 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Ternary Weight Embedding Model: Bridging Scalability and Performance
Nov 23, 2024



Embedding models have become essential tools in both natural language processing and computer vision, enabling efficient semantic search, recommendation, clustering, and more. However, the high memory and computational demands of full-precision embeddings pose challenges for deployment in resource-constrained environments, such as real-time recommendation systems. In this work, we propose a novel finetuning framework to ternary-weight embedding models, which reduces memory and computational overhead while maintaining high performance. To apply ternarization to pre-trained embedding models, we introduce self-taught knowledge distillation to finalize the ternary-weights of the linear layers. With extensive experiments on public text and vision datasets, we demonstrated that without sacrificing effectiveness, the ternarized model consumes low memory usage and has low latency in the inference stage with great efficiency. In practical implementations, embedding models are typically integrated with Approximate Nearest Neighbor (ANN) search. Our experiments combining ternary embedding with ANN search yielded impressive improvement in both accuracy and computational efficiency. The repository is available at here.
Progressively Optimized Bi-Granular Document Representation for Scalable Embedding Based Retrieval
Jan 14, 2022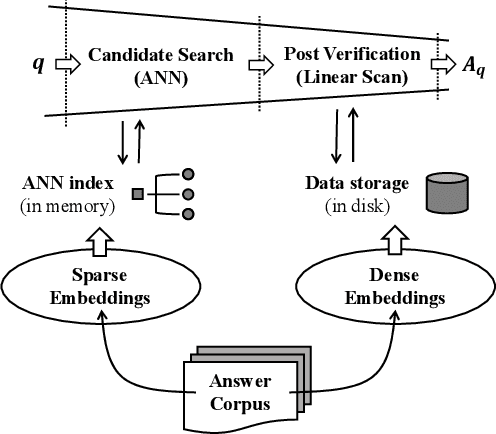
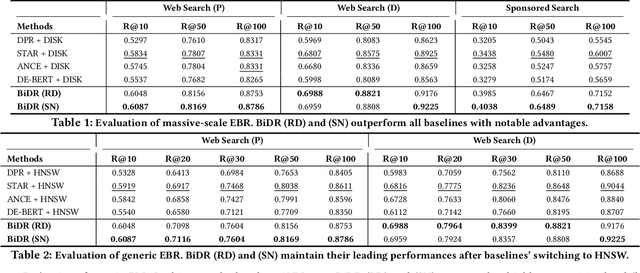
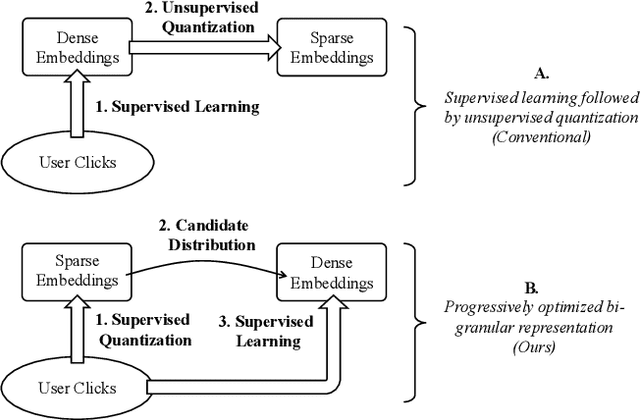
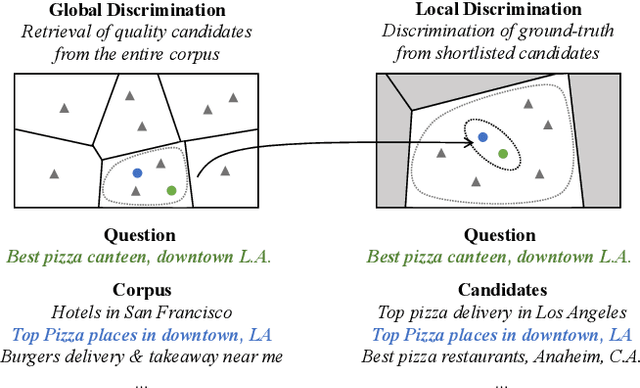
Ad-hoc search calls for the selection of appropriate answers from a massive-scale corpus. Nowadays, the embedding-based retrieval (EBR) becomes a promising solution, where deep learning based document representation and ANN search techniques are allied to handle this task. However, a major challenge is that the ANN index can be too large to fit into memory, given the considerable size of answer corpus. In this work, we tackle this problem with Bi-Granular Document Representation, where the lightweight sparse embeddings are indexed and standby in memory for coarse-grained candidate search, and the heavyweight dense embeddings are hosted in disk for fine-grained post verification. For the best of retrieval accuracy, a Progressive Optimization framework is designed. The sparse embeddings are learned ahead for high-quality search of candidates. Conditioned on the candidate distribution induced by the sparse embeddings, the dense embeddings are continuously learned to optimize the discrimination of ground-truth from the shortlisted candidates. Besides, two techniques: the contrastive quantization and the locality-centric sampling are introduced for the learning of sparse and dense embeddings, which substantially contribute to their performances. Thanks to the above features, our method effectively handles massive-scale EBR with strong advantages in accuracy: with up to +4.3% recall gain on million-scale corpus, and up to +17.5% recall gain on billion-scale corpus. Besides, Our method is applied to a major sponsored search platform with substantial gains on revenue (+1.95%), Recall (+1.01%) and CTR (+0.49%).
