 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Zero-Shot Time Series Classification: From Task-specific Classifiers to In-Context Inference
Jan 31, 2026The zero-shot evaluation of time series foundation models (TSFMs) for classification typically uses a frozen encoder followed by a task-specific classifier. However, this practice violates the training-free premise of zero-shot deployment and introduces evaluation bias due to classifier-dependent training choices. To address this issue, we propose TIC-FM, an in-context learning framework that treats the labeled training set as context and predicts labels for all test instances in a single forward pass, without parameter updates. TIC-FM pairs a time series encoder and a lightweight projection adapter with a split-masked latent memory Transformer. We further provide theoretical justification that in-context inference can subsume trained classifiers and can emulate gradient-based classifier training within a single forward pass. Experiments on 128 UCR datasets show strong accuracy, with consistent gains in the extreme low-label situation, highlighting training-free transfer
Disentangling Long-Short Term State Under Unknown Interventions for Online Time Series Forecasting
Feb 18, 2025Current methods for time series forecasting struggle in the online scenario, since it is difficult to preserve long-term dependency while adapting short-term changes when data are arriving sequentially. Although some recent methods solve this problem by controlling the updates of latent states, they cannot disentangle the long/short-term states, leading to the inability to effectively adapt to nonstationary. To tackle this challenge, we propose a general framework to disentangle long/short-term states for online time series forecasting. Our idea is inspired by the observations where short-term changes can be led by unknown interventions like abrupt policies in the stock market. Based on this insight, we formalize a data generation process with unknown interventions on short-term states. Under mild assumptions, we further leverage the independence of short-term states led by unknown interventions to establish the identification theory to achieve the disentanglement of long/short-term states. Built on this theory, we develop a long short-term disentanglement model (LSTD) to extract the long/short-term states with long/short-term encoders, respectively. Furthermore, the LSTD model incorporates a smooth constraint to preserve the long-term dependencies and an interrupted dependency constraint to enforce the forgetting of short-term dependencies, together boosting the disentanglement of long/short-term states. Experimental results on several benchmark datasets show that our \textbf{LSTD} model outperforms existing methods for online time series forecasting, validating its efficacy in real-world applications.
ESKNet-An enhanced adaptive selection kernel convolution for breast tumors segmentation
Nov 05, 2022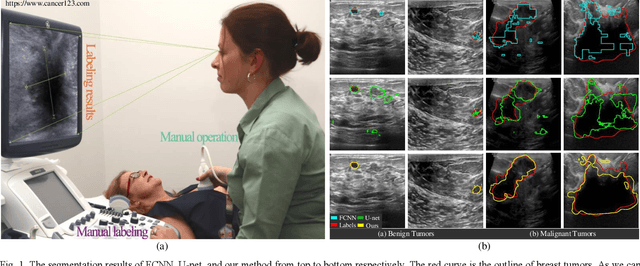



Breast cancer is one of the common cancers that endanger the health of women globally. Accurate target lesion segmentation is essential for early clinical intervention and postoperative follow-up. Recently, many convolutional neural networks (CNNs) have been proposed to segment breast tumors from ultrasound images. However, the complex ultrasound pattern and the variable tumor shape and size bring challenges to the accurate segmentation of the breast lesion. Motivated by the selective kernel convolution, we introduce an enhanced selective kernel convolution for breast tumor segmentation, which integrates multiple feature map region representations and adaptively recalibrates the weights of these feature map regions from the channel and spatial dimensions. This region recalibration strategy enables the network to focus more on high-contributing region features and mitigate the perturbation of less useful regions. Finally, the enhanced selective kernel convolution is integrated into U-net with deep supervision constraints to adaptively capture the robust representation of breast tumors. Extensive experiments with twelve state-of-the-art deep learning segmentation methods on three public breast ultrasound datasets demonstrate that our method has a more competitive segmentation performance in breast ultrasound images.
