 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLeak: Prompt Leaking Attacks against Large Language Model Applications
May 14, 2024

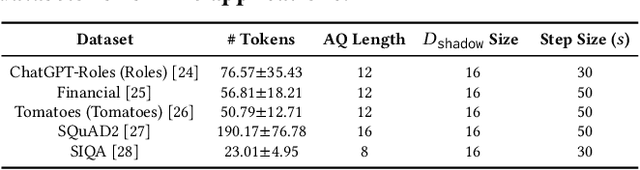
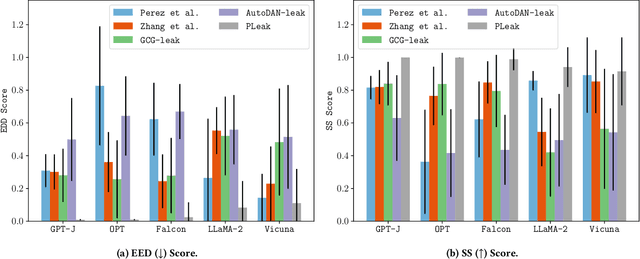
Large Language Models (LLMs) enable a new ecosystem with many downstream applications, called LLM applications, with different natural language processing tasks. The functionality and performance of an LLM application highly depend on its system prompt, which instructs the backend LLM on what task to perform. Therefore, an LLM application developer often keeps a system prompt confidential to protect its intellectual property. As a result, a natural attack, called prompt leaking, is to steal the system prompt from an LLM application, which compromises the developer's intellectual property. Existing prompt leaking attacks primarily rely on manually crafted queries, and thus achieve limited effectiveness. In this paper, we design a novel, closed-box prompt leaking attack framework, called PLeak, to optimize an adversarial query such that when the attacker sends it to a target LLM application, its response reveals its own system prompt. We formulate finding such an adversarial query as an optimization problem and solve it with a gradient-based method approximately. Our key idea is to break down the optimization goal by optimizing adversary queries for system prompts incrementally, i.e., starting from the first few tokens of each system prompt step by step until the entire length of the system prompt. We evaluate PLeak in both offline settings and for real-world LLM applications, e.g., those on Poe, a popular platform hosting such applications. Our results show that PLeak can effectively leak system prompts and significantly outperforms not only baselines that manually curate queries but also baselines with optimized queries that are modified and adapted from existing jailbreaking attacks. We responsibly reported the issues to Poe and are still waiting for their response. Our implementation is available at this repository: https://github.com/BHui97/PLeak.
SneakyPrompt: Jailbreaking Text-to-image Generative Models
May 20, 2023



Text-to-image generative models such as Stable Diffusion and DALL$\cdot$E 2 have attracted much attention since their publication due to their wide application in the real world. One challenging problem of text-to-image generative models is the generation of Not-Safe-for-Work (NSFW) content, e.g., those related to violence and adult. Therefore, a common practice is to deploy a so-called safety filter, which blocks NSFW content based on either text or image features. Prior works have studied the possible bypass of such safety filters. However, existing works are largely manual and specific to Stable Diffusion's official safety filter. Moreover, the bypass ratio of Stable Diffusion's safety filter is as low as 23.51% based on our evaluation. In this paper, we propose the first automated attack framework, called SneakyPrompt, to evaluate the robustness of real-world safety filters in state-of-the-art text-to-image generative models. Our key insight is to search for alternative tokens in a prompt that generates NSFW images so that the generated prompt (called an adversarial prompt) bypasses existing safety filters. Specifically, SneakyPrompt utilizes reinforcement learning (RL) to guide an agent with positive rewards on semantic similarity and bypass success. Our evaluation shows that SneakyPrompt successfully generated NSFW content using an online model DALL$\cdot$E 2 with its default, closed-box safety filter enabled. At the same time, we also deploy several open-source state-of-the-art safety filters on a Stable Diffusion model and show that SneakyPrompt not only successfully generates NSFW content, but also outperforms existing adversarial attacks in terms of the number of queries and image qualities.
Addressing Heterogeneity in Federated Learning via Distributional Transformation
Oct 26, 2022Federated learning (FL) allows multiple clients to collaboratively train a deep learning model. One major challenge of FL is when data distribution is heterogeneous, i.e., differs from one client to another. Existing personalized FL algorithms are only applicable to narrow cases, e.g., one or two data classes per client, and therefore they do not satisfactorily address FL under varying levels of data heterogeneity. In this paper, we propose a novel framework, called DisTrans, to improve FL performance (i.e., model accuracy) via train and test-time distributional transformations along with a double-input-channel model structure. DisTrans works by optimizing distributional offsets and models for each FL client to shift their data distribution, and aggregates these offsets at the FL server to further improve performance in case of distributional heterogeneity. Our evaluation on multiple benchmark datasets shows that DisTrans outperforms state-of-the-art FL methods and data augmentation methods under various settings and different degrees of client distributional heterogeneity.
EdgeMixup: Improving Fairness for Skin Disease Classification and Segmentation
Feb 28, 2022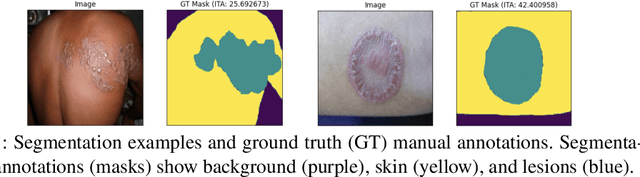
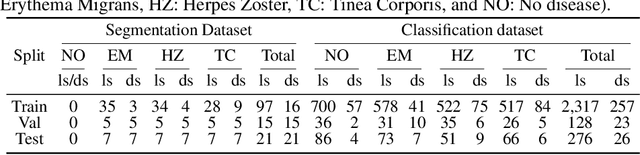