PromptBERT: Improving BERT Sentence Embeddings with Prompts
Jan 12, 2022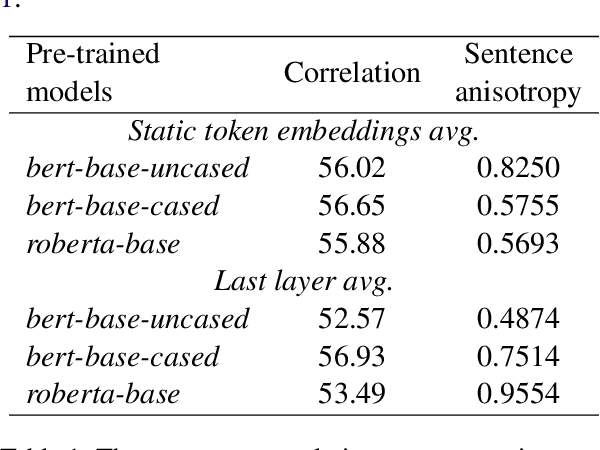
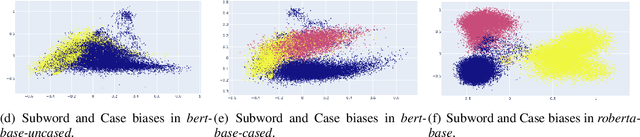
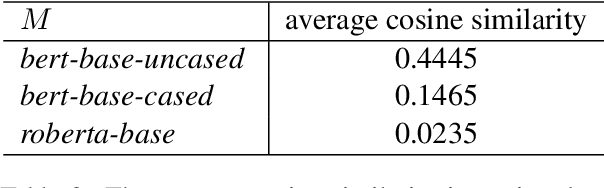

The poor performance of the original BERT for sentence semantic similarity has been widely discussed in previous works. We find that unsatisfactory performance is mainly due to the static token embeddings biases and the ineffective BERT layers, rather than the high cosine similarity of the sentence embeddings. To this end, we propose a prompt based sentence embeddings method which can reduce token embeddings biases and make the original BERT layers more effective. By reformulating the sentence embeddings task as the fillin-the-blanks problem, our method significantly improves the performance of original BERT. We discuss two prompt representing methods and three prompt searching methods for prompt based sentence embeddings. Moreover, we propose a novel unsupervised training objective by the technology of template denoising, which substantially shortens the performance gap between the supervised and unsupervised setting. For experiments, we evaluate our method on both non fine-tuned and fine-tuned settings. Even a non fine-tuned method can outperform the fine-tuned methods like unsupervised ConSERT on STS tasks. Our fine-tuned method outperforms the state-of-the-art method SimCSE in both unsupervised and supervised settings. Compared to SimCSE, we achieve 2.29 and 2.58 points improvements on BERT and RoBERTa respectively under the unsupervised setting.
