 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEVDistill: Cross-Modal BEV Distillation for Multi-View 3D Object Detection
Nov 17, 2022
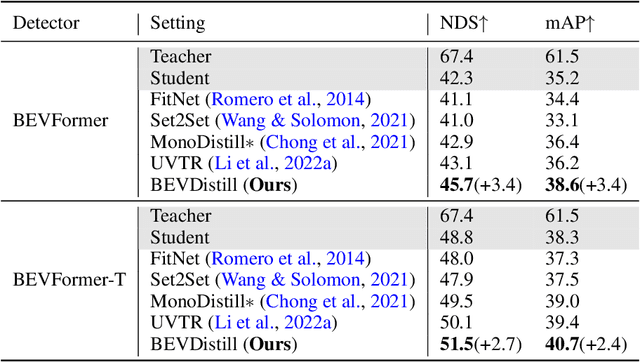


3D object detection from multiple image views is a fundamental and challenging task for visual scene understanding. Owing to its low cost and high efficiency, multi-view 3D object detection has demonstrated promising application prospects. However, accurately detecting objects through perspective views is extremely difficult due to the lack of depth information. Current approaches tend to adopt heavy backbones for image encoders, making them inapplicable for real-world deployment. Different from the images, LiDAR points are superior in providing spatial cues, resulting in highly precise localization. In this paper, we explore the incorporation of LiDAR-based detectors for multi-view 3D object detection. Instead of directly training a depth prediction network, we unify the image and LiDAR features in the Bird-Eye-View (BEV) space and adaptively transfer knowledge across non-homogenous representations in a teacher-student paradigm. To this end, we propose \textbf{BEVDistill}, a cross-modal BEV knowledge distillation (KD) framework for multi-view 3D object detection. Extensive experiments demonstrate that the proposed method outperforms current KD approaches on a highly-competitive baseline, BEVFormer, without introducing any extra cost in the inference phase. Notably, our best model achieves 59.4 NDS on the nuScenes test leaderboard, achieving new state-of-the-art in comparison with various image-based detectors. Code will be available at https://github.com/zehuichen123/BEVDistill.
AutoAlignV2: Deformable Feature Aggregation for Dynamic Multi-Modal 3D Object Detection
Jul 21, 2022



Point clouds and RGB images are two general perceptional sources in autonomous driving. The former can provide accurate localization of objects, and the latter is denser and richer in semantic information. Recently, AutoAlign presents a learnable paradigm in combining these two modalities for 3D object detection. However, it suffers from high computational cost introduced by the global-wise attention. To solve the problem, we propose Cross-Domain DeformCAFA module in this work. It attends to sparse learnable sampling points for cross-modal relational modeling, which enhances the tolerance to calibration error and greatly speeds up the feature aggregation across different modalities. To overcome the complex GT-AUG under multi-modal settings, we design a simple yet effective cross-modal augmentation strategy on convex combination of image patches given their depth information. Moreover, by carrying out a novel image-level dropout training scheme, our model is able to infer in a dynamic manner. To this end, we propose AutoAlignV2, a faster and stronger multi-modal 3D detection framework, built on top of AutoAlign. Extensive experiments on nuScenes benchmark demonstrate the effectiveness and efficiency of AutoAlignV2. Notably, our best model reaches 72.4 NDS on nuScenes test leaderboard, achieving new state-of-the-art results among all published multi-modal 3D object detectors. Code will be available at https://github.com/zehuichen123/AutoAlignV2.
Towards Model Generalization for Monocular 3D Object Detection
May 28, 2022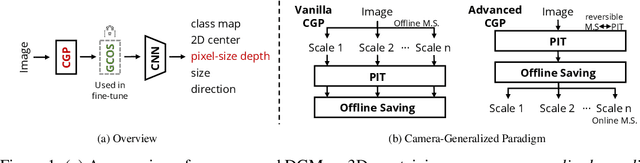

