 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Pixel-Level Label Noise: A New Perspective for Semi-Supervised Semantic Segmentation
Mar 26, 2021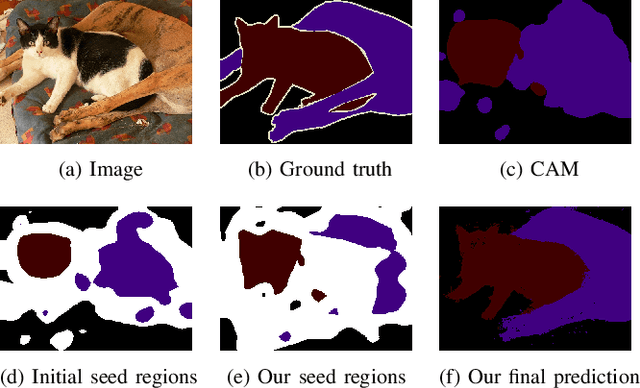
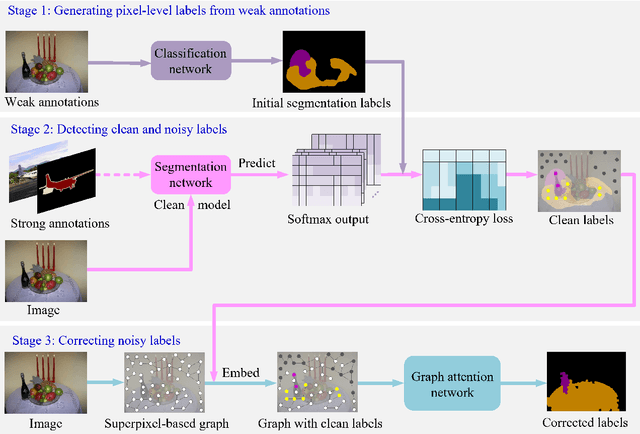


This paper addresses semi-supervised semantic segmentation by exploiting a small set of images with pixel-level annotations (strong supervisions) and a large set of images with only image-level annotations (weak supervisions). Most existing approaches aim to generate accurate pixel-level labels from weak supervisions. However, we observe that those generated labels still inevitably contain noisy labels. Motivated by this observation, we present a novel perspective and formulate this task as a problem of learning with pixel-level label noise. Existing noisy label methods, nevertheless, mainly aim at image-level tasks, which can not capture the relationship between neighboring labels in one image. Therefore, we propose a graph based label noise detection and correction framework to deal with pixel-level noisy labels. In particular, for the generated pixel-level noisy labels from weak supervisions by Class Activation Map (CAM), we train a clean segmentation model with strong supervisions to detect the clean labels from these noisy labels according to the cross-entropy loss. Then, we adopt a superpixel-based graph to represent the relations of spatial adjacency and semantic similarity between pixels in one image. Finally we correct the noisy labels using a Graph Attention Network (GAT) supervised by detected clean labels. We comprehensively conduct experiments on PASCAL VOC 2012, PASCAL-Context and MS-COCO datasets. The experimental results show that our proposed semi supervised method achieves the state-of-the-art performances and even outperforms the fully-supervised models on PASCAL VOC 2012 and MS-COCO datasets in some cases.
Transform consistency for learning with noisy labels
Mar 25, 2021



It is crucial to distinguish mislabeled samples for dealing with noisy labels. Previous methods such as Coteaching and JoCoR introduce two different networks to select clean samples out of the noisy ones and only use these clean ones to train the deep models. Different from these methods which require to train two networks simultaneously, we propose a simple and effective method to identify clean samples only using one single network. We discover that the clean samples prefer to reach consistent predictions for the original images and the transformed images while noisy samples usually suffer from inconsistent predictions. Motivated by this observation, we introduce to constrain the transform consistency between the original images and the transformed images for network training, and then select small-loss samples to update the parameters of the network. Furthermore, in order to mitigate the negative influence of noisy labels, we design a classification loss by using the off-line hard labels and on-line soft labels to provide more reliable supervisions for training a robust model. We conduct comprehensive experiments on CIFAR-10, CIFAR-100 and Clothing1M datasets. Compared with the baselines, we achieve the state-of-the-art performance. Especially, in most cases, our proposed method outperforms the baselines by a large margin.