Improving Non-autoregressive Generation with Mixup Training
Oct 21, 2021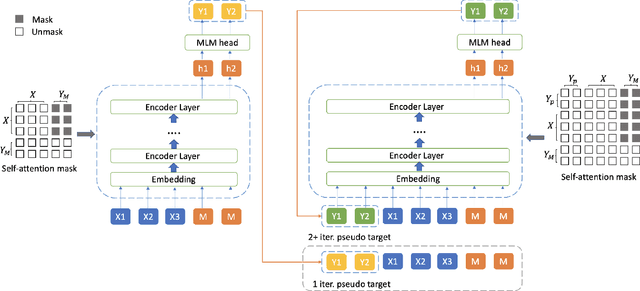
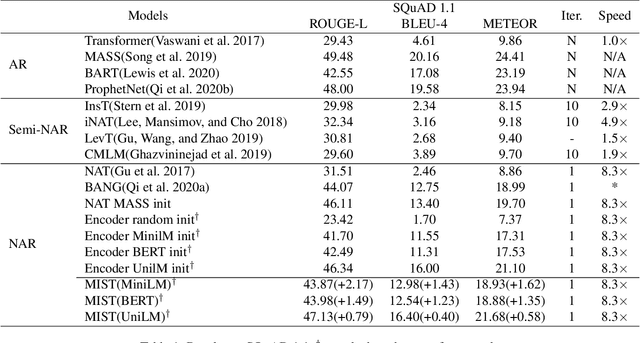
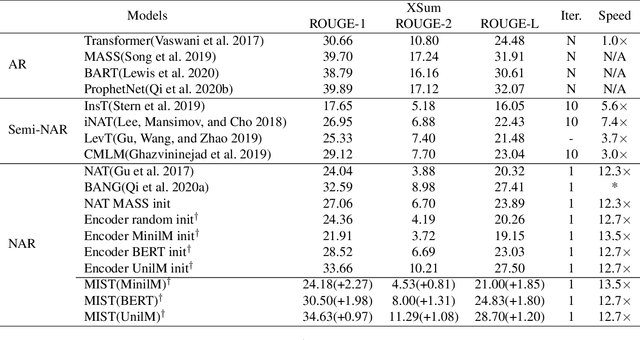
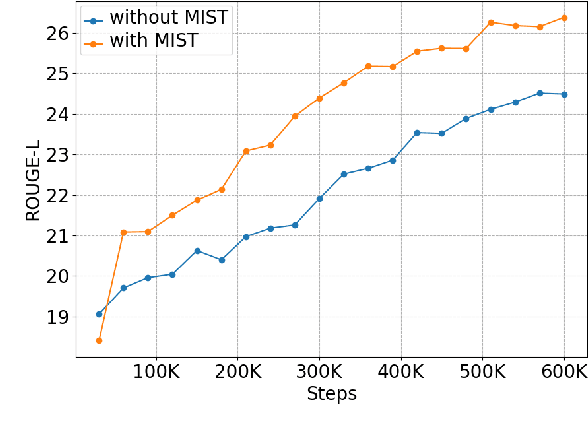
While pre-trained language models have achieved great success on various natural language understanding tasks, how to effectively leverage them into non-autoregressive generation tasks remains a challenge. To solve this problem, we present a non-autoregressive generation model based on pre-trained transformer models. To bridge the gap between autoregressive and non-autoregressive models, we propose a simple and effective iterative training method called MIx Source and pseudo Target (MIST). Unlike other iterative decoding methods, which sacrifice the inference speed to achieve better performance based on multiple decoding iterations, MIST works in the training stage and has no effect on inference time. Our experiments on three generation benchmarks including question generation, summarization and paraphrase generation, show that the proposed framework achieves the new state-of-the-art results for fully non-autoregressive models. We also demonstrate that our method can be used to a variety of pre-trained models. For instance, MIST based on the small pre-trained model also obtains comparable performance with seq2seq models.