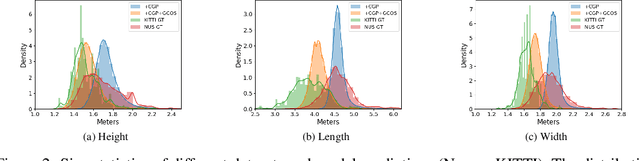

Monocular 3D object detection (Mono3D) has achieved tremendous improvements with emerging large-scale autonomous driving datasets and the rapid development of deep learning techniques. However, caused by severe domain gaps (e.g., the field of view (FOV), pixel size, and object size among datasets), Mono3D detectors have difficulty in generalization, leading to drastic performance degradation on unseen domains. To solve these issues, we combine the position-invariant transform and multi-scale training with the pixel-size depth strategy to construct an effective unified camera-generalized paradigm (CGP). It fully considers discrepancies in the FOV and pixel size of images captured by different cameras. Moreover, we further investigate the obstacle in quantitative metrics when cross-dataset inference through an exhaustive systematic study. We discern that the size bias of prediction leads to a colossal failure. Hence, we propose the 2D-3D geometry-consistent object scaling strategy (GCOS) to bridge the gap via an instance-level augment. Our method called DGMono3D achieves remarkable performance on all evaluated datasets and surpasses the SoTA unsupervised domain adaptation scheme even without utilizing data on the target domain.
Unsupervised Domain Adaptation for Monocular 3D Object Detection via Self-Training
Apr 27, 2022



Monocular 3D object detection (Mono3D) has achieved unprecedented success with the advent of deep learning techniques and emerging large-scale autonomous driving datasets. However, drastic performance degradation remains an unwell-studied challenge for practical cross-domain deployment as the lack of labels on the target domain. In this paper, we first comprehensively investigate the significant underlying factor of the domain gap in Mono3D, where the critical observation is a depth-shift issue caused by the geometric misalignment of domains. Then, we propose STMono3D, a new self-teaching framework for unsupervised domain adaptation on Mono3D. To mitigate the depth-shift, we introduce the geometry-aligned multi-scale training strategy to disentangle the camera parameters and guarantee the geometry consistency of domains. Based on this, we develop a teacher-student paradigm to generate adaptive pseudo labels on the target domain. Benefiting from the end-to-end framework that provides richer information of the pseudo labels, we propose the quality-aware supervision strategy to take instance-level pseudo confidences into account and improve the effectiveness of the target-domain training process. Moreover, the positive focusing training strategy and dynamic threshold are proposed to handle tremendous FN and FP pseudo samples. STMono3D achieves remarkable performance on all evaluated datasets and even surpasses fully supervised results on the KITTI 3D object detection dataset. To the best of our knowledge, this is the first study to explore effective UDA methods for Mono3D.
Graph-DETR3D: Rethinking Overlapping Regions for Multi-View 3D Object Detection
Apr 26, 2022
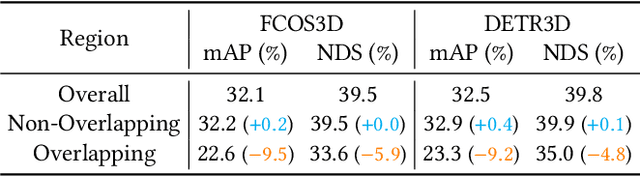


