 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Graph Structure Refinement for Graph Neural Networks
Nov 12, 2022



Graph structure learning (GSL), which aims to learn the adjacency matrix for graph neural networks (GNNs), has shown great potential in boosting the performance of GNNs. Most existing GSL works apply a joint learning framework where the estimated adjacency matrix and GNN parameters are optimized for downstream tasks. However, as GSL is essentially a link prediction task, whose goal may largely differ from the goal of the downstream task. The inconsistency of these two goals limits the GSL methods to learn the potential optimal graph structure. Moreover, the joint learning framework suffers from scalability issues in terms of time and space during the process of estimation and optimization of the adjacency matrix. To mitigate these issues, we propose a graph structure refinement (GSR) framework with a pretrain-finetune pipeline. Specifically, The pre-training phase aims to comprehensively estimate the underlying graph structure by a multi-view contrastive learning framework with both intra- and inter-view link prediction tasks. Then, the graph structure is refined by adding and removing edges according to the edge probabilities estimated by the pre-trained model. Finally, the fine-tuning GNN is initialized by the pre-trained model and optimized toward downstream tasks. With the refined graph structure remaining static in the fine-tuning space, GSR avoids estimating and optimizing graph structure in the fine-tuning phase which enjoys great scalability and efficiency. Moreover, the fine-tuning GNN is boosted by both migrating knowledge and refining graphs. Extensive experiments are conducted to evaluate the effectiveness (best performance on six benchmark datasets), efficiency, and scalability (13.8x faster using 32.8% GPU memory compared to the best GSL baseline on Cora) of the proposed model.
Multi-task Self-supervised Graph Neural Networks Enable Stronger Task Generalization
Oct 05, 2022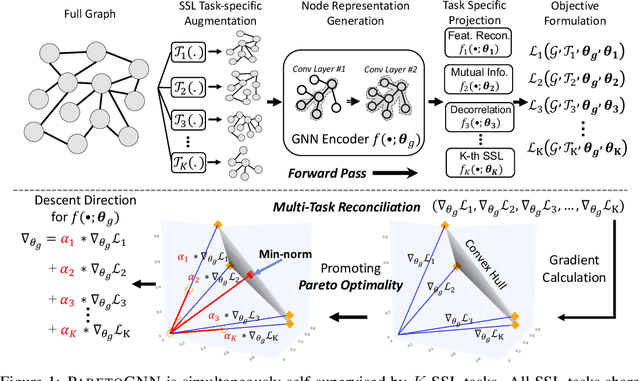
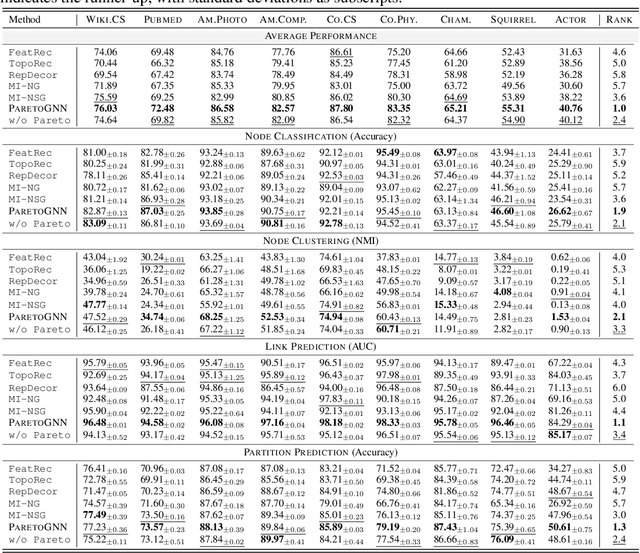
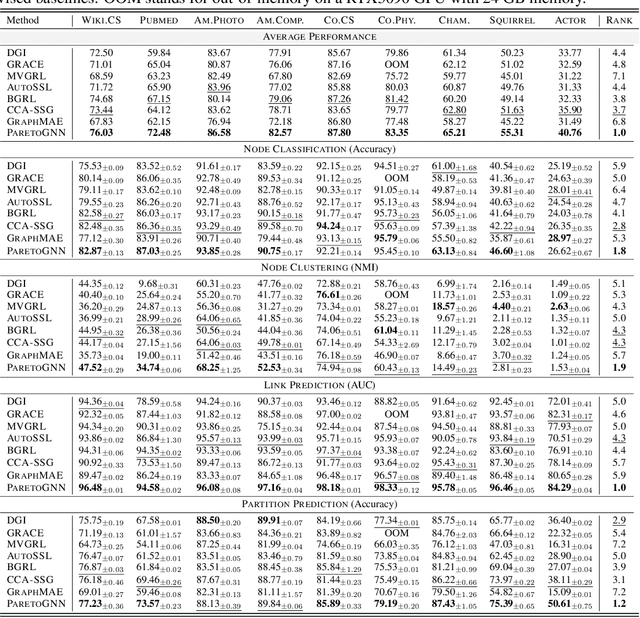
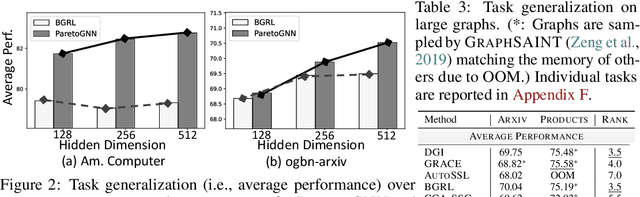
Self-supervised learning (SSL) for graph neural networks (GNNs) has attracted increasing attention from the graph machine learning community in recent years, owing to its capability to learn performant node embeddings without costly label information. One weakness of conventional SSL frameworks for GNNs is that they learn through a single philosophy, such as mutual information maximization or generative reconstruction. When applied to various downstream tasks, these frameworks rarely perform equally well for every task, because one philosophy may not span the extensive knowledge required for all tasks. In light of this, we introduce ParetoGNN, a multi-task SSL framework for node representation learning over