 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Ordinary Lipschitz Constraints: Differentially Private Stochastic Optimization with Tsybakov Noise Condition
Sep 04, 2025
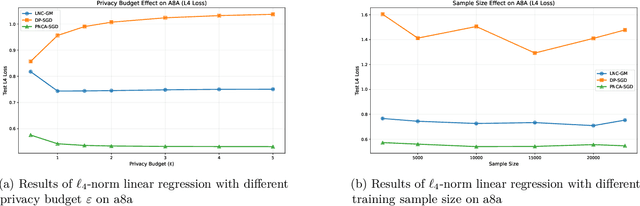
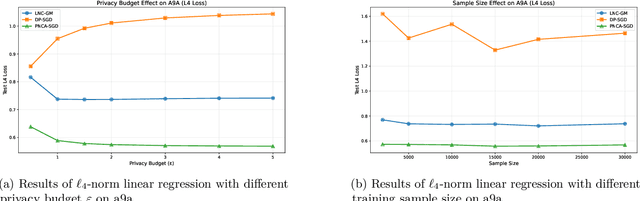
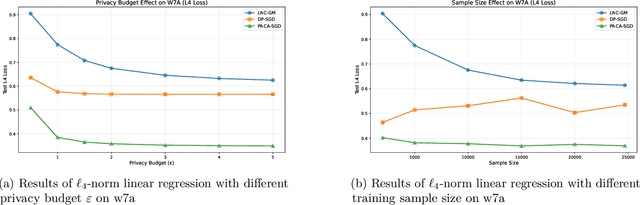
We study Stochastic Convex Optimization in the Differential Privacy model (DP-SCO). Unlike previous studies, here we assume the population risk function satisfies the Tsybakov Noise Condition (TNC) with some parameter $\theta>1$, where the Lipschitz constant of the loss could be extremely large or even unbounded, but the $\ell_2$-norm gradient of the loss has bounded $k$-th moment with $k\geq 2$. For the Lipschitz case with $\theta\geq 2$, we first propose an $(\varepsilon, \delta)$-DP algorithm whose utility bound is $\Tilde{O}\left(\left(\tilde{r}_{2k}(\frac{1}{\sqrt{n}}+(\frac{\sqrt{d}}{n\varepsilon}))^\frac{k-1}{k}\right)^\frac{\theta}{\theta-1}\right)$ in high probability, where $n$ is the sample size, $d$ is the model dimension, and $\tilde{r}_{2k}$ is a term that only depends on the $2k$-th moment of the gradient. It is notable that such an upper bound is independent of the Lipschitz constant. We then extend to the case where $\theta\geq \bar{\theta}> 1$ for some known constant $\bar{\theta}$. Moreover, when the privacy budget $\varepsilon$ is small enough, we show an upper bound of $\tilde{O}\left(\left(\tilde{r}_{k}(\frac{1}{\sqrt{n}}+(\frac{\sqrt{d}}{n\varepsilon}))^\frac{k-1}{k}\right)^\frac{\theta}{\theta-1}\right)$ even if the loss function is not Lipschitz. For the lower bound, we show that for any $\theta\geq 2$, the private minimax rate for $\rho$-zero Concentrated Differential Privacy is lower bounded by $\Omega\left(\left(\tilde{r}_{k}(\frac{1}{\sqrt{n}}+(\frac{\sqrt{d}}{n\sqrt{\rho}}))^\frac{k-1}{k}\right)^\frac{\theta}{\theta-1}\right)$.
FlashDP: Private Training Large Language Models with Efficient DP-SGD
Jul 01, 2025As large language models (LLMs) increasingly underpin technological advancements, the privacy of their training data emerges as a critical concern. Differential Privacy (DP) serves as a rigorous mechanism to protect this data, yet its integration via Differentially Private Stochastic Gradient Descent (DP-SGD) introduces substantial challenges, primarily due to the complexities of per-sample gradient clipping. Current explicit methods, such as Opacus, necessitate extensive storage for per-sample gradients, significantly inflating memory requirements. Conversely, implicit methods like GhostClip reduce storage needs by recalculating gradients multiple times, which leads to inefficiencies due to redundant computations. This paper introduces FlashDP, an innovative cache-friendly per-layer DP-SGD that consolidates necessary operations into a single task, calculating gradients only once in a fused manner. This approach not only diminishes memory movement by up to \textbf{50\%} but also cuts down redundant computations by \textbf{20\%}, compared to previous methods. Consequently, FlashDP does not increase memory demands and achieves a \textbf{90\%} throughput compared to the Non-DP method on a four-A100 system during the pre-training of the Llama-13B model, while maintaining parity with standard per-layer clipped DP-SGD in terms of accuracy. These advancements establish FlashDP as a pivotal development for efficient and privacy-preserving training of LLMs. FlashDP's code has been open-sourced in https://github.com/kaustpradalab/flashdp.
