 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Video Object Segmentation based on Scale Inconsistency
Paper and Code



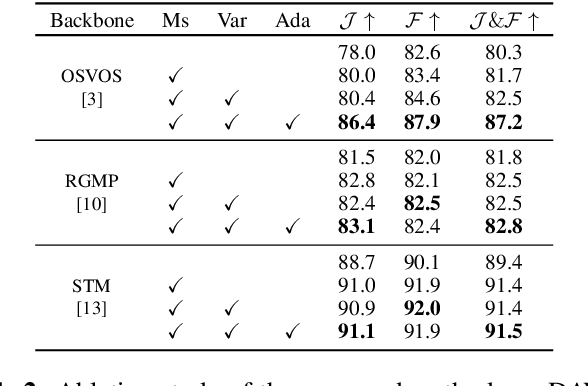
We present a refinement framework to boost the performance of pre-trained semi-supervised video object segmentation (VOS) models. Our work is based on scale inconsistency, which is motivated by the observation that existing VOS models generate inconsistent predictions from input frames with different sizes. We use the scale inconsistency as a clue to devise a pixel-level attention module that aggregates the advantages of the predictions from different-size inputs. The scale inconsistency is also used to regularize the training based on a pixel-level variance measured by an uncertainty estimation. We further present a self-supervised online adaptation, tailored for test-time optimization, that bootstraps the predictions without ground-truth masks based on the scale inconsistency. Experiments on DAVIS 16 and DAVIS 17 datasets show that our framework can be generically applied to various VOS models and improve their performance.