BAGNet: Bidirectional Aware Guidance Network for Malignant Breast lesions Segmentation
Apr 28, 2022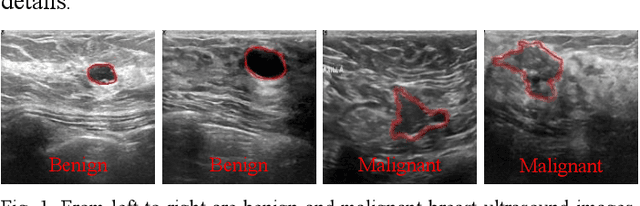


Breast lesions segmentation is an important step of computer-aided diagnosis system, and it has attracted much attention. However, accurate segmentation of malignant breast lesions is a challenging task due to the effects of heterogeneous structure and similar intensity distributions. In this paper, a novel bidirectional aware guidance network (BAGNet) is proposed to segment the malignant lesion from breast ultrasound images. Specifically, the bidirectional aware guidance network is used to capture the context between global (low-level) and local (high-level) features from the input coarse saliency map. The introduction of the global feature map can reduce the interference of surrounding tissue (background) on the lesion regions. To evaluate the segmentation performance of the network, we compared with several state-of-the-art medical image segmentation methods on the public breast ultrasound dataset using six commonly used evaluation metrics. Extensive experimental results indicate that our method achieves the most competitive segmentation results on malignant breast ultrasound images.
EDTER: Edge Detection with Transformer
Mar 16, 2022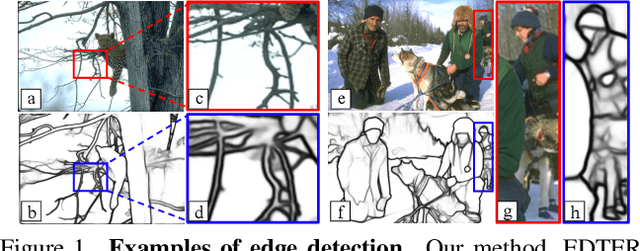

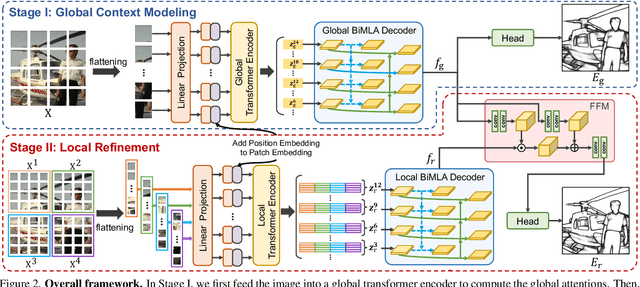
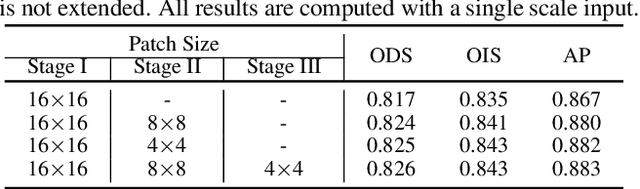
Convolutional neural networks have made significant progresses in edge detection by progressively exploring the context and semantic features. However, local details are gradually suppressed with the enlarging of receptive fields. Recently, vision transformer has shown excellent capability in capturing long-range dependencies. Inspired by this, we propose a novel transformer-based edge detector, \emph{Edge Detection TransformER (EDTER)}, to extract clear and crisp object boundaries and meaningful edges by exploiting the full image context information and detailed local cues simultaneously. EDTER works in two stages. In Stage I, a global transformer encoder is used to capture long-range global context on coarse-grained image patches. Then in Stage II, a local transformer encoder works on fine-grained patches to excavate the short-range local cues. Each transformer encoder is followed by an elaborately designed Bi-directional Multi-Level Aggregation decoder to achieve high-resolution features. Finally, the global context and local cues are combined by a Feature Fusion Module and fed into a decision head for edge prediction. Extensive experiments on BSDS500, NYUDv2, and Multicue demonstrate the superiority of EDTER in comparison with state-of-the-arts.