AdsGNN: Behavior-Graph Augmented Relevance Modeling in Sponsored Search
Apr 25, 2021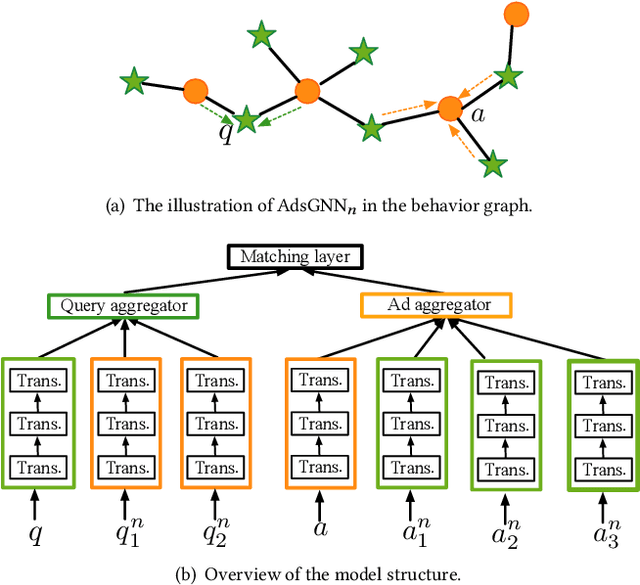

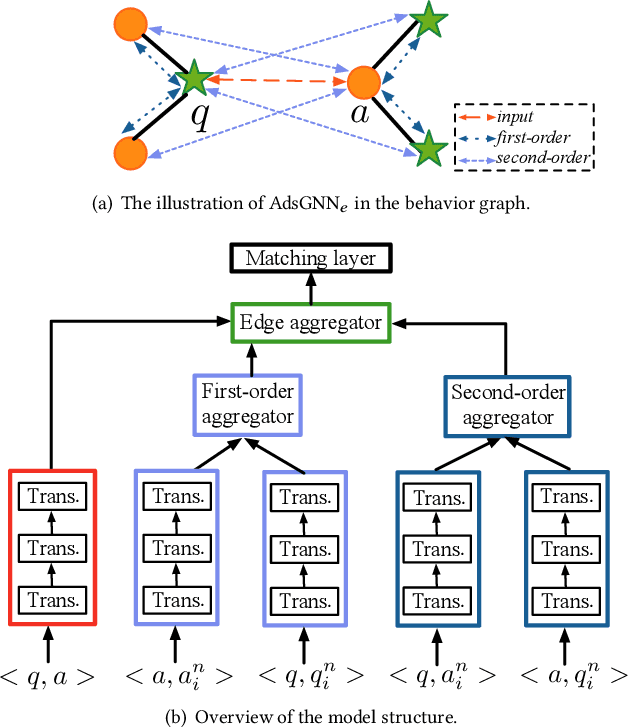
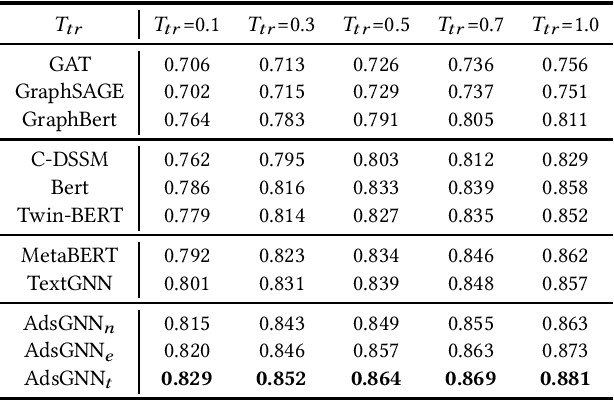
Sponsored search ads appear next to search results when people look for products and services on search engines. In recent years, they have become one of the most lucrative channels for marketing. As the fundamental basis of search ads, relevance modeling has attracted increasing attention due to the significant research challenges and tremendous practical value. Most existing approaches solely rely on the semantic information in the input query-ad pair, while the pure semantic information in the short ads data is not sufficient to fully identify user's search intents. Our motivation lies in incorporating the tremendous amount of unsupervised user behavior data from the historical search logs as the complementary graph to facilitate relevance modeling. In this paper, we extensively investigate how to naturally fuse the semantic textual information with the user behavior graph, and further propose three novel AdsGNN models to aggregate topological neighborhood from the perspectives of nodes, edges and tokens. Furthermore, two critical but rarely investigated problems, domain-specific pre-training and long-tail ads matching, are studied thoroughly. Empirically, we evaluate the AdsGNN models over the large industry dataset, and the experimental results of online/offline tests consistently demonstrate the superiority of our proposal.
