 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model Compression with Global Rank and Sparsity Optimization
May 02, 2025Low-rank and sparse composite approximation is a natural idea to compress Large Language Models (LLMs). However, such an idea faces two primary challenges that adversely affect the performance of existing methods. The first challenge relates to the interaction and cooperation between low-rank and sparse matrices, while the second involves determining weight allocation across different layers, as redundancy varies considerably among them. To address these challenges, we propose a novel two-stage LLM compression method with the capability of global rank and sparsity optimization. It is noteworthy that the overall optimization space is vast, making comprehensive optimization computationally prohibitive. Therefore, to reduce the optimization space, our first stage utilizes robust principal component analysis to decompose the weight matrices of LLMs into low-rank and sparse components, which span the low dimensional and sparse spaces containing the resultant low-rank and sparse matrices, respectively. In the second stage, we propose a probabilistic global optimization technique to jointly identify the low-rank and sparse structures within the above two spaces. The appealing feature of our approach is its ability to automatically detect the redundancy across different layers and to manage the interaction between the sparse and low-rank components. Extensive experimental results indicate that our method significantly surpasses state-of-the-art techniques for sparsification and composite approximation.
Efficient Fine-Tuning of Quantized Models via Adaptive Rank and Bitwidth
May 02, 2025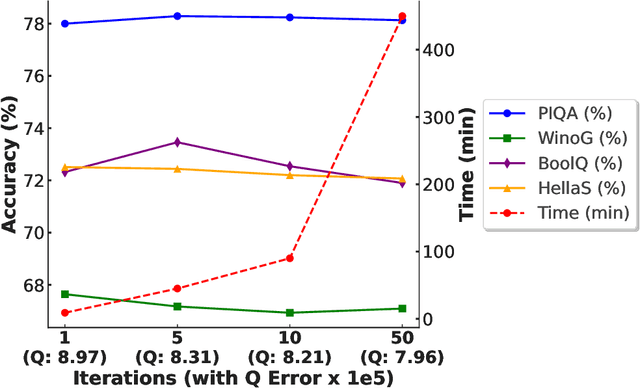
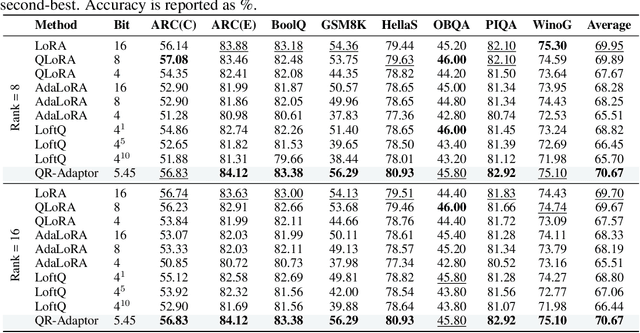
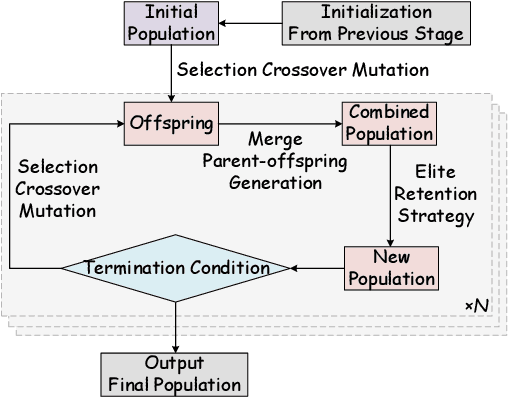
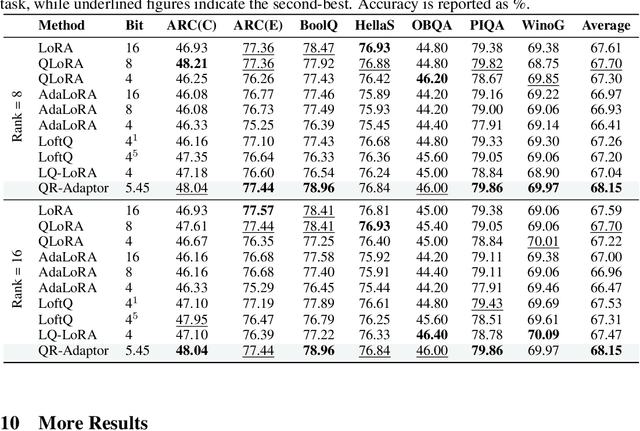
QLoRA effectively combines low-bit quantization and LoRA to achieve memory-friendly fine-tuning for large language models (LLM). Recently, methods based on SVD for continuous update iterations to initialize LoRA matrices to accommodate quantization errors have generally failed to consistently improve performance. Dynamic mixed precision is a natural idea for continuously improving the fine-tuning performance of quantized models, but previous methods often optimize low-rank subspaces or quantization components separately, without considering their synergy. To address this, we propose \textbf{QR-Adaptor}, a unified, gradient-free strategy that uses partial calibration data to jointly search the quantization components and the rank of low-rank spaces for each layer, thereby continuously improving model performance. QR-Adaptor does not minimize quantization error but treats precision and rank allocation as a discrete optimization problem guided by actual downstream performance and memory usage. Compared to state-of-the-art (SOTA) quantized LoRA fine-tuning methods, our approach achieves a 4.89\% accuracy improvement on GSM8K, and in some cases even outperforms the 16-bit fine-tuned model while maintaining the memory footprint of the 4-bit setting.