graphs. Specifically, ParetoGNN is self-supervised by manifold pretext tasks observing multiple philosophies. To reconcile different philosophies, we explore a multiple-gradient descent algorithm, such that ParetoGNN actively learns from every pretext task while minimizing potential conflicts. We conduct comprehensive experiments over four downstream tasks (i.e., node classification, node clustering, link prediction, and partition prediction), and our proposal achieves the best overall performance across tasks on 11 widely adopted benchmark datasets. Besides, we observe that learning from multiple philosophies enhances not only the task generalization but also the single task performance, demonstrating that ParetoGNN achieves better task generalization via the disjoint yet complementary knowledge learned from different philosophies.
Diving into Unified Data-Model Sparsity for Class-Imbalanced Graph Representation Learning
Oct 01, 2022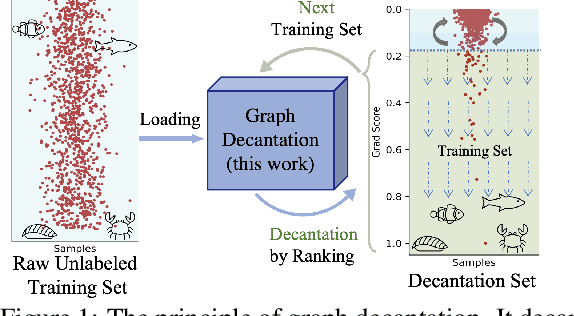
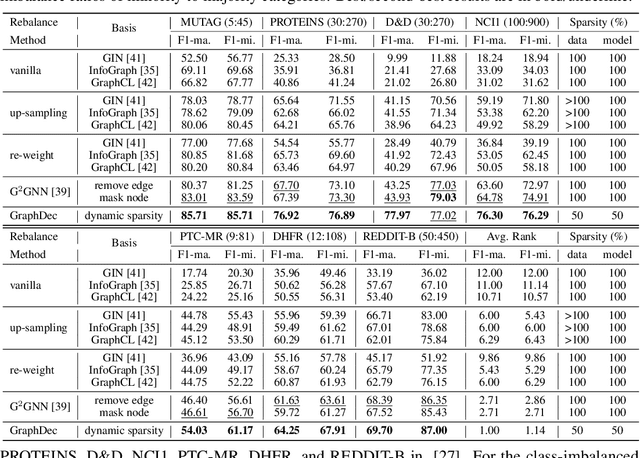
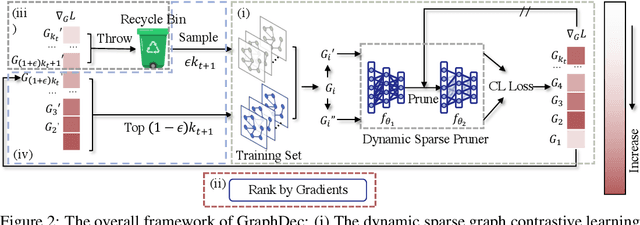
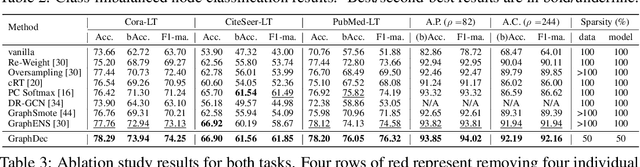
Even pruned by the state-of-the-art network compression methods, Graph Neural Networks (GNNs) training upon non-Euclidean graph data often encounters relatively higher time costs, due to its irregular and nasty density properties, compared with data in the regular Euclidean space. Another natural property concomitantly with graph is class-imbalance which cannot be alleviated by the massive graph data while hindering GNNs' generalization. To fully tackle these unpleasant properties, (i) theoretically, we introduce a hypothesis about what extent a subset of the training data can approximate the full dataset's learning effectiveness. The effectiveness is further guaranteed and proved by the gradients' distance between the subset and the full set; (ii) empirically, we discover that during the learning process of a GNN, some samples in the training dataset are informative for providing gradients to update model parameters. Moreover, the informative subset is not fixed during training process. Samples that are informative in the current training epoch may not be so in the next one. We also notice that sparse subnets pruned from a well-trained GNN sometimes forget the information provided by the informative subset, reflected in their poor performances upon the subset. Based on these findings, we develop a unified data-model dynamic sparsity framework named Graph Decantation (GraphDec) to address challenges brought by training upon a massive class-imbalanced graph data. The key idea of GraphDec is to identify the informative subset dynamically during the training process by adopting sparse graph contrastive learning. Extensive experiments on benchmark datasets demonstrate that GraphDec outperforms baselines for graph and node tasks, with respect to classification accuracy and data usage efficiency.