HousE: Knowledge Graph Embedding with Householder Parameterization
Feb 16, 2022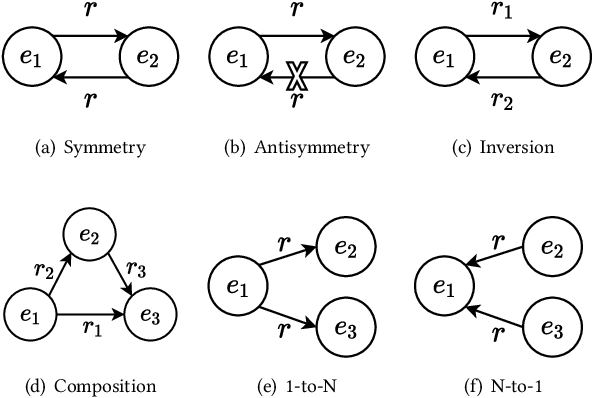
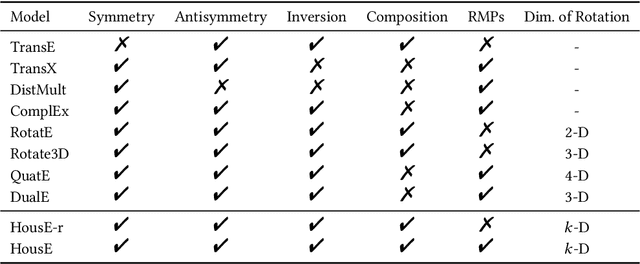
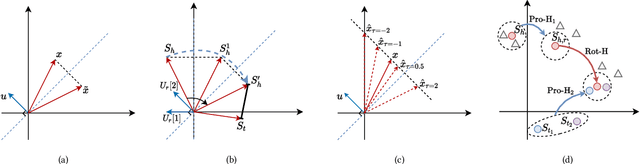
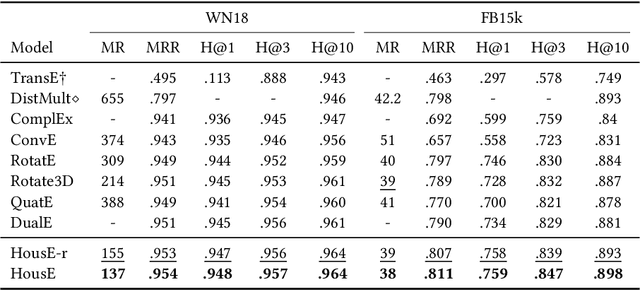
The effectiveness of knowledge graph embedding (KGE) largely depends on the ability to model intrinsic relation patterns and mapping properties. However, existing approaches can only capture some of them with insufficient modeling capacity. In this work, we propose a more powerful KGE framework named HousE, which involves a novel parameterization based on two kinds of Householder transformations: (1) Householder rotations to achieve superior capacity of modeling relation patterns; (2) Householder projections to handle sophisticated relation mapping properties. Theoretically, HousE is capable of modeling crucial relation patterns and mapping properties simultaneously. Besides, HousE is a generalization of existing rotation-based models while extending the rotations to high-dimensional spaces. Empirically, HousE achieves new state-of-the-art performance on five benchmark datasets. Our code is available at https://github.com/anrep/HousE.
Gophormer: Ego-Graph Transformer for Node Classification
Oct 25, 2021Transformers have achieved remarkable performance in a myriad of fields including natural language processing and computer vision. However, when it comes to the graph mining area, where graph neural network (GNN) has been the dominant paradigm, transformers haven't achieved competitive performance, especially on the node classification task. Existing graph transformer models typically adopt fully-connected attention mechanism on the whole input graph and thus suffer from severe scalability issues and are intractable to train in data insufficient cases. To alleviate these issues, we propose a novel Gophormer model which applies transformers on ego-graphs instead of full-graphs. Specifically, Node2Seq module is proposed to sample ego-graphs as the input of transformers, which alleviates the challenge of scalability and serves as an effective data augmentation technique to boost model performance. Moreover, different from the feature-based attention strategy in vanilla transformers, we propose a proximity-enhanced attention mechanism to capture the fine-grained structural bias. In order to handle the uncertainty introduced by the ego-graph sampling, we further propose a consistency regularization and a multi-sample inference strategy for stabilized training and testing, respectively. Extensive experiments on six benchmark datasets are conducted to demonstrate the superiority of Gophormer over existing graph transformers and popular GNNs, revealing the promising future of graph transformers.