3D object detection from multiple image views is a fundamental and challenging task for visual scene understanding. Due to its low cost and high efficiency, multi-view 3D object detection has demonstrated promising application prospects. However, accurately detecting objects through perspective views in the 3D space is extremely difficult due to the lack of depth information. Recently, DETR3D introduces a novel 3D-2D query paradigm in aggregating multi-view images for 3D object detection and achieves state-of-the-art performance. In this paper, with intensive pilot experiments, we quantify the objects located at different regions and find that the "truncated instances" (i.e., at the border regions of each image) are the main bottleneck hindering the performance of DETR3D. Although it merges multiple features from two adjacent views in the overlapping regions, DETR3D still suffers from insufficient feature aggregation, thus missing the chance to fully boost the detection performance. In an effort to tackle the problem, we propose Graph-DETR3D to automatically aggregate multi-view imagery information through graph structure learning (GSL). It constructs a dynamic 3D graph between each object query and 2D feature maps to enhance the object representations, especially at the border regions. Besides, Graph-DETR3D benefits from a novel depth-invariant multi-scale training strategy, which maintains the visual depth consistency by simultaneously scaling the image size and the object depth. Extensive experiments on the nuScenes dataset demonstrate the effectiveness and efficiency of our Graph-DETR3D. Notably, our best model achieves 49.5 NDS on the nuScenes test leaderboard, achieving new state-of-the-art in comparison with various published image-view 3D object detectors.
AutoAlign: Pixel-Instance Feature Aggregation for Multi-Modal 3D Object Detection
Jan 17, 2022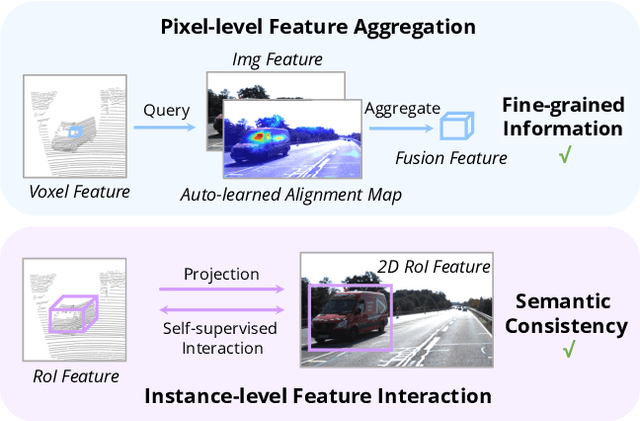
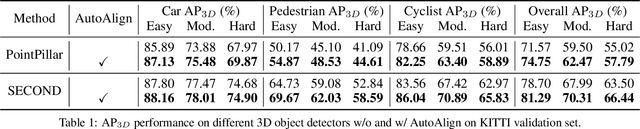
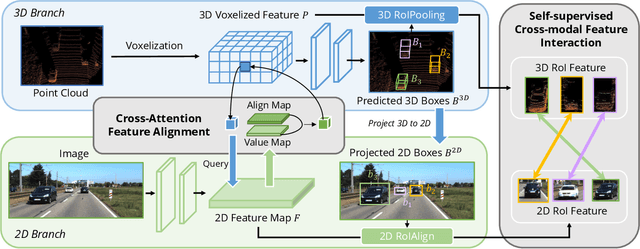

Object detection through either RGB images or the LiDAR point clouds has been extensively explored in autonomous driving. However, it remains challenging to make these two data sources complementary and beneficial to each other. In this paper, we propose \textit{AutoAlign}, an automatic feature fusion strategy for 3D object detection. Instead of establishing deterministic correspondence with camera projection matrix, we model the mapping relationship between the image and point clouds with a learnable alignment map. This map enables our model to automate the alignment of non-homogenous features in a dynamic and data-driven manner. Specifically, a cross-attention feature alignment module is devised to adaptively aggregate \textit{pixel-level} image features for each voxel. To enhance the semantic consistency during feature alignment, we also design a self-supervised cross-modal feature interaction module, through which the model can learn feature aggregation with \textit{instance-level} feature guidance. Extensive experimental results show that our approach can lead to 2.3 mAP and 7.0 mAP improvements on the KITTI and nuScenes datasets, respectively. Notably, our best model reaches 70.9 NDS on the nuScenes testing leaderboard, achieving competitive performance among various state-of-the-arts.
SimIPU: Simple 2D Image and 3D Point Cloud Unsupervised Pre-Training for Spatial-Aware Visual Representations
Dec 09, 2021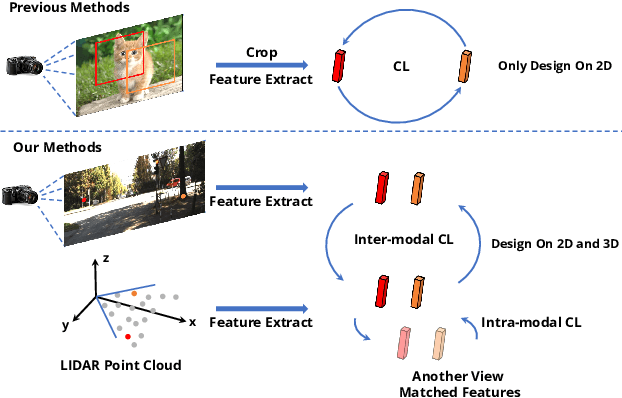



