 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeography According to ChatGPT -- How Generative AI Represents and Reasons about Geography
Mar 19, 2026Understanding how AI will represent and reason about geography should be a key concern for all of us, as the broader public increasingly interacts with spaces and places through these systems. Similarly, in line with the nature of foundation models, our own research often relies on pre-trained models. Hence, understanding what world AI systems construct is as important as evaluating their accuracy, including factual recall. To motivate the need for such studies, we provide three illustrative vignettes, i.e., exploratory probes, in the hope that they will spark lively discussions and follow-up work: (1) Do models form strong defaults, and how brittle are model outputs to minute syntactic variations? (2) Can distributional shifts resurface from the composition of individually benign tasks, e.g., when using AI systems to create personas? (3) Do we overlook deeper questions of understanding when solely focusing on the ability of systems to recall facts such as geographic principles?
Whose Truth? Pluralistic Geo-Alignment for (Agentic) AI
Aug 07, 2025AI (super) alignment describes the challenge of ensuring (future) AI systems behave in accordance with societal norms and goals. While a quickly evolving literature is addressing biases and inequalities, the geographic variability of alignment remains underexplored. Simply put, what is considered appropriate, truthful, or legal can differ widely across regions due to cultural norms, political realities, and legislation. Alignment measures applied to AI/ML workflows can sometimes produce outcomes that diverge from statistical realities, such as text-to-image models depicting balanced gender ratios in company leadership despite existing imbalances. Crucially, some model outputs are globally acceptable, while others, e.g., questions about Kashmir, depend on knowing the user's location and their context. This geographic sensitivity is not new. For instance, Google Maps renders Kashmir's borders differently based on user location. What is new is the unprecedented scale and automation with which AI now mediates knowledge, expresses opinions, and represents geographic reality to millions of users worldwide, often with little transparency about how context is managed. As we approach Agentic AI, the need for spatio-temporally aware alignment, rather than one-size-fits-all approaches, is increasingly urgent. This paper reviews key geographic research problems, suggests topics for future work, and outlines methods for assessing alignment sensitivity.
ELITE: Embedding-Less retrieval with Iterative Text Exploration
May 17, 2025Large Language Models (LLMs) have achieved impressive progress in natural language processing, but their limited ability to retain long-term context constrains performance on document-level or multi-turn tasks. Retrieval-Augmented Generation (RAG) mitigates this by retrieving relevant information from an external corpus. However, existing RAG systems often rely on embedding-based retrieval trained on corpus-level semantic similarity, which can lead to retrieving content that is semantically similar in form but misaligned with the question's true intent. Furthermore, recent RAG variants construct graph- or hierarchy-based structures to improve retrieval accuracy, resulting in significant computation and storage overhead. In this paper, we propose an embedding-free retrieval framework. Our method leverages the logical inferencing ability of LLMs in retrieval using iterative search space refinement guided by our novel importance measure and extend our retrieval results with logically related information without explicit graph construction. Experiments on long-context QA benchmarks, including NovelQA and Marathon, show that our approach outperforms strong baselines while reducing storage and runtime by over an order of magnitude.
The S2 Hierarchical Discrete Global Grid as a Nexus for Data Representation, Integration, and Querying Across Geospatial Knowledge Graphs
Oct 18, 2024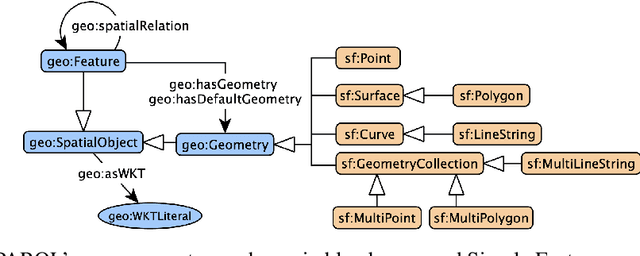