Localized Graph Collaborative Filtering
Aug 10, 2021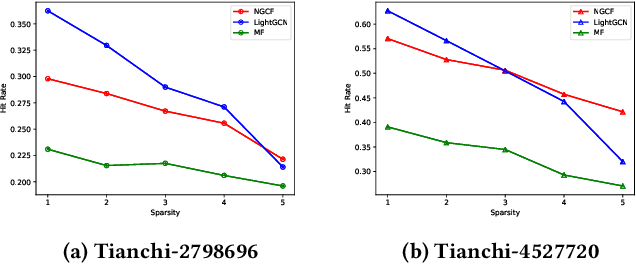
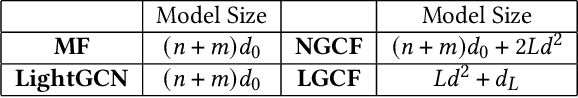
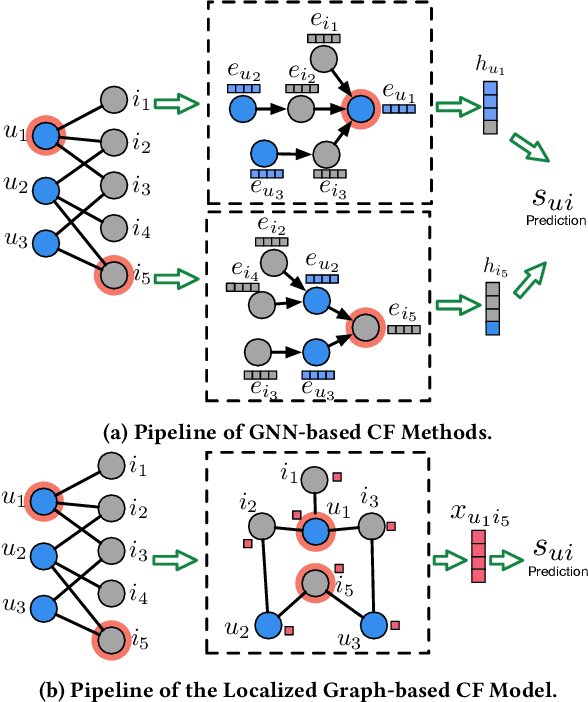
User-item interactions in recommendations can be naturally de-noted as a user-item bipartite graph. Given the success of graph neural networks (GNNs) in graph representation learning, GNN-based C methods have been proposed to advance recommender systems. These methods often make recommendations based on the learned user and item embeddings. However, we found that they do not perform well wit sparse user-item graphs which are quite common in real-world recommendations. Therefore, in this work, we introduce a novel perspective to build GNN-based CF methods for recommendations which leads to the proposed framework Localized Graph Collaborative Filtering (LGCF). One key advantage of LGCF is that it does not need to learn embeddings for each user and item, which is challenging in sparse scenarios. Alternatively, LGCF aims at encoding useful CF information into a localized graph and making recommendations based on such graph. Extensive experiments on various datasets validate the effectiveness of LGCF especially in sparse scenarios. Furthermore, empirical results demonstrate that LGCF provides complementary information to the embedding-based CF model which can be utilized to boost recommendation performance.
