 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Feature Decoupling for Fine-Grained OOD Detection
Jun 04, 2026Out-of-distribution detection (OOD) is an indispensable technique when applying machine learning models to real-world scenarios. Most existing OOD detection methods have been developed under the idealized assumption of large inter-class distributional differences, while largely overlooking fine-grained tasks characterized by subtle variations, such as medical image classification and vehicle recognition. The high visual similarity among fine-grained subcategories, together with the interference of background factors, makes OOD detection extremely challenging. To tackle this problem, we propose a novel Dual Feature Decoupling Network (DFDNet), which addresses fine-grained OOD detection from the perspective of feature disentanglement. The proposed DFDNet comprises two key components: a spatial-frequency decoupling module and a reconstruction-guided decoupling module. The spatial-frequency decoupling module is designed to preserve content features that are discriminative for classification while suppressing task-irrelevant style information. On the other hand, the reconstruction-guided decoupling module introduces a novel pixel-level adversarial reconstruction task to further remove low-level, non-discriminative information and enhance category-specific high-level semantic representations. Extensive experiments demonstrate that our method achieves competitive performance improvements on multiple datasets.
The Treasure Beneath Multiple Annotations: An Uncertainty-aware Edge Detector
Mar 21, 2023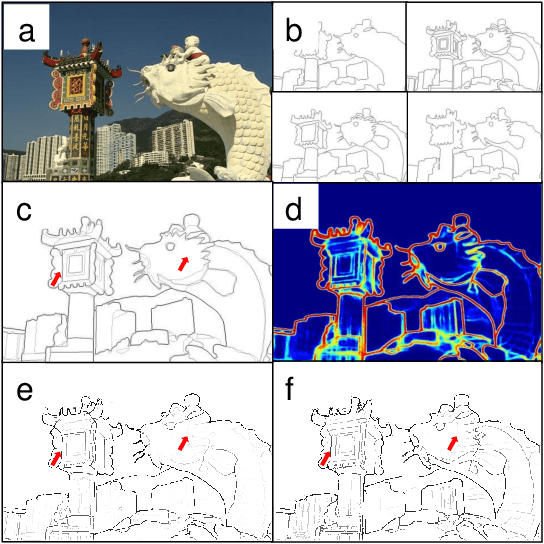
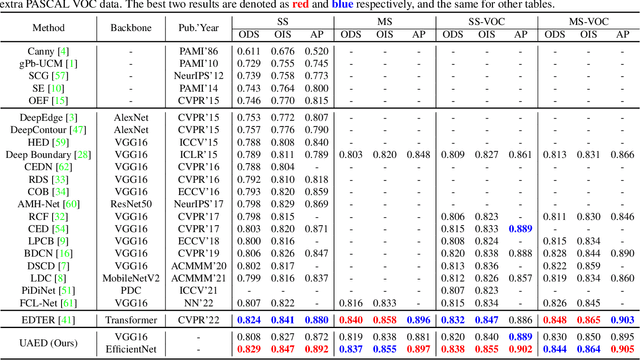
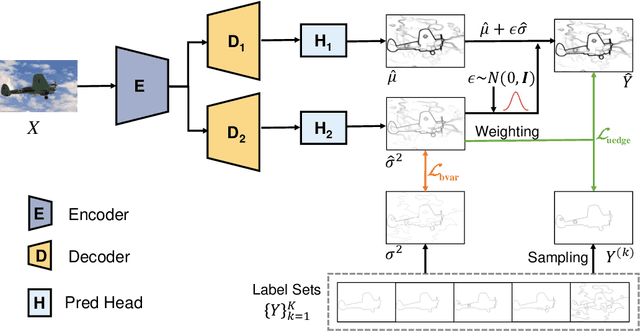
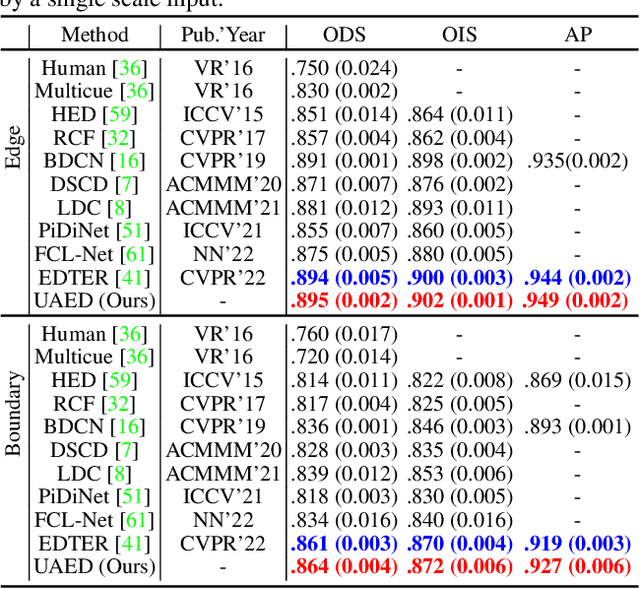
Deep learning-based edge detectors heavily rely on pixel-wise labels which are often provided by multiple annotators. Existing methods fuse multiple annotations using a simple voting process, ignoring the inherent ambiguity of edges and labeling bias of annotators. In this paper, we propose a novel uncertainty-aware edge detector (UAED), which employs uncertainty to investigate the subjectivity and ambiguity of diverse annotations. Specifically, we