Differentially Private Sparse Linear Regression with Heavy-tailed Responses
Jun 07, 2025



As a fundamental problem in machine learning and differential privacy (DP), DP linear regression has been extensively studied. However, most existing methods focus primarily on either regular data distributions or low-dimensional cases with irregular data. To address these limitations, this paper provides a comprehensive study of DP sparse linear regression with heavy-tailed responses in high-dimensional settings. In the first part, we introduce the DP-IHT-H method, which leverages the Huber loss and private iterative hard thresholding to achieve an estimation error bound of \( \tilde{O}\biggl( s^{* \frac{1 }{2}} \cdot \biggl(\frac{\log d}{n}\biggr)^{\frac{\zeta}{1 + \zeta}} + s^{* \frac{1 + 2\zeta}{2 + 2\zeta}} \cdot \biggl(\frac{\log^2 d}{n \varepsilon}\biggr)^{\frac{\zeta}{1 + \zeta}} \biggr) \) under the $(\varepsilon, \delta)$-DP model, where $n$ is the sample size, $d$ is the dimensionality, $s^*$ is the sparsity of the parameter, and $\zeta \in (0, 1]$ characterizes the tail heaviness of the data. In the second part, we propose DP-IHT-L, which further improves the error bound under additional assumptions on the response and achieves \( \tilde{O}\Bigl(\frac{(s^*)^{3/2} \log d}{n \varepsilon}\Bigr). \) Compared to the first result, this bound is independent of the tail parameter $\zeta$. Finally, through experiments on synthetic and real-world datasets, we demonstrate that our methods outperform standard DP algorithms designed for ``regular'' data.
Towards Lifecycle Unlearning Commitment Management: Measuring Sample-level Unlearning Completeness
Jun 06, 2025Growing concerns over data privacy and security highlight the importance of machine unlearning--removing specific data influences from trained models without full retraining. Techniques like Membership Inference Attacks (MIAs) are widely used to externally assess successful unlearning. However, existing methods face two key limitations: (1) maximizing MIA effectiveness (e.g., via online attacks) requires prohibitive computational resources, often exceeding retraining costs; (2) MIAs, designed for binary inclusion tests, struggle to capture granular changes in approximate unlearning. To address these challenges, we propose the Interpolated Approximate Measurement (IAM), a framework natively designed for unlearning inference. IAM quantifies sample-level unlearning completeness by interpolating the model's generalization-fitting behavior gap on queried samples. IAM achieves strong performance in binary inclusion tests for exact unlearning and high correlation for approximate unlearning--scalable to LLMs using just one pre-trained shadow model. We theoretically analyze how IAM's scoring mechanism maintains performance efficiently. We then apply IAM to recent approximate unlearning algorithms, revealing general risks of both over-unlearning and under-unlearning, underscoring the need for stronger safeguards in approximate unlearning systems. The code is available at https://github.com/Happy2Git/Unlearning_Inference_IAM.
Towards User-level Private Reinforcement Learning with Human Feedback
Feb 22, 2025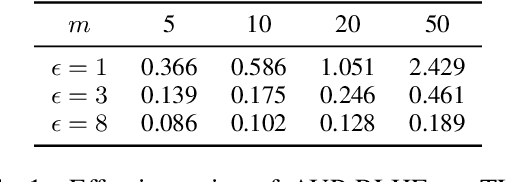
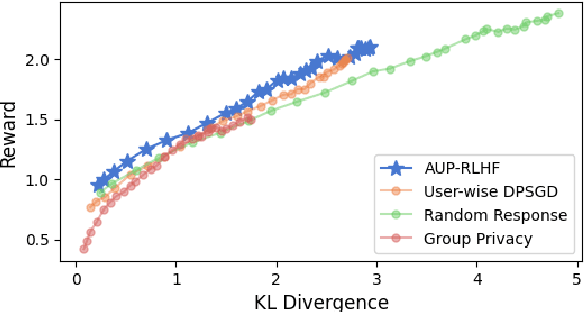

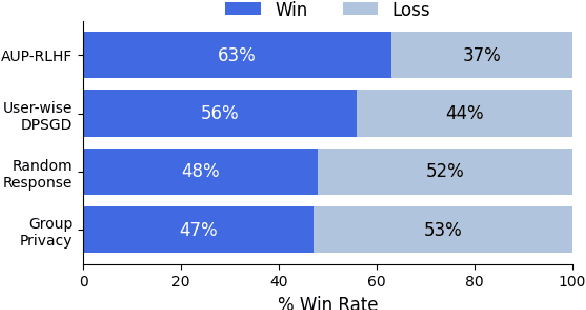
Reinforcement Learning with Human Feedback (RLHF) has emerged as an influential technique, enabling the alignment of large language models (LLMs) with human preferences. Despite the promising potential of RLHF, how to protect user preference privacy has become a crucial issue. Most previous work has focused on using differential privacy (DP) to protect the privacy of individual data. However, they have concentrated primarily on item-level privacy protection and have unsatisfactory performance for user-level privacy, which is more common in RLHF. This study proposes a novel framework, AUP-RLHF, which integrates user-level label DP into RLHF. We first show that the classical random response algorithm, which achieves an acceptable performance in item-level privacy, leads to suboptimal utility when in the user-level settings. We then establish a lower bound for the user-level label DP-RLHF and develop the AUP-RLHF algorithm, which guarantees $(\varepsilon, \delta)$ user-level privacy and achieves an improved estimation error. Experimental results show that AUP-RLHF outperforms existing baseline methods in sentiment generation and summarization tasks, achieving a better privacy-utility trade-off.
