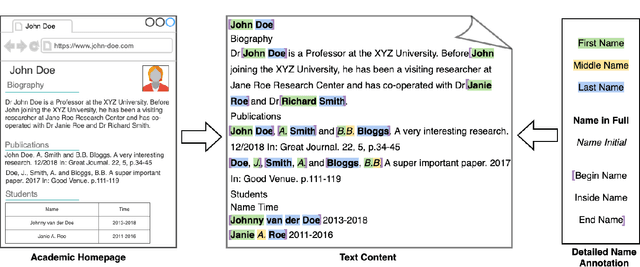
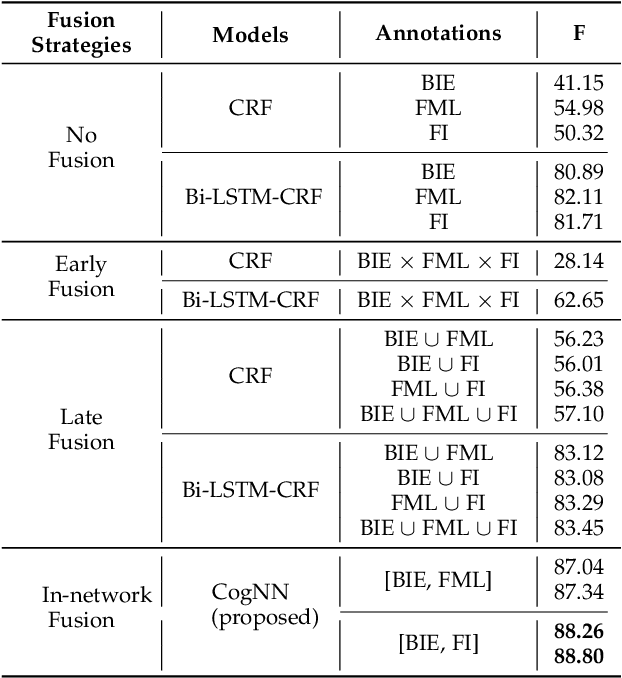
In this paper, we introduce the NameRec* task, which aims to do highly accurate and fine-grained person name recognition. Traditional Named Entity Recognition models have good performance in recognising well-formed person names from text with consistent and complete syntax, such as news articles. However, there are rapidly growing scenarios where sentences are of incomplete syntax and names are in various forms such as user-generated contents and academic homepages. To address person name recognition in this context, we propose a fine-grained annotation scheme based on anthroponymy. To take full advantage of the fine-grained annotations, we propose a Co-guided Neural Network (CogNN) for person name recognition. CogNN fully explores the intra-sentence context and rich training signals of name forms. To better utilize the inter-sentence context and implicit relations, which are extremely essential for recognizing person names in long documents, we further propose an Inter-sentence BERT Model (IsBERT). IsBERT has an overlapped input processor, and an inter-sentence encoder with bidirectional overlapped contextual embedding learning and multi-hop inference mechanisms. To derive benefit from different documents with a diverse abundance of context, we propose an advanced Adaptive Inter-sentence BERT Model (Ada-IsBERT) to dynamically adjust the inter-sentence overlapping ratio to different documents. We conduct extensive experiments to demonstrate the superiority of the proposed methods on both academic homepages and news articles.