first convert the deterministic label space into a learnable Gaussian distribution, whose variance measures the degree of ambiguity among different annotations. Then we regard the learned variance as the estimated uncertainty of the predicted edge maps, and pixels with higher uncertainty are likely to be hard samples for edge detection. Therefore we design an adaptive weighting loss to emphasize the learning from those pixels with high uncertainty, which helps the network to gradually concentrate on the important pixels. UAED can be combined with various encoder-decoder backbones, and the extensive experiments demonstrate that UAED achieves superior performance consistently across multiple edge detection benchmarks. The source code is available at \url{https://github.com/ZhouCX117/UAED}
EDTER: Edge Detection with Transformer
Mar 16, 2022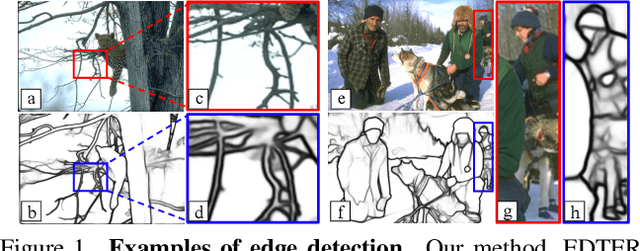

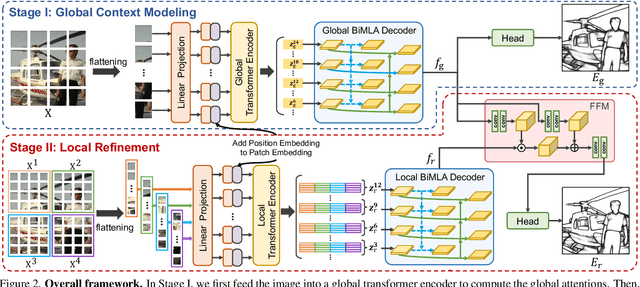
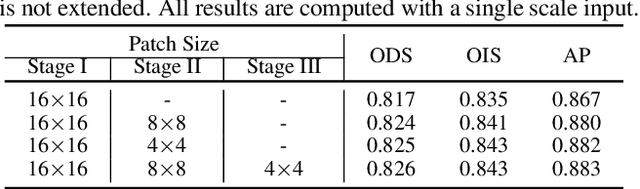
Convolutional neural networks have made significant progresses in edge detection by progressively exploring the context and semantic features. However, local details are gradually suppressed with the enlarging of receptive fields. Recently, vision transformer has shown excellent capability in capturing long-range dependencies. Inspired by this, we propose a novel transformer-based edge detector, \emph{Edge Detection TransformER (EDTER)}, to extract clear and crisp object boundaries and meaningful edges by exploiting the full image context information and detailed local cues simultaneously. EDTER works in two stages. In Stage I, a global transformer encoder is used to capture long-range global context on coarse-grained image patches. Then in Stage II, a local transformer encoder works on fine-grained patches to excavate the short-range local cues. Each transformer encoder is followed by an elaborately designed Bi-directional Multi-Level Aggregation decoder to achieve high-resolution features. Finally, the global context and local cues are combined by a Feature Fusion Module and fed into a decision head for edge prediction. Extensive experiments on BSDS500, NYUDv2, and Multicue demonstrate the superiority of EDTER in comparison with state-of-the-arts.