Geospatial Knowledge Graphs (GeoKGs) have become integral to the growing field of Geospatial Artificial Intelligence. Initiatives like the U.S. National Science Foundation's Open Knowledge Network program aim to create an ecosystem of nation-scale, cross-disciplinary GeoKGs that provide AI-ready geospatial data aligned with FAIR principles. However, building this infrastructure presents key challenges, including 1) managing large volumes of data, 2) the computational complexity of discovering topological relations via SPARQL, and 3) conflating multi-scale raster and vector data. Discrete Global Grid Systems (DGGS) help tackle these issues by offering efficient data integration and representation strategies. The KnowWhereGraph utilizes Google's S2 Geometry -- a DGGS framework -- to enable efficient multi-source data processing, qualitative spatial querying, and cross-graph integration. This paper outlines the implementation of S2 within KnowWhereGraph, emphasizing its role in topologically enriching and semantically compressing data. Ultimately, this work demonstrates the potential of DGGS frameworks, particularly S2, for building scalable GeoKGs.
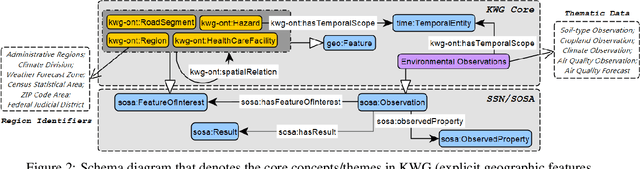
The KnowWhereGraph Ontology
Oct 17, 2024



KnowWhereGraph is one of the largest fully publicly available geospatial knowledge graphs. It includes data from 30 layers on natural hazards (e.g., hurricanes, wildfires), climate variables (e.g., air temperature, precipitation), soil properties, crop and land-cover types, demographics, and human health, various place and region identifiers, among other themes. These have been leveraged through the graph by a variety of applications to address challenges in food security and agricultural supply chains; sustainability related to soil conservation practices and farm labor; and delivery of emergency humanitarian aid following a disaster. In this paper, we introduce the ontology that acts as the schema for KnowWhereGraph. This broad overview provides insight into the requirements and design specifications for the graph and its schema, including the development methodology (modular ontology modeling) and the resources utilized to implement, materialize, and deploy KnowWhereGraph with its end-user interfaces and public query SPARQL endpoint.
A Geometry-Aware Algorithm to Learn Hierarchical Embeddings in Hyperbolic Space
Jul 23, 2024Hyperbolic embeddings are a class of representation learning methods that offer competitive performances when data can be abstracted as a tree-like graph. However, in practice, learning hyperbolic embeddings of hierarchical data is difficult due to the different geometry between hyperbolic space and the Euclidean space. To address such difficulties, we first categorize three kinds of illness that harm the performance of the embeddings. Then, we develop a geometry-aware algorithm using a dilation operation and a transitive closure regularization to tackle these illnesses. We empirically validate these techniques and present a theoretical analysis of the mechanism behind the dilation operation. Experiments on synthetic and real-world datasets reveal superior performances of our algorithm.
TorchSpatial: A Location Encoding Framework and Benchmark for Spatial Representation Learning
Jun 21, 2024Spatial representation learning (SRL) aims at learning general-purpose neural network representations from various types of spatial data (e.g., points, polylines, polygons, networks, images, etc.) in their native formats. Learning good spatial representations is a fundamental problem for various downstream applications such as species distribution modeling, weather forecasting, trajectory generation, geographic question answering, etc. Even though SRL has become the foundation of almost all geospatial artificial intelligence (GeoAI) research, we have not yet seen significant efforts to develop an extensive deep learning framework and benchmark to support SRL model development and evaluation. To fill this gap, we propose TorchSpatial, a learning framework and benchmark for location (point) encoding, which is one of the most fundamental data types of spatial representation learning. TorchSpatial contains three key components: 1) a unified location encoding framework that consolidates 15 commonly recognized location encoders, ensuring scalability and reproducibility of the implementations; 2) the LocBench benchmark tasks encompassing 7 geo-aware image classification and 4 geo-aware image regression datasets; 3) a comprehensive suite of evaluation metrics to quantify geo-aware models' overall performance as well as their geographic bias, with a novel Geo-Bias Score metric. Finally, we provide a detailed analysis and insights into the model performance and geographic bias of different location encoders. We believe TorchSpatial will foster future advancement of spatial representation learning and spatial fairness in GeoAI research. The TorchSpatial model framework, LocBench, and Geo-Bias Score evaluation framework are available at https://github.com/seai-lab/TorchSpatial.
MC-GTA: Metric-Constrained Model-Based Clustering using Goodness-of-fit Tests with Autocorrelations
May 28, 2024



