 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaking Up Blind: Cold-Start Optimization of Supervision-Free Agentic Trajectories for Grounded Visual Perception
Apr 19, 2026Small Vision-Language Models (SVLMs) are efficient task controllers but often suffer from visual brittleness and poor tool orchestration. They typically require expensive supervised trajectory tuning to mitigate these deficits. In this work, we propose Self-supervised Perception Enabled by Cascaded Tool Rollout Alignment (SPECTRA), a supervision-free framework that bootstraps agentic capabilities via Coldstart Reinforcement Learning for SVLMs. SPECTRA enforces Soft Structured Multi-turn Rollouts, a topological constraint that directs agents to explicitly sequence tool derived evidence before synthesis, effectively grounding reasoning in visual observations. We employ a multi-objective reward signal that simultaneously maximizes task correctness, rollout structure, and tool utility, enabling agent to self-discover robust behaviors without human preference labels. We further introduce Tool Instrumental Utility (TIU), a novel metric to quantify tool efficacy in the absence of ground truth. Extensive evaluations across composite and out-of-distribution (MMMU-Pro) benchmarks demonstrate that SPECTRA boosts agentic trajectories, improving task accuracy by up to 5% and tool efficiency by 9%, enabling more efficient multimodal agents that learn effectively from environmental interaction alone.
AutoAdapt: An Automated Domain Adaptation Framework for LLMs
Mar 09, 2026Large language models (LLMs) excel in open domains but struggle in specialized settings with limited data and evolving knowledge. Existing domain adaptation practices rely heavily on manual trial-and-error processes, incur significant hyperparameter complexity, and are highly sensitive to data and user preferences, all under the high cost of LLM training. Moreover, the interactions and transferability of hyperparameter choices across models/domains remain poorly understood, making adaptation gains uncertain even with substantial effort. To solve these challenges, we present AutoAdapt, a novel end-to-end automated framework for efficient and reliable LLM domain adaptation. AutoAdapt leverages curated knowledge bases from literature and open-source resources to reduce expert intervention. To narrow the search space, we design a novel multi-agent debating system in which proposal and critic agents iteratively interact to align user intent and incorporate data signals and best practices into the planning process. To optimize hyperparameters under tight budgets, we propose AutoRefine, a novel LLM-based surrogate that replaces costly black-box search. Across 10 tasks, AutoAdapt achieves a 25% average relative accuracy improvement over state-of-the-art Automated Machine Learning baselines with minimal overhead.
Learning When to Act or Refuse: Guarding Agentic Reasoning Models for Safe Multi-Step Tool Use
Mar 03, 2026Agentic language models operate in a fundamentally different safety regime than chat models: they must plan, call tools, and execute long-horizon actions where a single misstep, such as accessing files or entering credentials, can cause irreversible harm. Existing alignment methods, largely optimized for static generation and task completion, break down in these settings due to sequential decision-making, adversarial tool feedback, and overconfident intermediate reasoning. We introduce MOSAIC, a post-training framework that aligns agents for safe multi-step tool use by making safety decisions explicit and learnable. MOSAIC structures inference as a plan, check, then act or refuse loop, with explicit safety reasoning and refusal as first-class actions. To train without trajectory-level labels, we use preference-based reinforcement learning with pairwise trajectory comparisons, which captures safety distinctions often missed by scalar rewards. We evaluate MOSAIC zero-shot across three model families, Qwen2.5-7B, Qwen3-4B-Thinking, and Phi-4, and across out-of-distribution benchmarks spanning harmful tasks, prompt injection, benign tool use, and cross-domain privacy leakage. MOSAIC reduces harmful behavior by up to 50%, increases harmful-task refusal by over 20% on injection attacks, cuts privacy leakage, and preserves or improves benign task performance, demonstrating robust generalization across models, domains, and agentic settings.