RINDNet: Edge Detection for Discontinuity in Reflectance, Illumination, Normal and Depth
Aug 02, 2021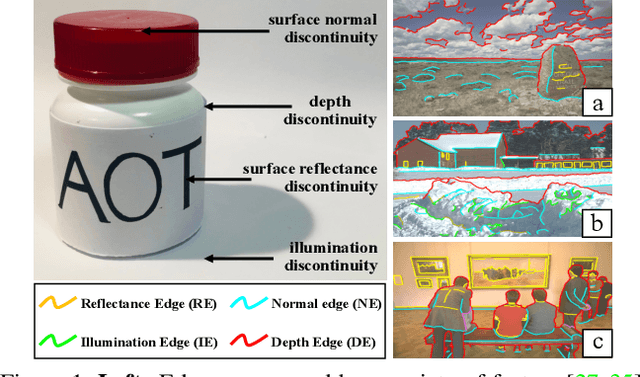
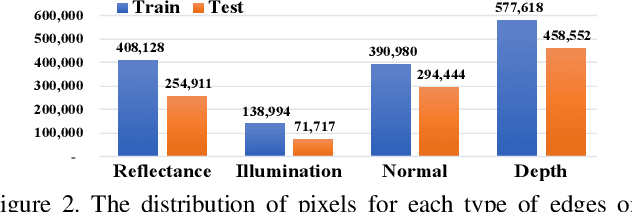

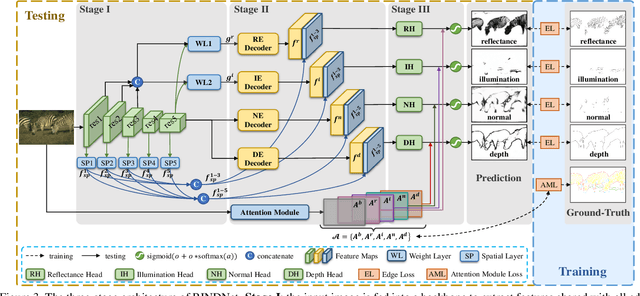
As a fundamental building block in computer vision, edges can be categorised into four types according to the discontinuity in surface-Reflectance, Illumination, surface-Normal or Depth. While great progress has been made in detecting generic or individual types of edges, it remains under-explored to comprehensively study all four edge types together. In this paper, we propose a novel neural network solution, RINDNet, to jointly detect all four types of edges. Taking into consideration the distinct attributes of each type of edges and the relationship between them, RINDNet learns effective representations for each of them and works in three stages. In stage I, RINDNet uses a common backbone to extract features shared by all edges. Then in stage II it branches to prepare discriminative features for each edge type by the corresponding decoder. In stage III, an independent decision head for each type aggregates the features from previous stages to predict the initial results. Additionally, an attention module learns attention maps for all types to capture the underlying relations between them, and these maps are combined with initial results to generate the final edge detection results. For training and evaluation, we construct the first public benchmark, BSDS-RIND, with all four types of edges carefully annotated. In our experiments, RINDNet yields promising results in comparison with state-of-the-art methods. Additional analysis is presented in supplementary material.
Learning from Pixel-Level Label Noise: A New Perspective for Semi-Supervised Semantic Segmentation
Mar 26, 2021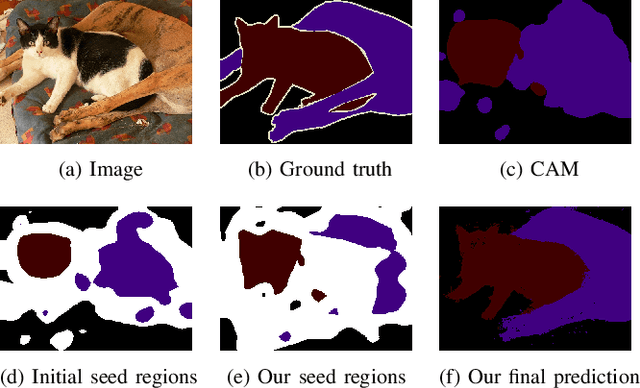
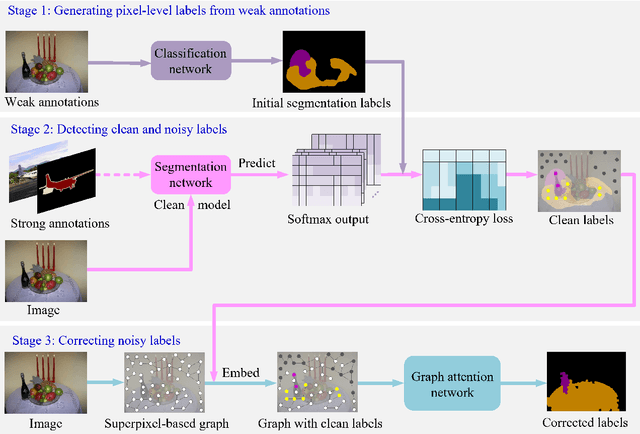


This paper addresses semi-supervised semantic segmentation by exploiting a small set of images with pixel-level annotations (strong supervisions) and a large set of images with only image-level annotations (weak supervisions). Most existing approaches aim to generate accurate pixel-level labels from weak supervisions. However, we observe that those generated labels still inevitably contain noisy labels. Motivated by this observation, we present a novel perspective and formulate this task as a problem of learning with pixel-level label noise. Existing noisy label methods, nevertheless, mainly aim at image-level