Has Approximate Machine Unlearning been evaluated properly? From Auditing to Side Effects
Mar 19, 2024



The growing concerns surrounding data privacy and security have underscored the critical necessity for machine unlearning--aimed at fully removing data lineage from machine learning models. MLaaS providers expect this to be their ultimate safeguard for regulatory compliance. Despite its critical importance, the pace at which privacy communities have been developing and implementing strong methods to verify the effectiveness of machine unlearning has been disappointingly slow, with this vital area often receiving insufficient focus. This paper seeks to address this shortfall by introducing well-defined and effective metrics for black-box unlearning auditing tasks. We transform the auditing challenge into a question of non-membership inference and develop efficient metrics for auditing. By relying exclusively on the original and unlearned models--eliminating the need to train additional shadow models--our approach simplifies the evaluation of unlearning at the individual data point level. Utilizing these metrics, we conduct an in-depth analysis of current approximate machine unlearning algorithms, identifying three key directions where these approaches fall short: utility, resilience, and equity. Our aim is that this work will greatly improve our understanding of approximate machine unlearning methods, taking a significant stride towards converting the theoretical right to data erasure into a auditable reality.
How Does Selection Leak Privacy: Revisiting Private Selection and Improved Results for Hyper-parameter Tuning
Feb 20, 2024



We study the problem of guaranteeing Differential Privacy (DP) in hyper-parameter tuning, a crucial process in machine learning involving the selection of the best run from several. Unlike many private algorithms, including the prevalent DP-SGD, the privacy implications of tuning remain insufficiently understood. Recent works propose a generic private solution for the tuning process, yet a fundamental question still persists: is the current privacy bound for this solution tight? This paper contributes both positive and negative answers to this question. Initially, we provide studies affirming the current privacy analysis is indeed tight in a general sense. However, when we specifically study the hyper-parameter tuning problem, such tightness no longer holds. This is first demonstrated by applying privacy audit on the tuning process. Our findings underscore a substantial gap between the current theoretical privacy bound and the empirical bound derived even under the strongest audit setup. The gap found is not a fluke. Our subsequent study provides an improved privacy result for private hyper-parameter tuning due to its distinct properties. Our privacy results are also more generalizable compared to prior analyses that are only easily applicable in specific setups.
Preserving Node-level Privacy in Graph Neural Networks
Nov 12, 2023



Differential privacy (DP) has seen immense applications in learning on tabular, image, and sequential data where instance-level privacy is concerned. In learning on graphs, contrastingly, works on node-level privacy are highly sparse. Challenges arise as existing DP protocols hardly apply to the message-passing mechanism in Graph Neural Networks (GNNs). In this study, we propose a solution that specifically addresses the issue of node-level privacy. Our protocol consists of two main components: 1) a sampling routine called HeterPoisson, which employs a specialized node sampling strategy and a series of tailored operations to generate a batch of sub-graphs with desired properties, and 2) a randomization routine that utilizes symmetric multivariate Laplace (SML) noise instead of the commonly used Gaussian noise. Our privacy accounting shows this particular combination provides a non-trivial privacy guarantee. In addition, our protocol enables GNN learning with good performance, as demonstrated by experiments on five real-world datasets; compared with existing baselines, our method shows significant advantages, especially in the high privacy regime. Experimentally, we also 1) perform membership inference attacks against our protocol and 2) apply privacy audit techniques to confirm our protocol's privacy integrity. In the sequel, we present a study on a seemingly appealing approach \cite{sajadmanesh2023gap} (USENIX'23) that protects node-level privacy via differentially private node/instance embeddings. Unfortunately, such work has fundamental privacy flaws, which are identified through a thorough case study. More importantly, we prove an impossibility result of achieving both (strong) privacy and (acceptable) utility through private instance embedding. The implication is that such an approach has intrinsic utility barriers when enforcing differential privacy.