A wide range of (multivariate) temporal (1D) and spatial (2D) data analysis tasks, such as grouping vehicle sensor trajectories, can be formulated as clustering with given metric constraints. Existing metric-constrained clustering algorithms overlook the rich correlation between feature similarity and metric distance, i.e., metric autocorrelation. The model-based variations of these clustering algorithms (e.g. TICC and STICC) achieve SOTA performance, yet suffer from computational instability and complexity by using a metric-constrained Expectation-Maximization procedure. In order to address these two problems, we propose a novel clustering algorithm, MC-GTA (Model-based Clustering via Goodness-of-fit Tests with Autocorrelations). Its objective is only composed of pairwise weighted sums of feature similarity terms (square Wasserstein-2 distance) and metric autocorrelation terms (a novel multivariate generalization of classic semivariogram). We show that MC-GTA is effectively minimizing the total hinge loss for intra-cluster observation pairs not passing goodness-of-fit tests, i.e., statistically not originating from the same distribution. Experiments on 1D/2D synthetic and real-world datasets demonstrate that MC-GTA successfully incorporates metric autocorrelation. It outperforms strong baselines by large margins (up to 14.3% in ARI and 32.1% in NMI) with faster and stabler optimization (>10x speedup).
Probing the Information Theoretical Roots of Spatial Dependence Measures
May 28, 2024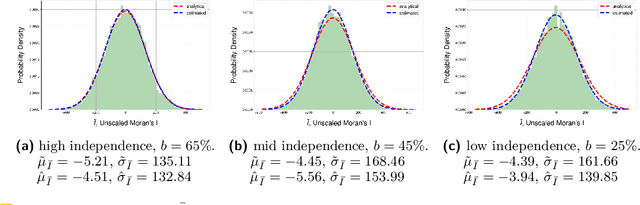

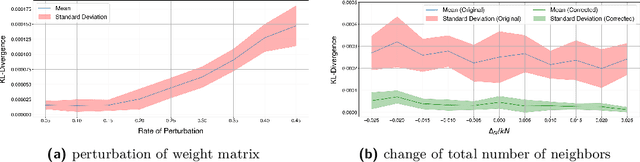
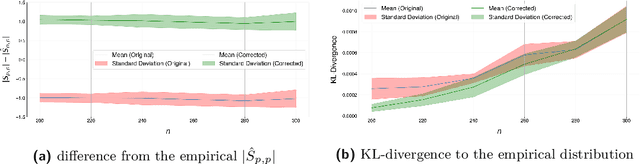
Intuitively, there is a relation between measures of spatial dependence and information theoretical measures of entropy. For instance, we can provide an intuition of why spatial data is special by stating that, on average, spatial data samples contain less than expected information. Similarly, spatial data, e.g., remotely sensed imagery, that is easy to compress is also likely to show significant spatial autocorrelation. Formulating our (highly specific) core concepts of spatial information theory in the widely used language of information theory opens new perspectives on their differences and similarities and also fosters cross-disciplinary collaboration, e.g., with the broader AI/ML communities. Interestingly, however, this intuitive relation is challenging to formalize and generalize, leading prior work to rely mostly on experimental results, e.g., for describing landscape patterns. In this work, we will explore the information theoretical roots of spatial autocorrelation, more specifically Moran's I, through the lens of self-information (also known as surprisal) and provide both formal proofs and experiments.
A Ground Segmentation Method Based on Point Cloud Map for Unstructured Roads
Sep 15, 2023



Ground segmentation, as the basic task of unmanned intelligent perception, provides an important support for the target detection task. Unstructured road scenes represented by open-pit mines have irregular boundary lines and uneven road surfaces, which lead to segmentation errors in current ground segmentation methods. To solve this problem, a ground segmentation method based on point cloud map is proposed, which involves three parts: region of interest extraction, point cloud registration and background subtraction. Firstly, establishing boundary semantic associations to obtain regions of interest in unstructured roads. Secondly, establishing the location association between point cloud map and the real-time point cloud of region of interest by semantics information. Thirdly, establishing a background model based on Gaussian distribution according to location association, and segments the ground in real-time point cloud by the background substraction method. Experimental results show that the correct segmentation rate of ground points is 99.95%, and the running time is 26ms. Compared with state of the art ground segmentation algorithm Patchwork++, the average accuracy of ground point segmentation is increased by 7.43%, and the running time is increased by 17ms. Furthermore, the proposed method is practically applied to unstructured road scenarios represented by open pit mines.