Skin lesions can be an early indicator of a wide range of infectious and other diseases. The use of deep learning (DL) models to diagnose skin lesions has great potential in assisting clinicians with prescreening patients. However, these models often learn biases inherent in training data, which can lead to a performance gap in the diagnosis of people with light and/or dark skin tones. To the best of our knowledge, limited work has been done on identifying, let alone reducing, model bias in skin disease classification and segmentation. In this paper, we examine DL fairness and demonstrate the existence of bias in classification and segmentation models for subpopulations with darker skin tones compared to individuals with lighter skin tones, for specific diseases including Lyme, Tinea Corporis and Herpes Zoster. Then, we propose a novel preprocessing, data alteration method, called EdgeMixup, to improve model fairness with a linear combination of an input skin lesion image and a corresponding a predicted edge detection mask combined with color saturation alteration. For the task of skin disease classification, EdgeMixup outperforms much more complex competing methods such as adversarial approaches, achieving a 10.99% reduction in accuracy gap between light and dark skin tone samples, and resulting in 8.4% improved performance for an underrepresented subpopulation.
Practical Blind Membership Inference Attack via Differential Comparisons
Jan 07, 2021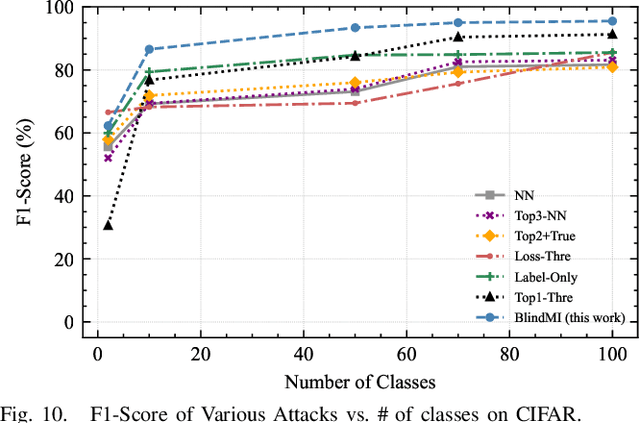
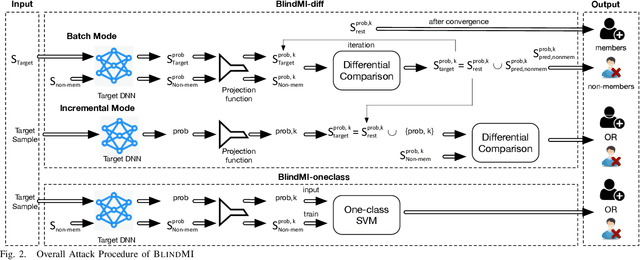
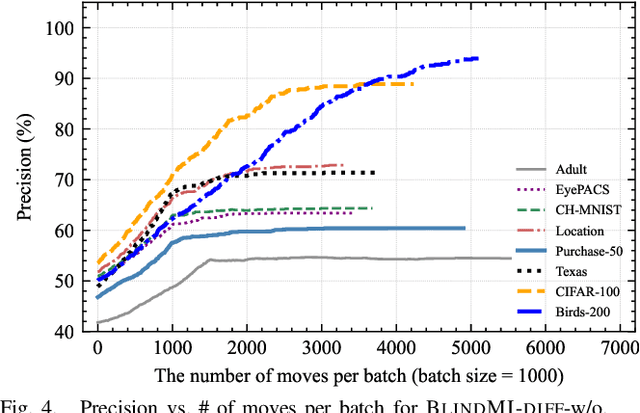
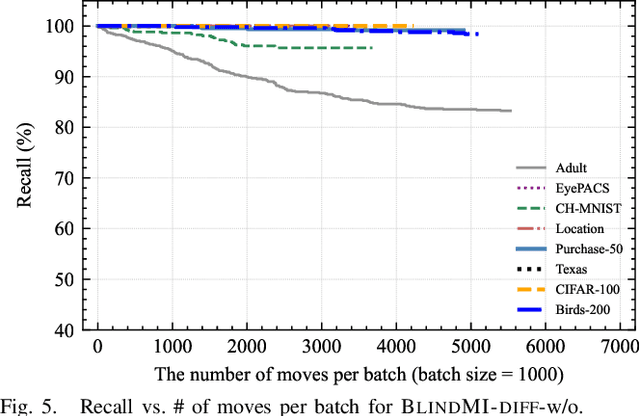
Membership inference (MI) attacks affect user privacy by inferring whether given data samples have been used to train a target learning model, e.g., a deep neural network. There are two types of MI attacks in the literature, i.e., these with and without shadow models. The success of the former heavily depends on the quality of the shadow model, i.e., the transferability between the shadow and the target; the latter, given only blackbox probing access to the target model, cannot make an effective inference of unknowns, compared with MI attacks using shadow models, due to the insufficient number of qualified samples labeled with ground truth membership information. In this paper, we propose an MI attack, called BlindMI, which probes the target model and extracts membership semantics via a novel approach, called differential comparison. The high-level idea is that BlindMI first generates a dataset with nonmembers via transforming existing samples into new samples, and then differentially moves samples from a target dataset to the generated, non-member set in an iterative manner. If the differential move of a sample increases the set distance, BlindMI considers the sample as non-member and vice versa. BlindMI was evaluated by comparing it with state-of-the-art MI attack algorithms. Our evaluation shows that BlindMI improves F1-score by nearly 20% when compared to state-of-the-art on some datasets, such as Purchase-50 and Birds-200, in the blind setting where the adversary does not know the target model's architecture and the target dataset's ground truth labels. We also show that BlindMI can defeat state-of-the-art defenses.