 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQPruner: Probabilistic Decision Quantization for Structured Pruning in Large Language Models
Dec 16, 2024The rise of large language models (LLMs) has significantly advanced various natural language processing (NLP) tasks. However, the resource demands of these models pose substantial challenges. Structured pruning is an effective approach to reducing model size, but it often results in significant accuracy degradation, necessitating parameter updates to adapt. Unfortunately, such fine-tuning requires substantial memory, which limits its applicability. To address these challenges, we introduce quantization into the structured pruning framework to reduce memory consumption during both fine-tuning and inference. However, the combined errors from pruning and quantization increase the difficulty of fine-tuning, requiring a more refined quantization scheme. To this end, we propose QPruner, a novel framework that employs structured pruning to reduce model size, followed by a layer-wise mixed-precision quantization scheme. Quantization precisions are assigned to each layer based on their importance to the target task, and Bayesian optimization is employed to refine precision allocation strategies, ensuring a balance between model accuracy and memory efficiency. Extensive experiments on benchmark datasets demonstrate that QPruner significantly outperforms existing methods in memory savings while maintaining or improving model performance.
RankAdaptor: Hierarchical Dynamic Low-Rank Adaptation for Structural Pruned LLMs
Jun 22, 2024
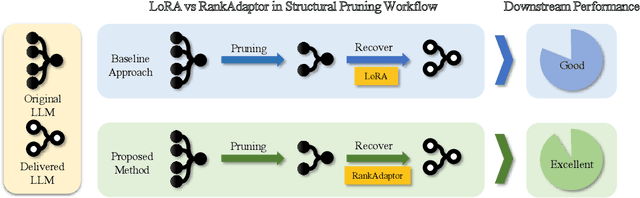
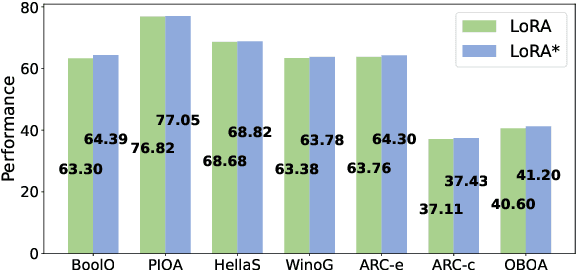
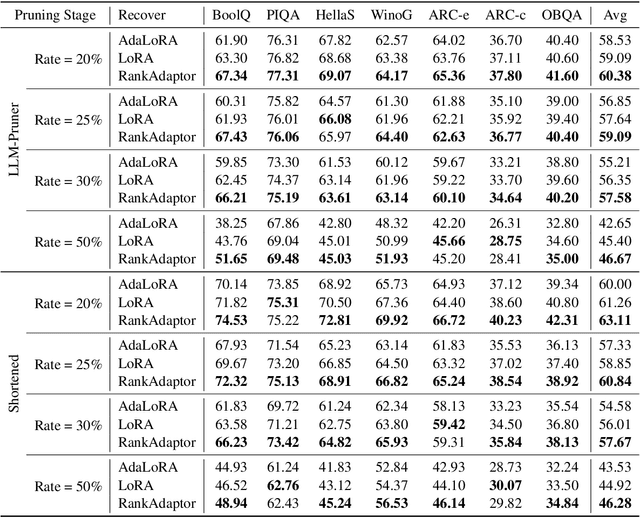
The efficient compression of large language models (LLMs) is becoming increasingly popular. However, recovering the accuracy of compressed LLMs is still a major challenge. Structural pruning with standard Low-Rank Adaptation (LoRA) is a common technique in current LLM compression. In structural pruning, the model architecture is modified unevenly, resulting in suboptimal performance in various downstream tasks via standard LoRA with fixed rank. To address this problem, we introduce RankAdaptor, an efficient fine-tuning method with hierarchical dynamic rank scheduling for pruned LLMs. An end-to-end automatic optimization flow is developed that utilizes a lightweight performance model to determine the different ranks during fine-tuning. Comprehensive experiments on popular benchmarks show that RankAdaptor consistently outperforms standard LoRA with structural pruning over different pruning settings. Without increasing the trainable parameters, RankAdaptor further reduces the accuracy performance gap between the recovery of the pruned model and the original model compared to standard LoRA.