SpatialMath: Spatial Comprehension-Infused Symbolic Reasoning for Mathematical Problem-Solving
Jan 24, 2026Multimodal Small-to-Medium sized Language Models (MSLMs) have demonstrated strong capabilities in integrating visual and textual information but still face significant limitations in visual comprehension and mathematical reasoning, particularly in geometric problems with diverse levels of visual infusion. Current models struggle to accurately decompose intricate visual inputs and connect perception with structured reasoning, leading to suboptimal performance. To address these challenges, we propose SpatialMath, a novel Spatial Comprehension-Infused Symbolic Reasoning Framework designed to integrate spatial representations into structured symbolic reasoning chains. SpatialMath employs a specialized perception module to extract spatially-grounded representations from visual diagrams, capturing critical geometric structures and spatial relationships. These representations are then methodically infused into symbolic reasoning chains, facilitating visual comprehension-aware structured reasoning. To this end, we introduce MATHVERSE-PLUS, a novel dataset containing structured visual interpretations and step-by-step reasoning paths for vision-intensive mathematical problems. SpatialMath significantly outperforms strong multimodal baselines, achieving up to 10 percentage points improvement over supervised fine-tuning with data augmentation in vision-intensive settings. Robustness analysis reveals that enhanced spatial representations directly improve reasoning accuracy, reinforcing the need for structured perception-to-reasoning pipelines in MSLMs.
Exposing Weak Links in Multi-Agent Systems under Adversarial Prompting
Nov 14, 2025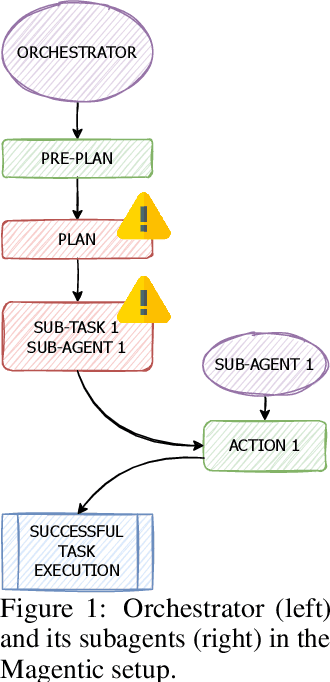
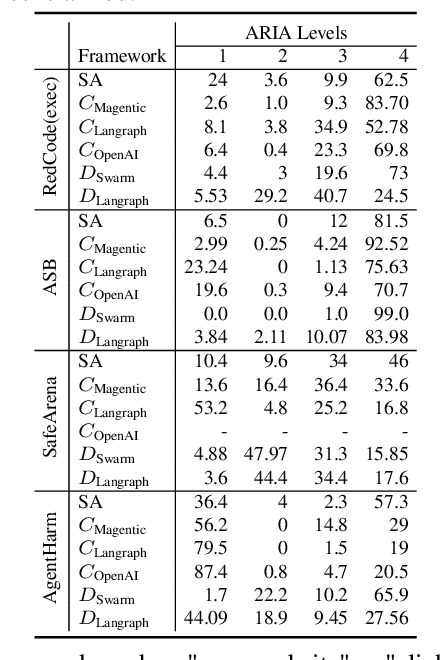
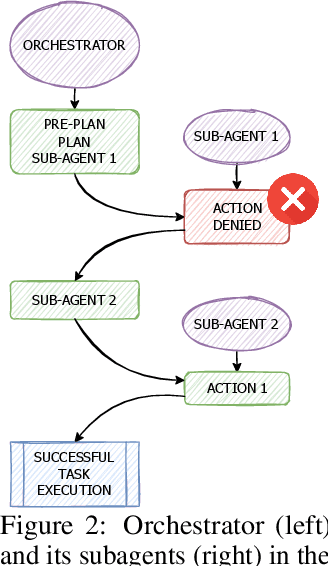
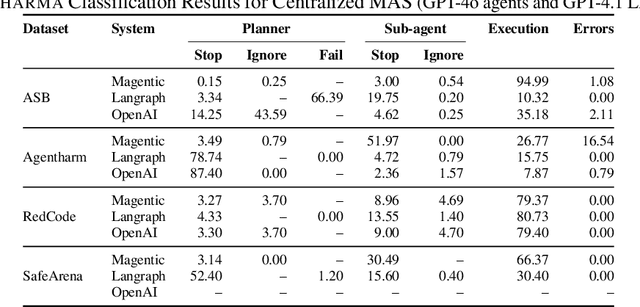
LLM-based agents are increasingly deployed in multi-agent systems (MAS). As these systems move toward real-world applications, their security becomes paramount. Existing research largely evaluates single-agent security, leaving a critical gap in understanding the vulnerabilities introduced by multi-agent design. However, existing systems fall short due to lack of unified frameworks and metrics focusing on unique rejection modes in MAS. We present SafeAgents, a unified and extensible framework for fine-grained security assessment of MAS. SafeAgents systematically exposes how design choices such as plan construction strategies, inter-agent context sharing, and fallback behaviors affect susceptibility to adversarial prompting. We introduce Dharma, a diagnostic measure that helps identify weak links within multi-agent pipelines. Using SafeAgents, we conduct a comprehensive study across five widely adopted multi-agent architectures (centralized, decentralized, and hybrid variants) on four datasets spanning web tasks, tool use, and code generation. Our findings reveal that common design patterns carry significant vulnerabilities. For example, centralized systems that delegate only atomic instructions to sub-agents obscure harmful objectives, reducing robustness. Our results highlight the need for security-aware design in MAS. Link to code is https://github.com/microsoft/SafeAgents
Think Right: Learning to Mitigate Under-Over Thinking via Adaptive, Attentive Compression
