 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Energy-Based Model for Out-of-Distribution Detection
Dec 04, 2024

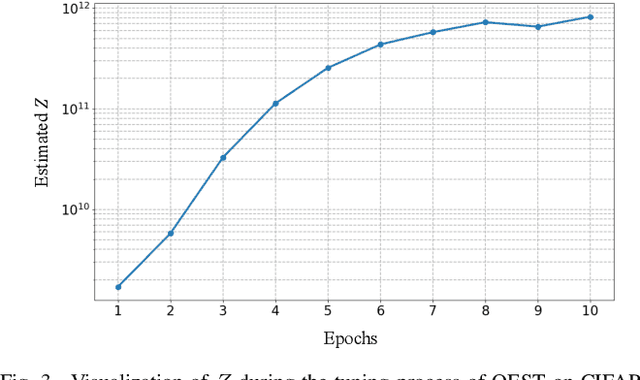
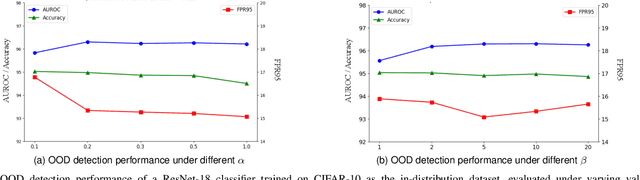
Out-of-distribution (OOD) detection is an essential approach to robustifying deep learning models, enabling them to identify inputs that fall outside of their trained distribution. Existing OOD detection methods usually depend on crafted data, such as specific outlier datasets or elaborate data augmentations. While this is reasonable, the frequent mismatch between crafted data and OOD data limits model robustness and generalizability. In response to this issue, we introduce Outlier Exposure by Simple Transformations (OEST), a framework that enhances OOD detection by leveraging "peripheral-distribution" (PD) data. Specifically, PD data are samples generated through simple data transformations, thus providing an efficient alternative to manually curated outliers. We adopt energy-based models (EBMs) to study PD data. We recognize the "energy barrier" in OOD detection, which characterizes the energy difference between in-distribution (ID) and OOD samples and eases detection. PD data are introduced to establish the energy barrier during training. Furthermore, this energy barrier concept motivates a theoretically grounded energy-barrier loss to replace the classical energy-bounded loss, leading to an improved paradigm, OEST*, which achieves a more effective and theoretically sound separation between ID and OOD samples. We perform empirical validation of our proposal, and extensive experiments across various benchmarks demonstrate that OEST* achieves better or similar accuracy compared with state-of-the-art methods.
Generating and Reweighting Dense Contrastive Patterns for Unsupervised Anomaly Detection
Dec 26, 2023Recent unsupervised anomaly detection methods often rely on feature extractors pretrained with auxiliary datasets or on well-crafted anomaly-simulated samples. However, this might limit their adaptability to an increasing set of anomaly detection tasks due to the priors in the selection of auxiliary datasets or the strategy of anomaly simulation. To tackle this challenge, we first introduce a prior-less anomaly generation paradigm and subsequently develop an innovative unsupervised anomaly detection framework named GRAD, grounded in this paradigm. GRAD comprises three essential components: (1) a diffusion model (PatchDiff) to generate contrastive patterns by preserving the local structures while disregarding the global structures present in normal images, (2) a self-supervised reweighting mechanism to handle the challenge of long-tailed and unlabeled contrastive patterns generated by PatchDiff, and (3) a lightweight patch-level detector to efficiently distinguish the normal patterns and reweighted contrastive patterns. The generation results of PatchDiff effectively expose various types of anomaly patterns, e.g. structural and logical anomaly patterns. In addition, extensive experiments on both MVTec AD and MVTec LOCO datasets also support the aforementioned observation and demonstrate that GRAD achieves competitive anomaly detection accuracy and superior inference speed.