Differentially Private Non-convex Learning for Multi-layer Neural Networks
Oct 12, 2023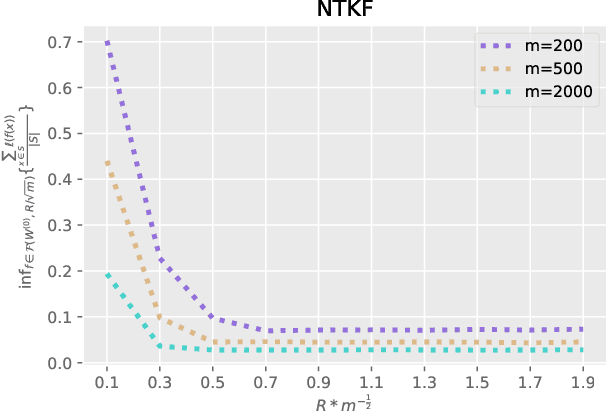
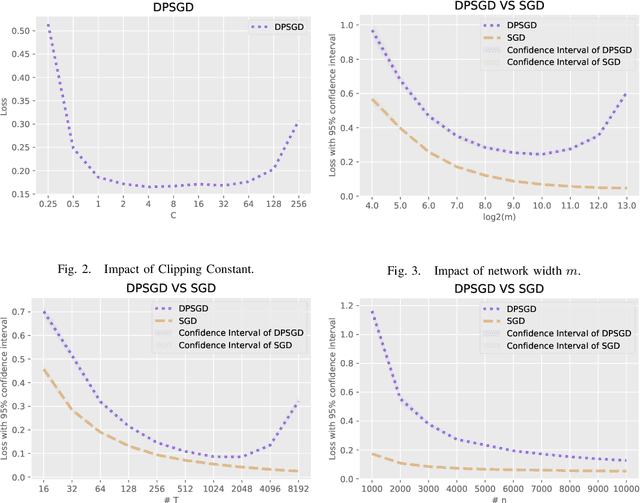
This paper focuses on the problem of Differentially Private Stochastic Optimization for (multi-layer) fully connected neural networks with a single output node. In the first part, we examine cases with no hidden nodes, specifically focusing on Generalized Linear Models (GLMs). We investigate the well-specific model where the random noise possesses a zero mean, and the link function is both bounded and Lipschitz continuous. We propose several algorithms and our analysis demonstrates the feasibility of achieving an excess population risk that remains invariant to the data dimension. We also delve into the scenario involving the ReLU link function, and our findings mirror those of the bounded link function. We conclude this section by contrasting well-specified and misspecified models, using ReLU regression as a representative example. In the second part of the paper, we extend our ideas to two-layer neural networks with sigmoid or ReLU activation functions in the well-specified model. In the third part, we study the theoretical guarantees of DP-SGD in Abadi et al. (2016) for fully connected multi-layer neural networks. By utilizing recent advances in Neural Tangent Kernel theory, we provide the first excess population risk when both the sample size and the width of the network are sufficiently large. Additionally, we discuss the role of some parameters in DP-SGD regarding their utility, both theoretically and empirically.
Practical Differentially Private and Byzantine-resilient Federated Learning
Apr 15, 2023Privacy and Byzantine resilience are two indispensable requirements for a federated learning (FL) system. Although there have been extensive studies on privacy and Byzantine security in their own track, solutions that consider both remain sparse. This is due to difficulties in reconciling privacy-preserving and Byzantine-resilient algorithms. In this work, we propose a solution to such a two-fold issue. We use our version of differentially private stochastic gradient descent (DP-SGD) algorithm to preserve privacy and then apply our Byzantine-resilient algorithms. We note that while existing works follow this general approach, an in-depth analysis on the interplay between DP and Byzantine resilience has been ignored, leading to unsatisfactory performance. Specifically, for the random noise introduced by DP, previous works strive to reduce its impact on the Byzantine aggregation. In contrast, we leverage the random noise to construct an aggregation that effectively rejects many existing Byzantine attacks. We provide both theoretical proof and empirical experiments to show our protocol is effective: retaining high accuracy while preserving the DP guarantee and Byzantine resilience. Compared with the previous work, our protocol 1) achieves significantly higher accuracy even in a high privacy regime; 2) works well even when up to 90% of distributive workers are Byzantine.