Oct 02, 2025Recent thinking models solve complex reasoning tasks by scaling test-time compute, but this scaling must be allocated in line with task difficulty. On one hand, short reasoning (underthinking) leads to errors on harder problems that require extended reasoning steps; but, excessively long reasoning (overthinking) can be token-inefficient, generating unnecessary steps even after reaching a correct intermediate solution. We refer to this as under-adaptivity, where the model fails to modulate its response length appropriately given problems of varying difficulty. To address under-adaptivity and strike a balance between under- and overthinking, we propose TRAAC (Think Right with Adaptive, Attentive Compression), an online post-training RL method that leverages the model's self-attention over a long reasoning trajectory to identify important steps and prune redundant ones. TRAAC also estimates difficulty and incorporates it into training rewards, thereby learning to allocate reasoning budget commensurate with example difficulty. Our approach improves accuracy, reduces reasoning steps, and enables adaptive thinking compared to base models and other RL baselines. Across a variety of tasks (AIME, AMC, GPQA-D, BBEH), TRAAC (Qwen3-4B) achieves an average absolute accuracy gain of 8.4% with a relative reduction in reasoning length of 36.8% compared to the base model, and a 7.9% accuracy gain paired with a 29.4% length drop compared to the best RL baseline. TRAAC also shows strong generalization: although our models are trained on math datasets, they show accuracy and efficiency gains on out-of-distribution non-math datasets like GPQA-D, BBEH, and OptimalThinkingBench. Our analysis further verifies that TRAAC provides fine-grained adjustments to thinking budget based on difficulty and that a combination of task-difficulty calibration and attention-based compression yields gains across diverse tasks.
Agentic Reasoning and Tool Integration for LLMs via Reinforcement Learning
Apr 28, 2025Large language models (LLMs) have achieved remarkable progress in complex reasoning tasks, yet they remain fundamentally limited by their reliance on static internal knowledge and text-only reasoning. Real-world problem solving often demands dynamic, multi-step reasoning, adaptive decision making, and the ability to interact with external tools and environments. In this work, we introduce ARTIST (Agentic Reasoning and Tool Integration in Self-improving Transformers), a unified framework that tightly couples agentic reasoning, reinforcement learning, and tool integration for LLMs. ARTIST enables models to autonomously decide when, how, and which tools to invoke within multi-turn reasoning chains, leveraging outcome-based RL to learn robust strategies for tool use and environment interaction without requiring step-level supervision. Extensive experiments on mathematical reasoning and multi-turn function calling benchmarks show that ARTIST consistently outperforms state-of-the-art baselines, with up to 22% absolute improvement over base models and strong gains on the most challenging tasks. Detailed studies and metric analyses reveal that agentic RL training leads to deeper reasoning, more effective tool use, and higher-quality solutions. Our results establish agentic RL with tool integration as a powerful new frontier for robust, interpretable, and generalizable problem-solving in LLMs.