tasks, which can not capture the relationship between neighboring labels in one image. Therefore, we propose a graph based label noise detection and correction framework to deal with pixel-level noisy labels. In particular, for the generated pixel-level noisy labels from weak supervisions by Class Activation Map (CAM), we train a clean segmentation model with strong supervisions to detect the clean labels from these noisy labels according to the cross-entropy loss. Then, we adopt a superpixel-based graph to represent the relations of spatial adjacency and semantic similarity between pixels in one image. Finally we correct the noisy labels using a Graph Attention Network (GAT) supervised by detected clean labels. We comprehensively conduct experiments on PASCAL VOC 2012, PASCAL-Context and MS-COCO datasets. The experimental results show that our proposed semi supervised method achieves the state-of-the-art performances and even outperforms the fully-supervised models on PASCAL VOC 2012 and MS-COCO datasets in some cases.
Mining Objects: Fully Unsupervised Object Discovery and Localization From a Single Image
Feb 26, 2019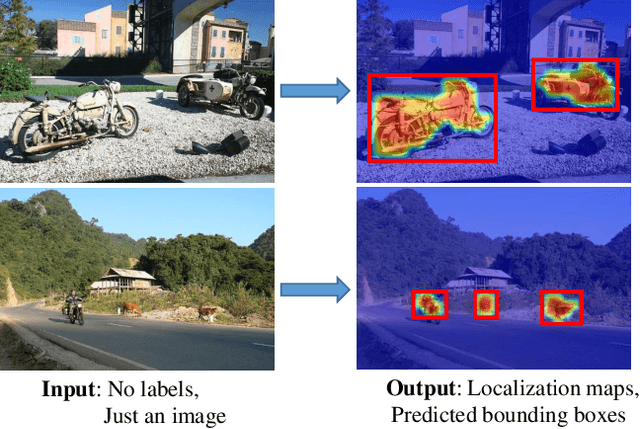
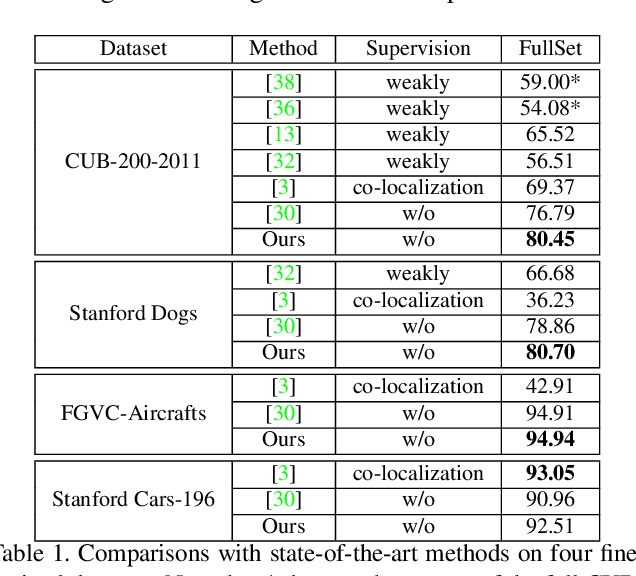
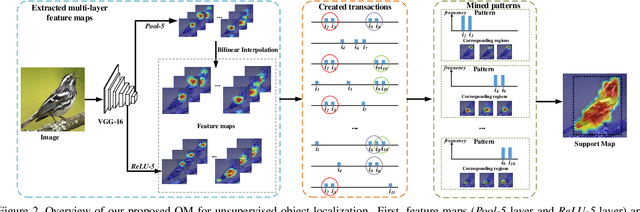
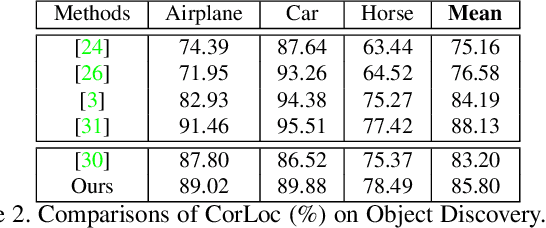
The goal of our work is to discover dominant objects without using any annotations. We focus on performing unsupervised object discovery and localization in a strictly general setting where only a single image is given. This is far more challenge than typical co-localization or weakly-supervised localization tasks. To tackle this problem, we propose a simple but effective pattern mining-based method, called Object Mining (OM), which exploits the ad-vantages of data mining and feature representation of pre-trained convolutional neural networks (CNNs). Specifically,Object Mining first converts the feature maps from a pre-trained CNN model into a set of transactions, and then frequent patterns are discovered from transaction data base through pattern mining techniques. We observe that those discovered patterns, i.e., co-occurrence highlighted regions,typically hold appearance and spatial consistency. Motivated by this observation, we can easily discover and localize possible objects by merging relevant meaningful pat-terns in an unsupervised manner. Extensive experiments on a variety of benchmarks demonstrate that Object Mining achieves competitive performance compared with the state-of-the-art methods.
