 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysProver: Advancing Automatic Theorem Proving for Physics
Jan 22, 2026The combination of verifiable languages and LLMs has significantly influenced both the mathematical and computer science communities because it provides a rigorous foundation for theorem proving. Recent advancements in the field provide foundation models and sophisticated agentic systems pushing the boundaries of formal mathematical reasoning to approach the natural language capability of LLMs. However, little attention has been given to the formal physics reasoning, which also heavily relies on similar problem-solving and theorem-proving frameworks. To solve this problem, this paper presents, to the best of our knowledge, the first approach to enhance formal theorem proving in the physics domain. We compose a dedicated dataset PhysLeanData for the task. It is composed of theorems sampled from PhysLean and data generated by a conjecture-based formal data generation pipeline. In the training pipeline, we leverage DeepSeek-Prover-V2-7B, a strong open-source mathematical theorem prover, and apply Reinforcement Learning with Verifiable Rewards (RLVR) to train our model PhysProver. Comprehensive experiments demonstrate that, using only $\sim$5K training samples, PhysProver achieves an overall 2.4\% improvement in multiple sub-domains. Furthermore, after formal physics training, we observe 1.3\% gains on the MiniF2F-Test benchmark, which indicates non-trivial generalization beyond physics domains and enhancement for formal math capability as well. The results highlight the effectiveness and efficiency of our approach, which provides a paradigm for extending formal provers outside mathematical domains. To foster further research, we will release both our dataset and model to the community.
Generalizable Geometric Image Caption Synthesis
Sep 18, 2025Multimodal large language models have various practical applications that demand strong reasoning abilities. Despite recent advancements, these models still struggle to solve complex geometric problems. A key challenge stems from the lack of high-quality image-text pair datasets for understanding geometric images. Furthermore, most template-based data synthesis pipelines typically fail to generalize to questions beyond their predefined templates. In this paper, we bridge this gap by introducing a complementary process of Reinforcement Learning with Verifiable Rewards (RLVR) into the data generation pipeline. By adopting RLVR to refine captions for geometric images synthesized from 50 basic geometric relations and using reward signals derived from mathematical problem-solving tasks, our pipeline successfully captures the key features of geometry problem-solving. This enables better task generalization and yields non-trivial improvements. Furthermore, even in out-of-distribution scenarios, the generated dataset enhances the general reasoning capabilities of multimodal large language models, yielding accuracy improvements of $2.8\%\text{-}4.8\%$ in statistics, arithmetic, algebraic, and numerical tasks with non-geometric input images of MathVista and MathVerse, along with $2.4\%\text{-}3.9\%$ improvements in Art, Design, Tech, and Engineering tasks in MMMU.
Multimodal Needle in a Haystack: Benchmarking Long-Context Capability of Multimodal Large Language Models
Jun 17, 2024