Adversarial Cross-View Disentangled Graph Contrastive Learning
Sep 16, 2022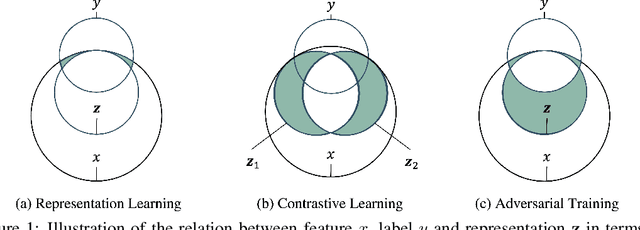
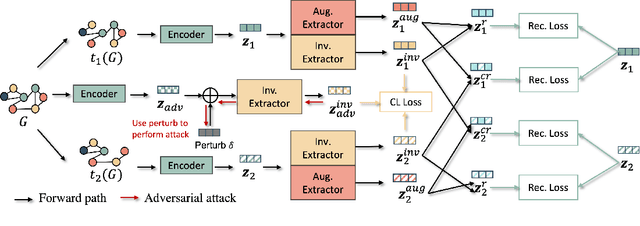

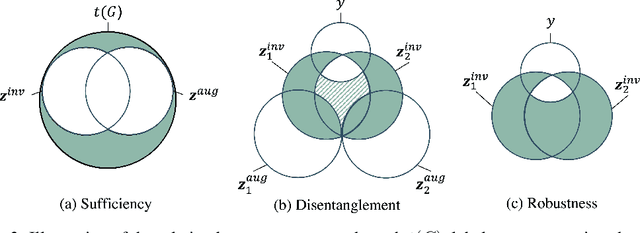
Graph contrastive learning (GCL) is prevalent to tackle the supervision shortage issue in graph learning tasks. Many recent GCL methods have been proposed with various manually designed augmentation techniques, aiming to implement challenging augmentations on the original graph to yield robust representation. Although many of them achieve remarkable performances, existing GCL methods still struggle to improve model robustness without risking losing task-relevant information because they ignore the fact the augmentation-induced latent factors could be highly entangled with the original graph, thus it is more difficult to discriminate the task-relevant information from irrelevant information. Consequently, the learned representation is either brittle or unilluminating. In light of this, we introduce the Adversarial Cross-View Disentangled Graph Contrastive Learning (ACDGCL), which follows the information bottleneck principle to learn minimal yet sufficient representations from graph data. To be specific, our proposed model elicits the augmentation-invariant and augmentation-dependent factors separately. Except for the conventional contrastive loss which guarantees the consistency and sufficiency of the representations across different contrastive views, we introduce a cross-view reconstruction mechanism to pursue the representation disentanglement. Besides, an adversarial view is added as the third view of contrastive loss to enhance model robustness. We empirically demonstrate that our proposed model outperforms the state-of-the-arts on graph classification task over multiple benchmark datasets.
Gophormer: Ego-Graph Transformer for Node Classification
Oct 25, 2021Transformers have achieved remarkable performance in a myriad of fields including natural language processing and computer vision. However, when it comes to the graph mining area, where graph neural network (GNN) has been the dominant paradigm, transformers haven't achieved competitive performance, especially on the node classification task. Existing graph transformer models typically adopt fully-connected attention mechanism on the whole input graph and thus suffer from severe scalability issues and are intractable to train in data insufficient cases. To alleviate these issues, we propose a novel Gophormer model which applies transformers on ego-graphs instead of full-graphs. Specifically, Node2Seq module is proposed to sample ego-graphs as the input of transformers, which alleviates the challenge of scalability and serves as an effective data augmentation technique to boost model performance. Moreover, different from the feature-based attention strategy in vanilla transformers, we propose a proximity-enhanced attention mechanism to capture the fine-grained structural bias. In order to handle the uncertainty introduced by the ego-graph sampling, we further propose a consistency regularization and a multi-sample inference strategy for stabilized training and testing, respectively. Extensive experiments on six benchmark datasets are conducted to demonstrate the superiority of Gophormer over existing graph transformers and popular GNNs, revealing the promising future of graph transformers.