 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Streaming Perception using Deep Reinforcement Learning
Paper and Code
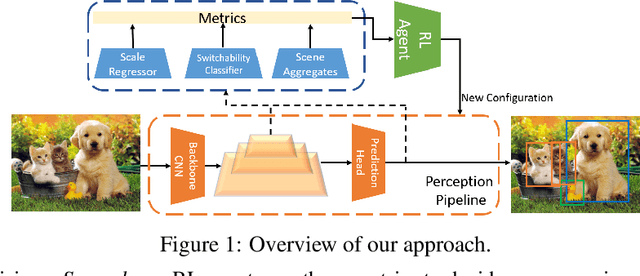
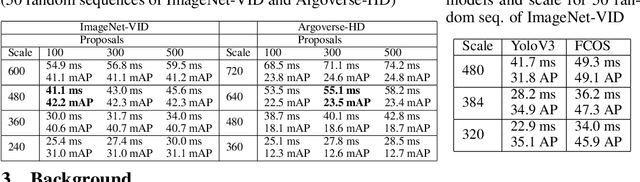
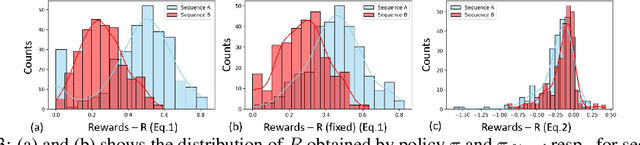
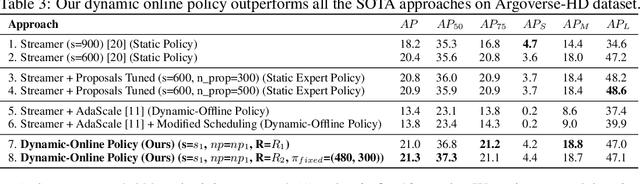
Executing computer vision models on streaming visual data, or streaming perception is an emerging problem, with applications in self-driving, embodied agents, and augmented/virtual reality. The development of such systems is largely governed by the accuracy and latency of the processing pipeline. While past work has proposed numerous approximate execution frameworks, their decision functions solely focus on optimizing latency, accuracy, or energy, etc. This results in sub-optimum decisions, affecting the overall system performance. We argue that the streaming perception systems should holistically maximize the overall system performance (i.e., considering both accuracy and latency simultaneously). To this end, we describe a new approach based on deep reinforcement learning to learn these tradeoffs at runtime for streaming perception. This tradeoff optimization is formulated as a novel deep contextual bandit problem and we design a new reward function that holistically integrates latency and accuracy into a single metric. We show that our agent can learn a competitive policy across multiple decision dimensions, which outperforms state-of-the-art policies on public datasets.