 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudo-Probability Unlearning: Towards Efficient and Privacy-Preserving Machine Unlearning
Paper and Code
Nov 04, 2024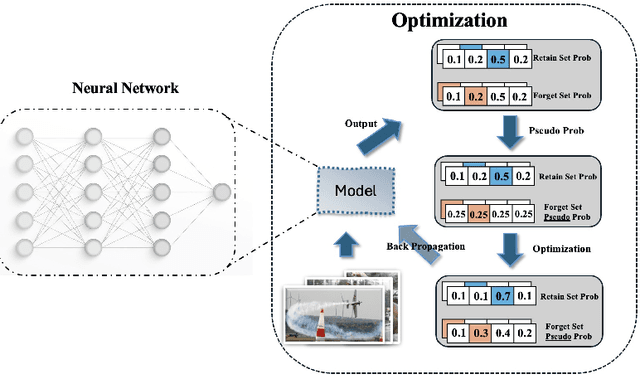
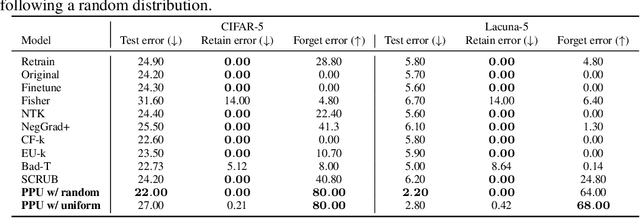
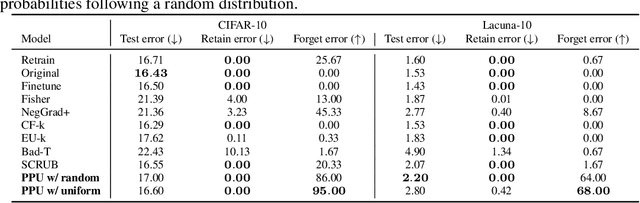
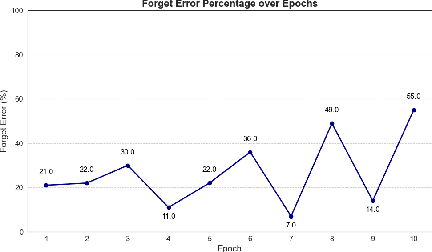
Machine unlearning--enabling a trained model to forget specific data--is crucial for addressing biased data and adhering to privacy regulations like the General Data Protection Regulation (GDPR)'s "right to be forgotten". Recent works have paid little attention to privacy concerns, leaving the data intended for forgetting vulnerable to membership inference attacks. Moreover, they often come with high computational overhead. In this work, we propose Pseudo-Probability Unlearning (PPU), a novel method that enables models to forget data efficiently and in a privacy-preserving manner. Our method replaces the final-layer output probabilities of the neural network with pseudo-probabilities for the data to be forgotten. These pseudo-probabilities follow either a uniform distribution or align with the model's overall distribution, enhancing privacy and reducing risk of membership inference attacks. Our optimization strategy further refines the predictive probability distributions and updates the model's weights accordingly, ensuring effective forgetting with minimal impact on the model's overall performance. Through comprehensive experiments on multiple benchmarks, our method achieves over 20% improvements in forgetting error compared to the state-of-the-art. Additionally, our method enhances privacy by preventing the forgotten set from being inferred to around random guesses.