 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-DETR3D: Rethinking Overlapping Regions for Multi-View 3D Object Detection
Paper and Code
Apr 26, 2022
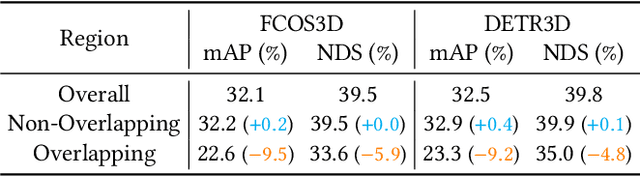


3D object detection from multiple image views is a fundamental and challenging task for visual scene understanding. Due to its low cost and high efficiency, multi-view 3D object detection has demonstrated promising application prospects. However, accurately detecting objects through perspective views in the 3D space is extremely difficult due to the lack of depth information. Recently, DETR3D introduces a novel 3D-2D query paradigm in aggregating multi-view images for 3D object detection and achieves state-of-the-art performance. In this paper, with intensive pilot experiments, we quantify the objects located at different regions and find that the "truncated instances" (i.e., at the border regions of each image) are the main bottleneck hindering the performance of DETR3D. Although it merges multiple features from two adjacent views in the overlapping regions, DETR3D still suffers from insufficient feature aggregation, thus missing the chance to fully boost the detection performance. In an effort to tackle the problem, we propose Graph-DETR3D to automatically aggregate multi-view imagery information through graph structure learning (GSL). It constructs a dynamic 3D graph between each object query and 2D feature maps to enhance the object representations, especially at the border regions. Besides, Graph-DETR3D benefits from a novel depth-invariant multi-scale training strategy, which maintains the visual depth consistency by simultaneously scaling the image size and the object depth. Extensive experiments on the nuScenes dataset demonstrate the effectiveness and efficiency of our Graph-DETR3D. Notably, our best model achieves 49.5 NDS on the nuScenes test leaderboard, achieving new state-of-the-art in comparison with various published image-view 3D object detectors.