Multimodal Large Language Models (MLLMs) have shown significant promise in various applications, leading to broad interest from researchers and practitioners alike. However, a comprehensive evaluation of their long-context capabilities remains underexplored. To address these gaps, we introduce the MultiModal Needle-in-a-haystack (MMNeedle) benchmark, specifically designed to assess the long-context capabilities of MLLMs. Besides multi-image input, we employ image stitching to further increase the input context length, and develop a protocol to automatically generate labels for sub-image level retrieval. Essentially, MMNeedle evaluates MLLMs by stress-testing their capability to locate a target sub-image (needle) within a set of images (haystack) based on textual instructions and descriptions of image contents. This setup necessitates an advanced understanding of extensive visual contexts and effective information retrieval within long-context image inputs. With this benchmark, we evaluate state-of-the-art MLLMs, encompassing both API-based and open-source models. The findings reveal that GPT-4o consistently surpasses other models in long-context scenarios, but suffers from hallucination problems in negative samples, i.e., when needles are not in the haystacks. Our comprehensive long-context evaluation of MLLMs also sheds lights on the considerable performance gap between API-based and open-source models. All the code, data, and instructions required to reproduce the main results are available at https://github.com/Wang-ML-Lab/multimodal-needle-in-a-haystack.
Multi-Vehicle Trajectory Planning at V2I-enabled Intersections based on Correlated Equilibrium
Jun 08, 2024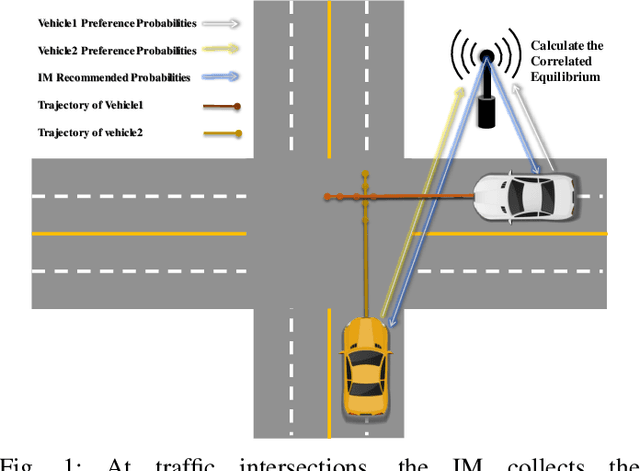

Generating trajectories that ensure both vehicle safety and improve traffic efficiency remains a challenging task at intersections. Many existing works utilize Nash equilibrium (NE) for the trajectory planning at intersections. However, NE-based planning can hardly guarantee that all vehicles are in the same equilibrium, leading to a risk of collision. In this work, we propose a framework for trajectory planning based on Correlated Equilibrium (CE) when V2I communication is also enabled. The recommendation with CE allows all vehicles to reach a safe and consensual equilibrium and meanwhile keeps the rationality as NE-based methods that no vehicle has the incentive to deviate. The Intersection Manager (IM) first collects the trajectory library and the personal preference probabilities over the library from each vehicle in a low-resolution spatial-temporal grid map. Then, the IM optimizes the recommendation probability distribution for each vehicle's trajectory by minimizing overall collision probability under the CE constraint. Finally, each vehicle samples a trajectory of the low-resolution map to construct a safety corridor and derive a smooth trajectory with a local refinement optimization. We conduct comparative experiments at a crossroad intersection involving two and four vehicles, validating the effectiveness of our method in balancing vehicle safety and traffic efficiency.
Continual Learning of Large Language Models: A Comprehensive Survey
Apr 25, 2024



The recent success of large language models (LLMs) trained on static, pre-collected, general datasets has sparked numerous research directions and applications. One such direction addresses the non-trivial challenge of integrating pre-trained LLMs into dynamic data distributions, task structures, and user preferences. Pre-trained LLMs, when tailored for specific needs, often experience significant performance degradation in previous knowledge domains -- a phenomenon known as "catastrophic forgetting". While extensively studied in the continual learning (CL) community, it presents new manifestations in the realm of LLMs. In this survey, we provide a comprehensive overview of the current research progress on LLMs within the context of CL. This survey is structured into four main sections: we first describe an overview of continually learning LLMs, consisting of two directions of continuity: vertical continuity (or vertical continual learning), i.e., continual adaptation from general to specific capabilities, and horizontal continuity (or horizontal continual learning), i.e., continual adaptation across time and domains (Section 3). We then summarize three stages of learning LLMs in the context of modern CL: Continual Pre-Training (CPT), Domain-Adaptive Pre-training (DAP), and Continual Fine-Tuning (CFT) (Section 4). Then we provide an overview of evaluation protocols for continual learning with LLMs, along with the current available data sources (Section 5). Finally, we discuss intriguing questions pertaining to continual learning for LLMs (Section 6). The full list of papers examined in this survey is available at https://github.com/Wang-ML-Lab/llm-continual-learning-survey.