 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRankAdaptor: Hierarchical Dynamic Low-Rank Adaptation for Structural Pruned LLMs
Paper and Code
Jun 22, 2024
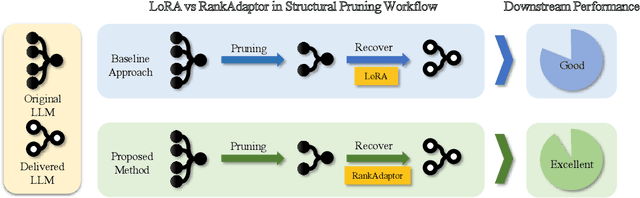
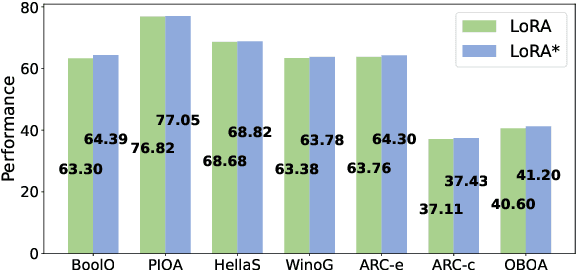
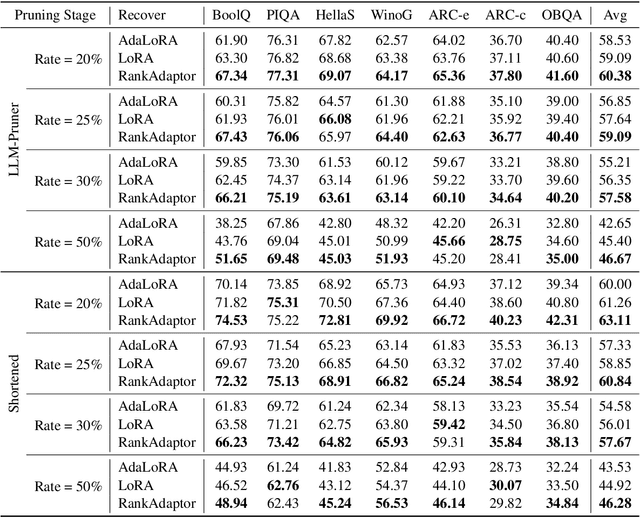
The efficient compression of large language models (LLMs) is becoming increasingly popular. However, recovering the accuracy of compressed LLMs is still a major challenge. Structural pruning with standard Low-Rank Adaptation (LoRA) is a common technique in current LLM compression. In structural pruning, the model architecture is modified unevenly, resulting in suboptimal performance in various downstream tasks via standard LoRA with fixed rank. To address this problem, we introduce RankAdaptor, an efficient fine-tuning method with hierarchical dynamic rank scheduling for pruned LLMs. An end-to-end automatic optimization flow is developed that utilizes a lightweight performance model to determine the different ranks during fine-tuning. Comprehensive experiments on popular benchmarks show that RankAdaptor consistently outperforms standard LoRA with structural pruning over different pruning settings. Without increasing the trainable parameters, RankAdaptor further reduces the accuracy performance gap between the recovery of the pruned model and the original model compared to standard LoRA.