Diagnose like a Radiologist: Attention Guided Convolutional Neural Network for Thorax Disease Classification
Jan 30, 2018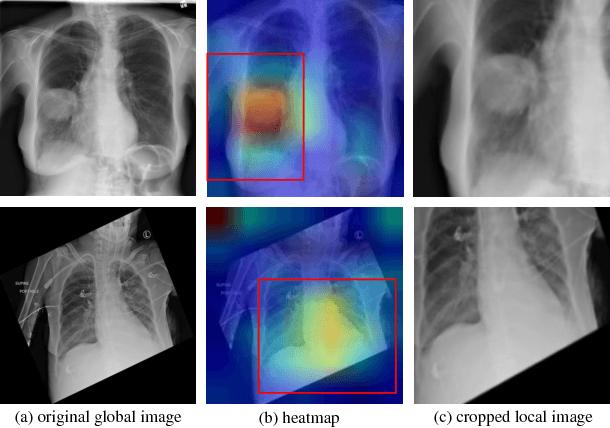
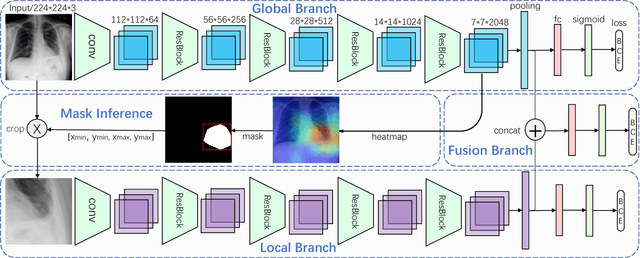
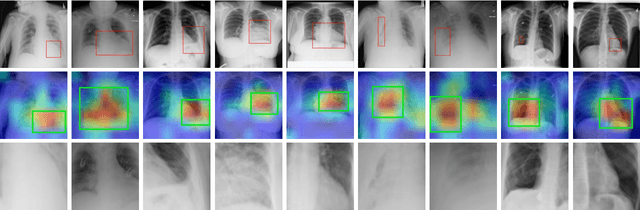

This paper considers the task of thorax disease classification on chest X-ray images. Existing methods generally use the global image as input for network learning. Such a strategy is limited in two aspects. 1) A thorax disease usually happens in (small) localized areas which are disease specific. Training CNNs using global image may be affected by the (excessive) irrelevant noisy areas. 2) Due to the poor alignment of some CXR images, the existence of irregular borders hinders the network performance. In this paper, we address the above problems by proposing a three-branch attention guided convolution neural network (AG-CNN). AG-CNN 1) learns from disease-specific regions to avoid noise and improve alignment, 2) also integrates a global branch to compensate the lost discriminative cues by local branch. Specifically, we first learn a global CNN branch using global images. Then, guided by the attention heat map generated from the global branch, we inference a mask to crop a discriminative region from the global image. The local region is used for training a local CNN branch. Lastly, we concatenate the last pooling layers of both the global and local branches for fine-tuning the fusion branch. The Comprehensive experiment is conducted on the ChestX-ray14 dataset. We first report a strong global baseline producing an average AUC of 0.841 with ResNet-50 as backbone. After combining the local cues with the global information, AG-CNN improves the average AUC to 0.868. While DenseNet-121 is used, the average AUC achieves 0.871, which is a new state of the art in the community.