Reasoning Structural Relation for Occlusion-Robust Facial Landmark Localization
Dec 19, 2021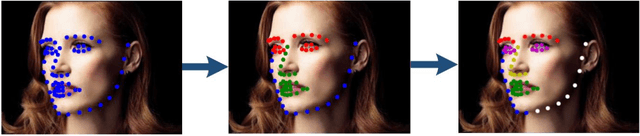
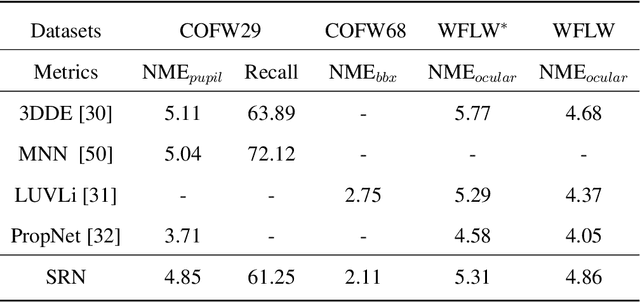
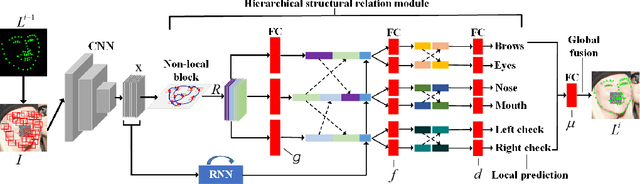
In facial landmark localization tasks, various occlusions heavily degrade the localization accuracy due to the partial observability of facial features. This paper proposes a structural relation network (SRN) for occlusion-robust landmark localization. Unlike most existing methods that simply exploit the shape constraint, the proposed SRN aims to capture the structural relations among different facial components. These relations can be considered a more powerful shape constraint against occlusion. To achieve this, a hierarchical structural relation module (HSRM) is designed to hierarchically reason the structural relations that represent both long- and short-distance spatial dependencies. Compared with existing network architectures, HSRM can efficiently model the spatial relations by leveraging its geometry-aware network architecture, which reduces the semantic ambiguity caused by occlusion. Moreover, the SRN augments the training data by synthesizing occluded faces. To further extend our SRN for occluded video data, we formulate the occluded face synthesis as a Markov decision process (MDP). Specifically, it plans the movement of the dynamic occlusion based on an accumulated reward associated with the performance degradation of the pre-trained SRN. This procedure augments hard samples for robust facial landmark tracking. Extensive experimental results indicate that the proposed method achieves outstanding performance on occluded and masked faces. Code is available at https://github.com/zhuccly/SRN.
Unsupervised Learning of Multi-level Structures for Anomaly Detection
Apr 25, 2021
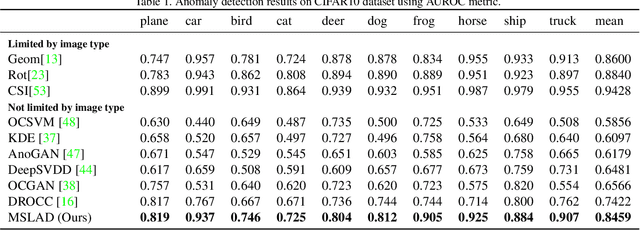
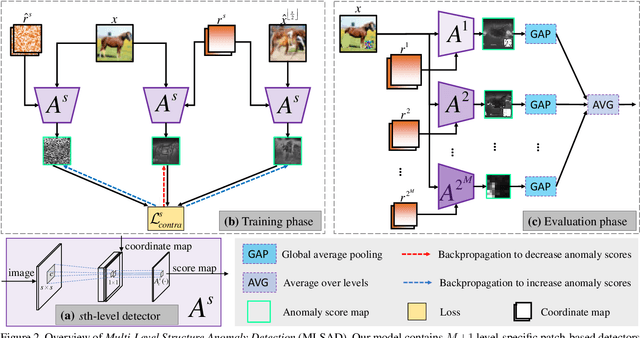
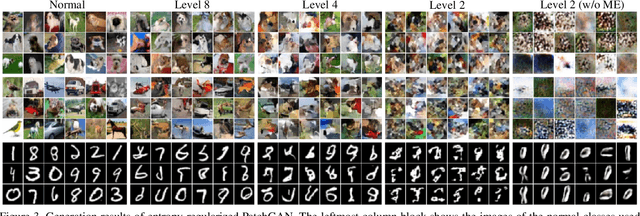
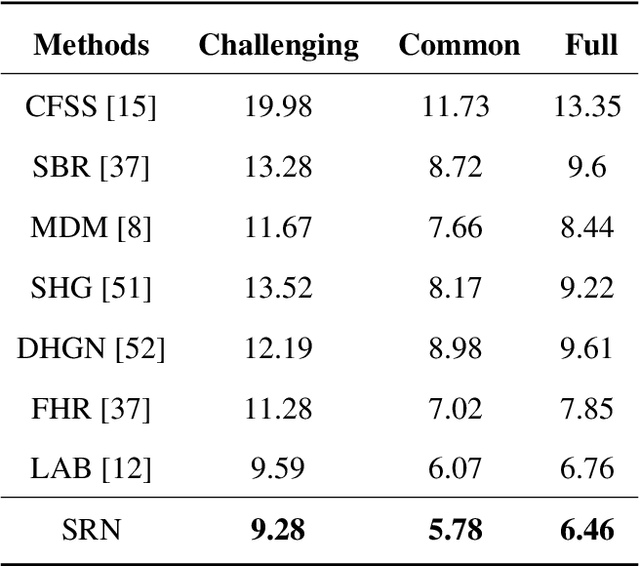
The main difficulty in high-dimensional anomaly detection tasks is the lack of anomalous data for training. And simply collecting anomalous data from the real world, common distributions, or the boundary of normal data manifold may face the problem of missing anomaly modes. This paper first introduces a novel method to generate anomalous data by breaking up global structures while preserving local structures of normal data at multiple levels. It can efficiently