AdsGNN: Behavior-Graph Augmented Relevance Modeling in Sponsored Search
Apr 25, 2021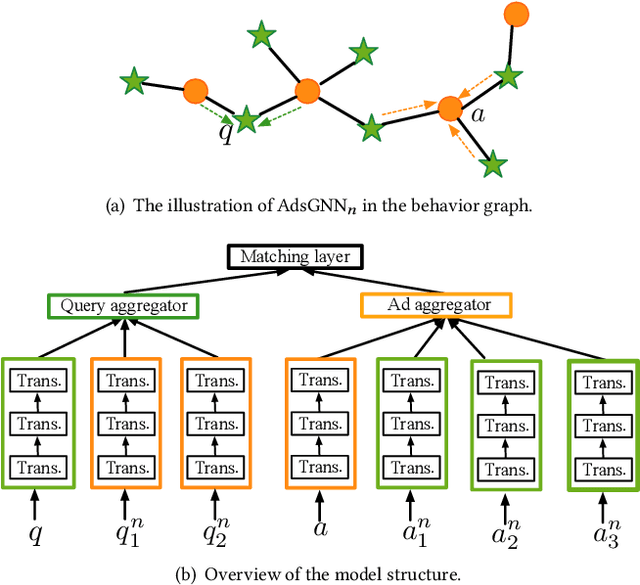

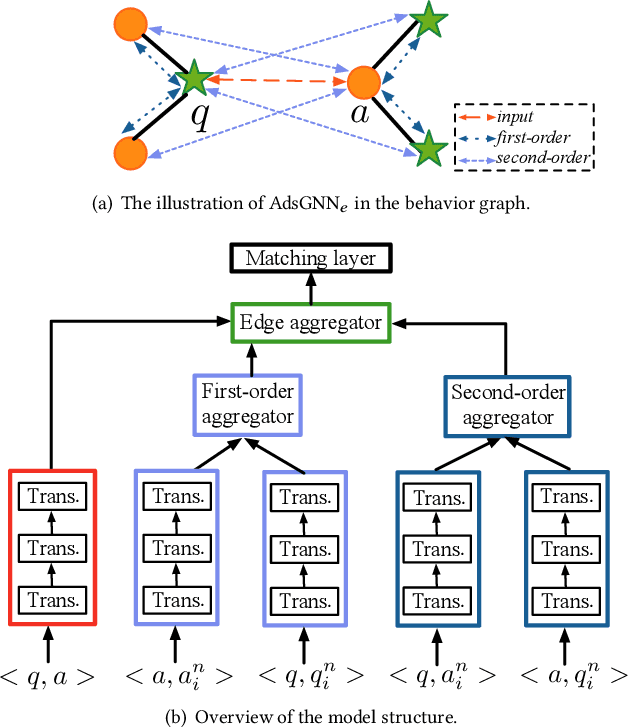
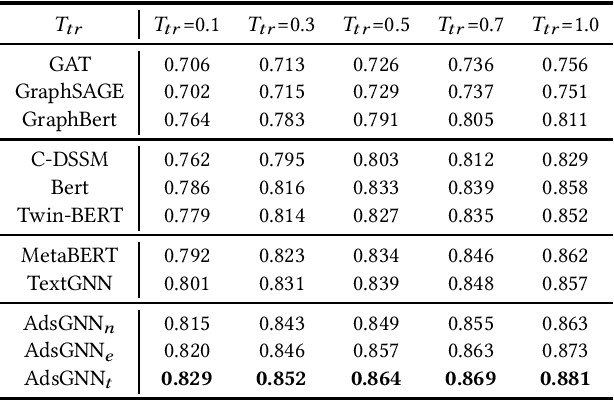
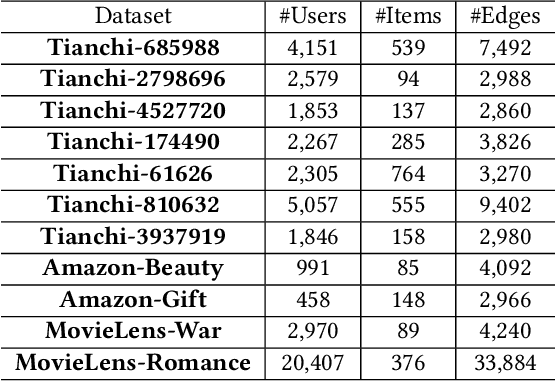
Sponsored search ads appear next to search results when people look for products and services on search engines. In recent years, they have become one of the most lucrative channels for marketing. As the fundamental basis of search ads, relevance modeling has attracted increasing attention due to the significant research challenges and tremendous practical value. Most existing approaches solely rely on the semantic information in the input query-ad pair, while the pure semantic information in the short ads data is not sufficient to fully identify user's search intents. Our motivation lies in incorporating the tremendous amount of unsupervised user behavior data from the historical search logs as the complementary graph to facilitate relevance modeling. In this paper, we extensively investigate how to naturally fuse the semantic textual information with the user behavior graph, and further propose three novel AdsGNN models to aggregate topological neighborhood from the perspectives of nodes, edges and tokens. Furthermore, two critical but rarely investigated problems, domain-specific pre-training and long-tail ads matching, are studied thoroughly. Empirically, we evaluate the AdsGNN models over the large industry dataset, and the experimental results of online/offline tests consistently demonstrate the superiority of our proposal.
