 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA non-hierarchical attention network with modality dropout for textual response generation in multimodal dialogue systems
Paper and Code
Oct 20, 2021
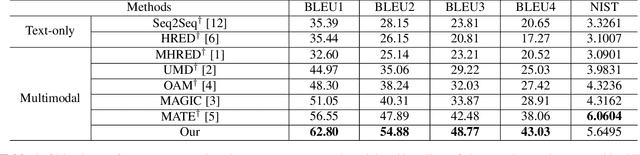
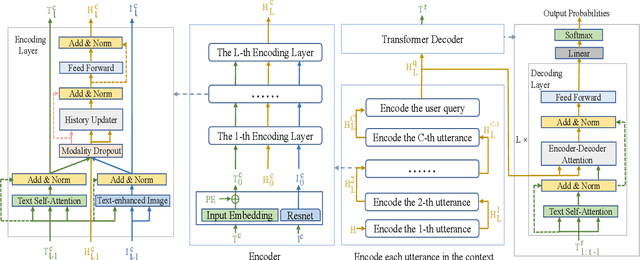

Existing text- and image-based multimodal dialogue systems use the traditional Hierarchical Recurrent Encoder-Decoder (HRED) framework, which has an utterance-level encoder to model utterance representation and a context-level encoder to model context representation. Although pioneer efforts have shown promising performances, they still suffer from the following challenges: (1) the interaction between textual features and visual features is not fine-grained enough. (2) the context representation can not provide a complete representation for the context. To address the issues mentioned above, we propose a non-hierarchical attention network with modality dropout, which abandons the HRED framework and utilizes attention modules to encode each utterance and model the context representation. To evaluate our proposed model, we conduct comprehensive experiments on a public multimodal dialogue dataset. Automatic and human evaluation demonstrate that our proposed model outperforms the existing methods and achieves state-of-the-art performance.