TextGNN: Improving Text Encoder via Graph Neural Network in Sponsored Search
Feb 09, 2021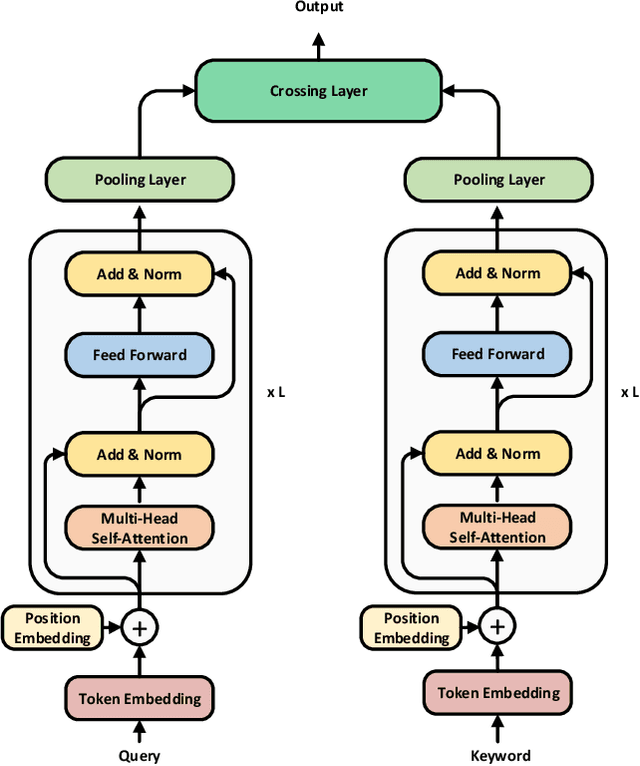
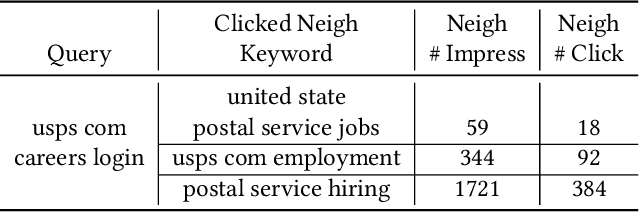
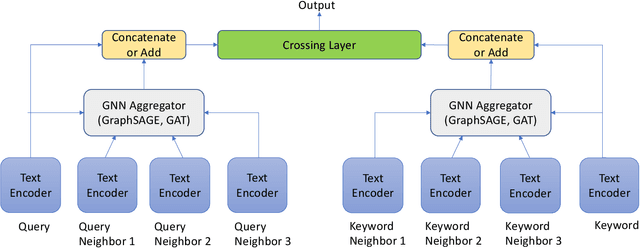
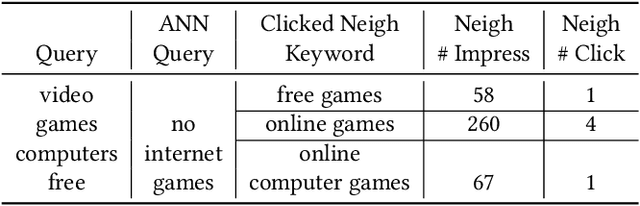
Text encoders based on C-DSSM or transformers have demonstrated strong performance in many Natural Language Processing (NLP) tasks. Low latency variants of these models have also been developed in recent years in order to apply them in the field of sponsored search which has strict computational constraints. However these models are not the panacea to solve all the Natural Language Understanding (NLU) challenges as the pure semantic information in the data is not sufficient to fully identify the user intents. We propose the TextGNN model that naturally extends the strong twin tower structured encoders with the complementary graph information from user historical behaviors, which serves as a natural guide to help us better understand the intents and hence generate better language representations. The model inherits all the benefits of twin tower models such as C-DSSM and TwinBERT so that it can still be used in the low latency environment while achieving a significant performance gain than the strong encoder-only counterpart baseline models in both offline evaluations and online production system. In offline experiments, the model achieves a 0.14% overall increase in ROC-AUC with a 1% increased accuracy for long-tail low-frequency Ads, and in the online A/B testing, the model shows a 2.03% increase in Revenue Per Mille with a 2.32% decrease in Ad defect rate.