QPruner: Probabilistic Decision Quantization for Structured Pruning in Large Language Models
Dec 16, 2024The rise of large language models (LLMs) has significantly advanced various natural language processing (NLP) tasks. However, the resource demands of these models pose substantial challenges. Structured pruning is an effective approach to reducing model size, but it often results in significant accuracy degradation, necessitating parameter updates to adapt. Unfortunately, such fine-tuning requires substantial memory, which limits its applicability. To address these challenges, we introduce quantization into the structured pruning framework to reduce memory consumption during both fine-tuning and inference. However, the combined errors from pruning and quantization increase the difficulty of fine-tuning, requiring a more refined quantization scheme. To this end, we propose QPruner, a novel framework that employs structured pruning to reduce model size, followed by a layer-wise mixed-precision quantization scheme. Quantization precisions are assigned to each layer based on their importance to the target task, and Bayesian optimization is employed to refine precision allocation strategies, ensuring a balance between model accuracy and memory efficiency. Extensive experiments on benchmark datasets demonstrate that QPruner significantly outperforms existing methods in memory savings while maintaining or improving model performance.
AutoMixQ: Self-Adjusting Quantization for High Performance Memory-Efficient Fine-Tuning
Nov 21, 2024Fine-tuning large language models (LLMs) under resource constraints is a significant challenge in deep learning. Low-Rank Adaptation (LoRA), pruning, and quantization are all effective methods for improving resource efficiency. However, combining them directly often results in suboptimal performance, especially with uniform quantization across all model layers. This is due to the complex, uneven interlayer relationships introduced by pruning, necessitating more refined quantization strategies. To address this, we propose AutoMixQ, an end-to-end optimization framework that selects optimal quantization configurations for each LLM layer. AutoMixQ leverages lightweight performance models to guide the selection process, significantly reducing time and computational resources compared to exhaustive search methods. By incorporating Pareto optimality, AutoMixQ balances memory usage and performance, approaching the upper bounds of model capability under strict resource constraints. Our experiments on widely used benchmarks show that AutoMixQ reduces memory consumption while achieving superior performance. For example, at a 30\% pruning rate in LLaMA-7B, AutoMixQ achieved 66.21\% on BoolQ compared to 62.45\% for LoRA and 58.96\% for LoftQ, while reducing memory consumption by 35.5\% compared to LoRA and 27.5\% compared to LoftQ.
RankAdaptor: Hierarchical Dynamic Low-Rank Adaptation for Structural Pruned LLMs
Jun 22, 2024
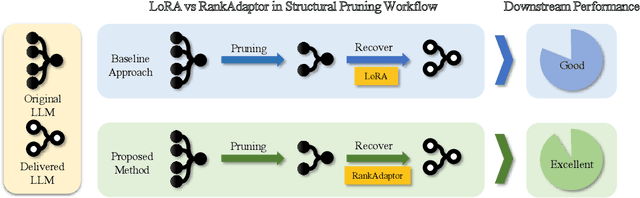
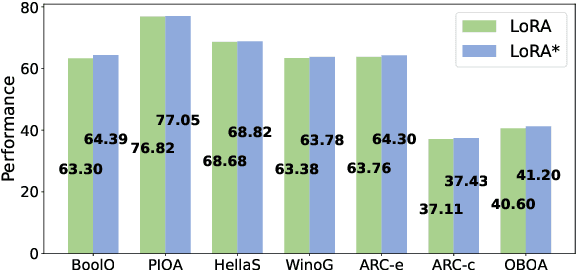
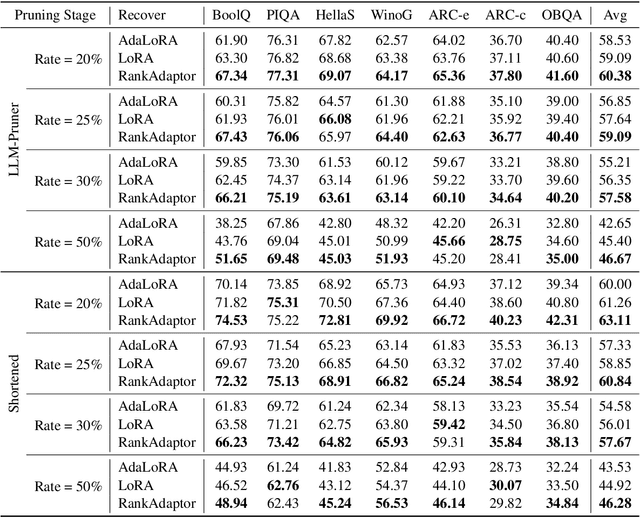
The efficient compression of large language models (LLMs) is becoming increasingly popular. However, recovering the accuracy of compressed LLMs is still a major challenge. Structural pruning with standard Low-Rank Adaptation (LoRA) is a common technique in current LLM compression. In structural pruning, the model architecture is modified unevenly, resulting in suboptimal performance in various downstream tasks via standard LoRA with fixed rank. To address this problem, we introduce RankAdaptor, an efficient fine-tuning method with hierarchical dynamic rank scheduling for pruned LLMs. An end-to-end automatic optimization flow is developed that utilizes a lightweight performance model to determine the different ranks during fine-tuning. Comprehensive experiments on popular benchmarks show that RankAdaptor consistently outperforms standard LoRA with structural pruning over different pruning settings. Without increasing the trainable parameters, RankAdaptor further reduces the accuracy performance gap between the recovery of the pruned model and the original model compared to standard LoRA.