TextGNN: Improving Text Encoder via Graph Neural Network in Sponsored Search
Feb 09, 2021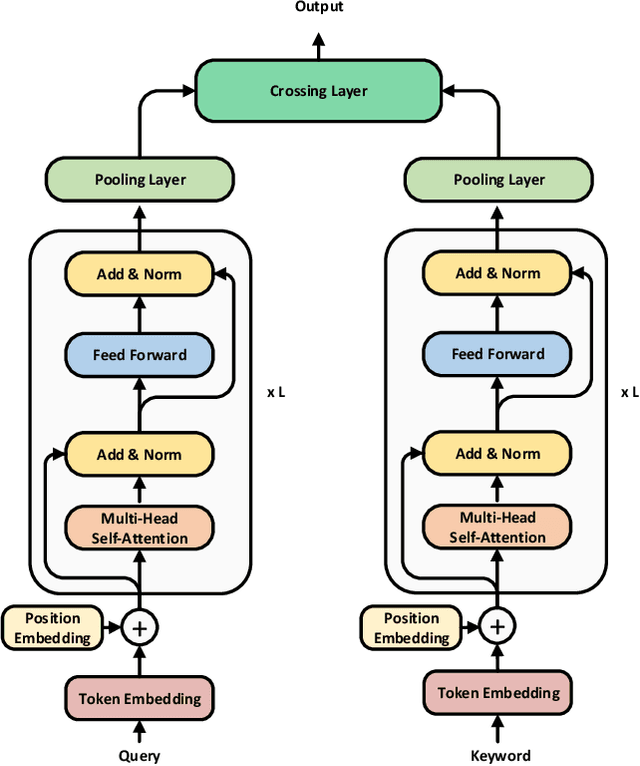
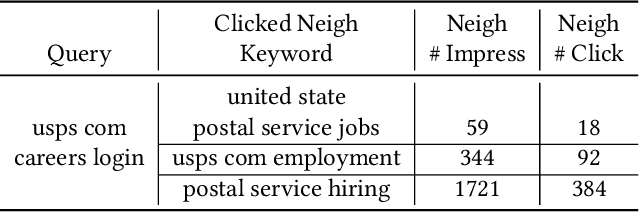
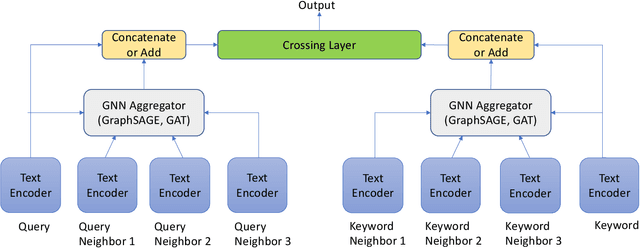
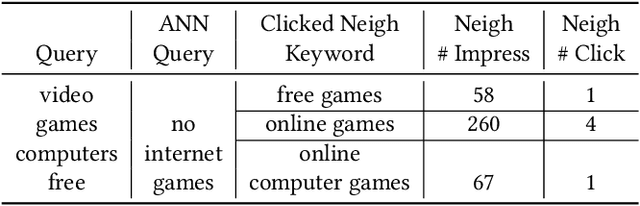
Text encoders based on C-DSSM or transformers have demonstrated strong performance in many Natural Language Processing (NLP) tasks. Low latency variants of these models have also been developed in recent years in order to apply them in the field of sponsored search which has strict computational constraints. However these models are not the panacea to solve all the Natural Language Understanding (NLU) challenges as the pure semantic information in the data is not sufficient to fully identify the user intents. We propose the TextGNN model that naturally extends the strong twin tower structured encoders with the complementary graph information from user historical behaviors, which serves as a natural guide to help us better understand the intents and hence generate better language representations. The model inherits all the benefits of twin tower models such as C-DSSM and TwinBERT so that it can still be used in the low latency environment while achieving a significant performance gain than the strong encoder-only counterpart baseline models in both offline evaluations and online production system. In offline experiments, the model achieves a 0.14% overall increase in ROC-AUC with a 1% increased accuracy for long-tail low-frequency Ads, and in the online A/B testing, the model shows a 2.03% increase in Revenue Per Mille with a 2.32% decrease in Ad defect rate.