 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHealing Powers of BERT: How Task-Specific Fine-Tuning Recovers Corrupted Language Models
Paper and Code
Jun 20, 2024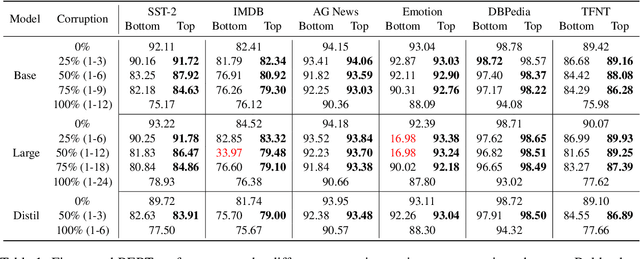

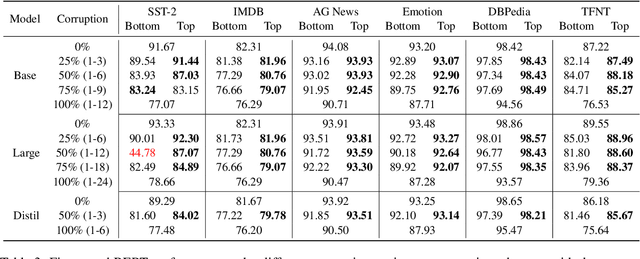
Language models like BERT excel at sentence classification tasks due to extensive pre-training on general data, but their robustness to parameter corruption is unexplored. To understand this better, we look at what happens if a language model is "broken", in the sense that some of its parameters are corrupted and then recovered by fine-tuning. Strategically corrupting BERT variants at different levels, we find corrupted models struggle to fully recover their original performance, with higher corruption causing more severe degradation. Notably, bottom-layer corruption affecting fundamental linguistic features is more detrimental than top-layer corruption. Our insights contribute to understanding language model robustness and adaptability under adverse conditions, informing strategies for developing resilient NLP systems against parameter perturbations.