Pre-training has become a standard paradigm in many computer vision tasks. However, most of the methods are generally designed on the RGB image domain. Due to the discrepancy between the two-dimensional image plane and the three-dimensional space, such pre-trained models fail to perceive spatial information and serve as sub-optimal solutions for 3D-related tasks. To bridge this gap, we aim to learn a spatial-aware visual representation that can describe the three-dimensional space and is more suitable and effective for these tasks. To leverage point clouds, which are much more superior in providing spatial information compared to images, we propose a simple yet effective 2D Image and 3D Point cloud Unsupervised pre-training strategy, called SimIPU. Specifically, we develop a multi-modal contrastive learning framework that consists of an intra-modal spatial perception module to learn a spatial-aware representation from point clouds and an inter-modal feature interaction module to transfer the capability of perceiving spatial information from the point cloud encoder to the image encoder, respectively. Positive pairs for contrastive losses are established by the matching algorithm and the projection matrix. The whole framework is trained in an unsupervised end-to-end fashion. To the best of our knowledge, this is the first study to explore contrastive learning pre-training strategies for outdoor multi-modal datasets, containing paired camera images and LIDAR point clouds. Codes and models are available at https://github.com/zhyever/SimIPU.
Multimodal Motion Prediction with Stacked Transformers
Mar 24, 2021
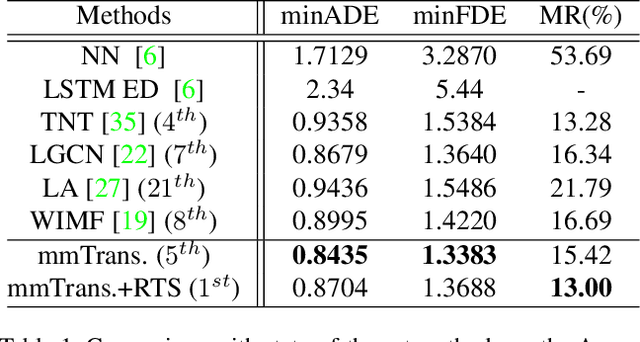


Predicting multiple plausible future trajectories of the nearby vehicles is crucial for the safety of autonomous driving. Recent motion prediction approaches attempt to achieve such multimodal motion prediction by implicitly regularizing the feature or explicitly generating multiple candidate proposals. However, it remains challenging since the latent features may concentrate on the most frequent mode of the data while the proposal-based methods depend largely on the prior knowledge to generate and select the proposals. In this work, we propose a novel transformer framework for multimodal motion prediction, termed as mmTransformer. A novel network architecture based on stacked transformers is designed to model the multimodality at feature level with a set of fixed independent proposals. A region-based training strategy is then developed to induce the multimodality of the generated proposals. Experiments on Argoverse dataset show that the proposed model achieves the state-of-the-art performance on motion prediction, substantially improving the diversity and the accuracy of the predicted trajectories. Demo video and code are available at https://decisionforce.github.io/mmTransformer.
TPNet: Trajectory Proposal Network for Motion Prediction
Apr 26, 2020