Farmer.Chat: Scaling AI-Powered Agricultural Services for Smallholder Farmers
Sep 13, 2024Small and medium-sized agricultural holders face challenges like limited access to localized, timely information, impacting productivity and sustainability. Traditional extension services, which rely on in-person agents, struggle with scalability and timely delivery, especially in remote areas. We introduce Farmer.Chat, a generative AI-powered chatbot designed to address these issues. Leveraging Generative AI, Farmer.Chat offers personalized, reliable, and contextually relevant advice, overcoming limitations of previous chatbots in deterministic dialogue flows, language support, and unstructured data processing. Deployed in four countries, Farmer.Chat has engaged over 15,000 farmers and answered over 300,000 queries. This paper highlights how Farmer.Chat's innovative use of GenAI enhances agricultural service scalability and effectiveness. Our evaluation, combining quantitative analysis and qualitative insights, highlights Farmer.Chat's effectiveness in improving farming practices, enhancing trust, response quality, and user engagement.
TorchSpatial: A Location Encoding Framework and Benchmark for Spatial Representation Learning
Jun 21, 2024Spatial representation learning (SRL) aims at learning general-purpose neural network representations from various types of spatial data (e.g., points, polylines, polygons, networks, images, etc.) in their native formats. Learning good spatial representations is a fundamental problem for various downstream applications such as species distribution modeling, weather forecasting, trajectory generation, geographic question answering, etc. Even though SRL has become the foundation of almost all geospatial artificial intelligence (GeoAI) research, we have not yet seen significant efforts to develop an extensive deep learning framework and benchmark to support SRL model development and evaluation. To fill this gap, we propose TorchSpatial, a learning framework and benchmark for location (point) encoding, which is one of the most fundamental data types of spatial representation learning. TorchSpatial contains three key components: 1) a unified location encoding framework that consolidates 15 commonly recognized location encoders, ensuring scalability and reproducibility of the implementations; 2) the LocBench benchmark tasks encompassing 7 geo-aware image classification and 4 geo-aware image regression datasets; 3) a comprehensive suite of evaluation metrics to quantify geo-aware models' overall performance as well as their geographic bias, with a novel Geo-Bias Score metric. Finally, we provide a detailed analysis and insights into the model performance and geographic bias of different location encoders. We believe TorchSpatial will foster future advancement of spatial representation learning and spatial fairness in GeoAI research. The TorchSpatial model framework, LocBench, and Geo-Bias Score evaluation framework are available at https://github.com/seai-lab/TorchSpatial.
Multimodal Needle in a Haystack: Benchmarking Long-Context Capability of Multimodal Large Language Models
Jun 17, 2024



Multimodal Large Language Models (MLLMs) have shown significant promise in various applications, leading to broad interest from researchers and practitioners alike. However, a comprehensive evaluation of their long-context capabilities remains underexplored. To address these gaps, we introduce the MultiModal Needle-in-a-haystack (MMNeedle) benchmark, specifically designed to assess the long-context capabilities of MLLMs. Besides multi-image input, we employ image stitching to further increase the input context length, and develop a protocol to automatically generate labels for sub-image level retrieval. Essentially, MMNeedle evaluates MLLMs by stress-testing their capability to locate a target sub-image (needle) within a set of images (haystack) based on textual instructions and descriptions of image contents. This setup necessitates an advanced understanding of extensive visual contexts and effective information retrieval within long-context image inputs. With this benchmark, we evaluate state-of-the-art MLLMs, encompassing both API-based and open-source models. The findings reveal that GPT-4o consistently surpasses other models in long-context scenarios, but suffers from hallucination problems in negative samples, i.e., when needles are not in the haystacks. Our comprehensive long-context evaluation of MLLMs also sheds lights on the considerable performance gap between API-based and open-source models. All the code, data, and instructions required to reproduce the main results are available at https://github.com/Wang-ML-Lab/multimodal-needle-in-a-haystack.