expose local abnormal structures of various levels. To fully exploit the exposed multi-level abnormal structures, we propose to train multiple level-specific patch-based detectors with contrastive losses. Each detector learns to detect local abnormal structures of corresponding level at all locations and outputs patchwise anomaly scores. By aggregating the outputs of all level-specific detectors, we obtain a model that can detect all potential anomalies. The effectiveness is evaluated on MNIST, CIFAR10, and ImageNet10 dataset, where the results surpass the accuracy of state-of-the-art methods. Qualitative experiments demonstrate our model is robust that it unbiasedly detects all anomaly modes.
Learning Segmentation Masks with the Independence Prior
Nov 13, 2018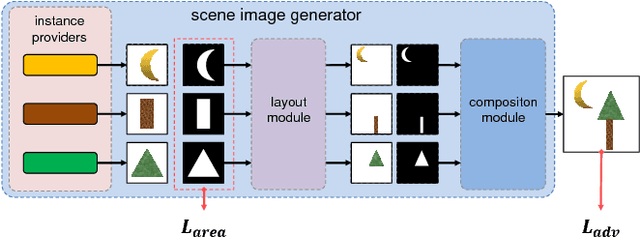


An instance with a bad mask might make a composite image that uses it look fake. This encourages us to learn segmentation by generating realistic composite images. To achieve this, we propose a novel framework that exploits a new proposed prior called the independence prior based on Generative Adversarial Networks (GANs). The generator produces an image with multiple category-specific instance providers, a layout module and a composition module. Firstly, each provider independently outputs a category-specific instance image with a soft mask. Then the provided instances' poses are corrected by the layout module. Lastly, the composition module combines these instances into a final image. Training with adversarial loss and penalty for mask area, each provider learns a mask that is as small as possible but enough to cover a complete category-specific instance. Weakly supervised semantic segmentation methods widely use grouping cues modeling the association between image parts, which are either artificially designed or learned with costly segmentation labels or only modeled on local pairs. Unlike them, our method automatically models the dependence between any parts and learns instance segmentation. We apply our framework in two cases: (1) Foreground segmentation on category-specific images with box-level annotation. (2) Unsupervised learning of instance appearances and masks with only one image of homogeneous object cluster (HOC). We get appealing results in both tasks, which shows the independence prior is useful for instance segmentation and it is possible to unsupervisedly learn instance masks with only one image.