Healing Powers of BERT: How Task-Specific Fine-Tuning Recovers Corrupted Language Models
Jun 20, 2024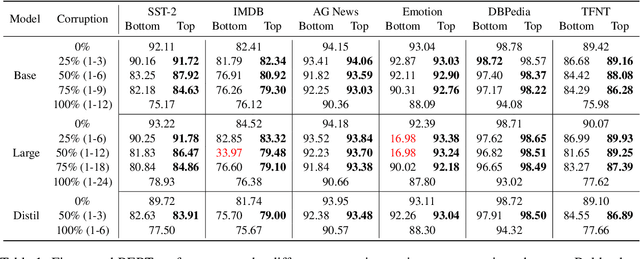

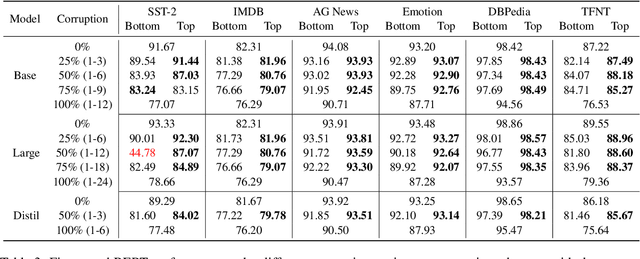
Language models like BERT excel at sentence classification tasks due to extensive pre-training on general data, but their robustness to parameter corruption is unexplored. To understand this better, we look at what happens if a language model is "broken", in the sense that some of its parameters are corrupted and then recovered by fine-tuning. Strategically corrupting BERT variants at different levels, we find corrupted models struggle to fully recover their original performance, with higher corruption causing more severe degradation. Notably, bottom-layer corruption affecting fundamental linguistic features is more detrimental than top-layer corruption. Our insights contribute to understanding language model robustness and adaptability under adverse conditions, informing strategies for developing resilient NLP systems against parameter perturbations.
Auxiliary Reward Generation with Transition Distance Representation Learning
Feb 12, 2024



Reinforcement learning (RL) has shown its strength in challenging sequential decision-making problems. The reward function in RL is crucial to the learning performance, as it serves as a measure of the task completion degree. In real-world problems, the rewards are predominantly human-designed, which requires laborious tuning, and is easily affected by human cognitive biases. To achieve automatic auxiliary reward generation, we propose a novel representation learning approach that can measure the ``transition distance'' between states. Building upon these representations, we introduce an auxiliary reward generation technique for both single-task and skill-chaining scenarios without the need for human knowledge. The proposed approach is evaluated in a wide range of manipulation tasks. The experiment results demonstrate the effectiveness of measuring the transition distance between states and the induced improvement by auxiliary rewards, which not only promotes better learning efficiency but also increases convergent stability.
IDRL: Identifying Identities in Multi-Agent Reinforcement Learning with Ambiguous Identities
Oct 24, 2022Multi-agent reinforcement learning(MARL) is a prevalent learning paradigm for solving stochastic games. In previous studies, agents in a game are defined to be teammates or enemies beforehand, and the relation of the agents is fixed throughout the game. Those works can hardly work in the games where the competitive and collaborative relationships are not public and dynamically changing, which is decided by the \textit{identities} of the agents. How to learn a successful policy in such a situation where the identities of agents are ambiguous is still a problem. Focusing on this problem, in this work, we develop a novel MARL framework: IDRL, which identifies the identities of the agents dynamically and then chooses the corresponding policy to perform in the task. In the IDRL framework, a relation network is constructed to deduce the identities of the multi-agents through feeling the kindness and hostility unleashed by other agents; a dangerous network is built to estimate the risk of the identification. We also propose an intrinsic reward to help train the relation network and the dangerous network to get a trade-off between the need to maximize external reward and the accuracy of identification. After identifying the cooperation-competition pattern among the agents, the proposed method IDRL applies one of the off-the-shelf MARL methods to learn the policy. Taking the poker game \textit{red-10} as the experiment environment, experiments show that the IDRL can achieve superior performance compared to the other MARL methods. Significantly, the relation network has the par performance to identify the identities of agents with top human players; the dangerous network reasonably avoids the risk of imperfect identification.