Making accurate motion prediction of the surrounding traffic agents such as pedestrians, vehicles, and cyclists is crucial for autonomous driving. Recent data-driven motion prediction methods have attempted to learn to directly regress the exact future position or its distribution from massive amount of trajectory data. However, it remains difficult for these methods to provide multimodal predictions as well as integrate physical constraints such as traffic rules and movable areas. In this work we propose a novel two-stage motion prediction framework, Trajectory Proposal Network (TPNet). TPNet first generates a candidate set of future trajectories as hypothesis proposals, then makes the final predictions by classifying and refining the proposals which meets the physical constraints. By steering the proposal generation process, safe and multimodal predictions are realized. Thus this framework effectively mitigates the complexity of motion prediction problem while ensuring the multimodal output. Experiments on four large-scale trajectory prediction datasets, i.e. the ETH, UCY, Apollo and Argoverse datasets, show that TPNet achieves the state-of-the-art results both quantitatively and qualitatively.
EdgeStereo: An Effective Multi-Task Learning Network for Stereo Matching and Edge Detection
Mar 05, 2019
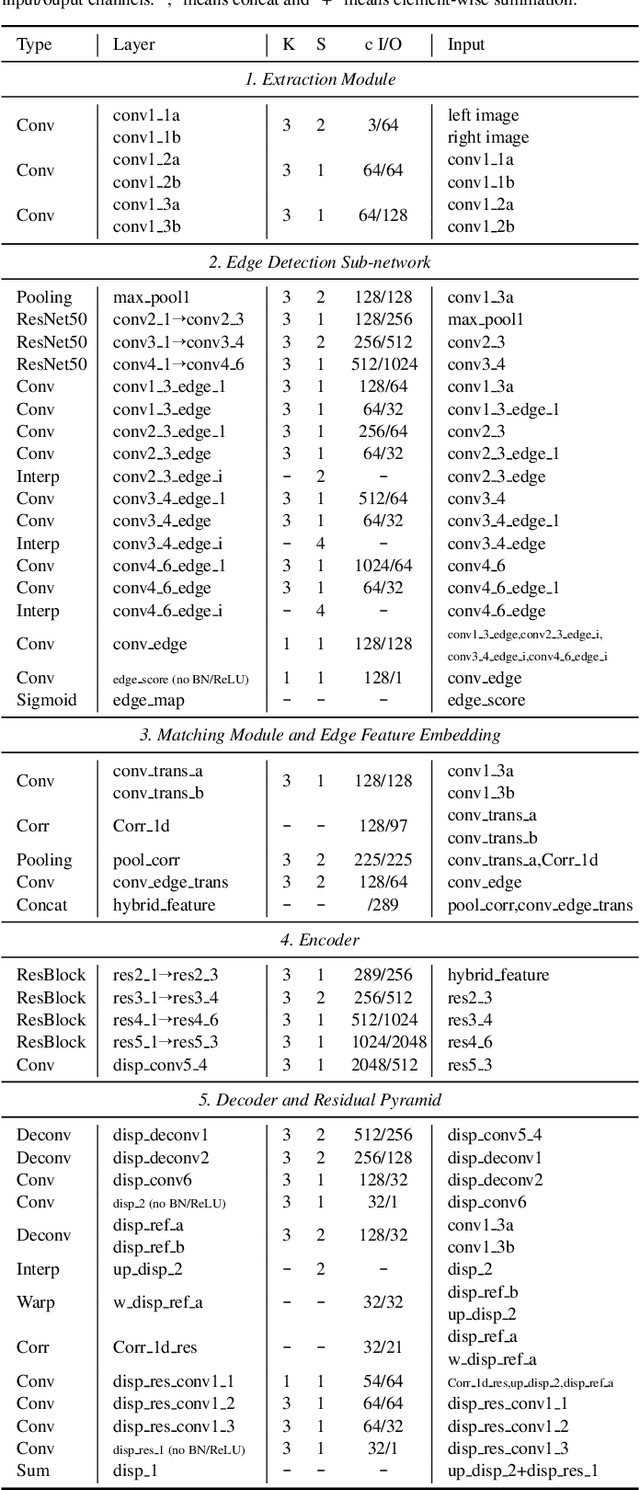
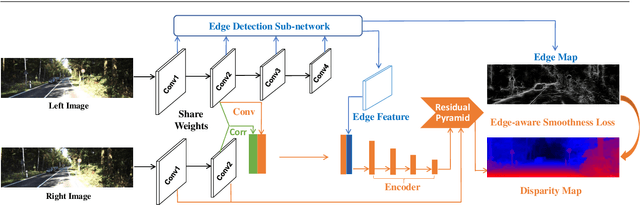

Recently, leveraging on the development of end-to-end convolutional neural networks, deep stereo matching networks achieve remarkable performance far exceeding traditional approaches. However, state-of-the-art stereo methods still have difficulties finding correct correspondences in texture-less regions, detailed structures, small objects and near boundaries, which could be alleviated by geometric clues such as edge contours and corresponding constraints. To improve the quality of disparity estimates in these challenging areas, we propose an effective multi-task learning network EdgeStereo composed of a disparity estimation sub-network and an edge detection sub-network, which enables end-to-end predictions of both disparity map and edge map. To effectively incorporates edge cues, we propose the edge-aware smoothness loss and edge feature embedding for inter-task interactions. It is demonstrated that based on our unified model, edge detection task and stereo matching task can promote each other. In addition, we design a compact module called residual pyramid to replace the commonly-used multi-stage cascaded structures or 3-D convolution based regularization modules in current stereo matching networks. By the time of the paper submission, EdgeStereo achieves state-of-the-art performance on the FlyingThings3D dataset, KITTI 2012 and KITTI 2015 stereo benchmarks, outperforming other published stereo matching methods by a noteworthy margin. EdgeStereo also has a better generalization capability for disparity estimation because of the incorporation of edge cues.