 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoFusion-CAD: Structure-Aware Diffusion with Geometric State Space for Parametric 3D Design
Mar 23, 2026Parametric Computer-Aided Design (CAD) is fundamental to modern 3D modeling, yet existing methods struggle to generate long command sequences, especially under complex geometric and topological dependencies. Transformer-based architectures dominate CAD sequence generation due to their strong dependency modeling, but their quadratic attention cost and limited context windowing hinder scalability to long programs. We propose GeoFusion-CAD, an end-to-end diffusion framework for scalable and structure-aware generation. Our proposal encodes CAD programs as hierarchical trees, jointly capturing geometry and topology within a state-space diffusion process. Specifically, a lightweight C-Mamba block models long-range structural dependencies through selective state transitions, enabling coherent generation across extended command sequences. To support long-sequence evaluation, we introduce DeepCAD-240, an extended benchmark that increases the sequence length ranging from 40 to 240 while preserving sketch-extrusion semantics from the ABC dataset. Extensive experiments demonstrate that GeoFusion-CAD achieves superior performance on both short and long command ranges, maintaining high geometric fidelity and topological consistency where Transformer-based models degrade. Our approach sets new state-of-the-art scores for long-sequence parametric CAD generation, establishing a scalable foundation for next-generation CAD modeling systems. Code and datasets are available at GitHub.
Mitigating Hallucination of Large Vision-Language Models via Dynamic Logits Calibration
Jun 26, 2025Large Vision-Language Models (LVLMs) have demonstrated significant advancements in multimodal understanding, yet they are frequently hampered by hallucination-the generation of text that contradicts visual input. Existing training-free decoding strategies exhibit critical limitations, including the use of static constraints that do not adapt to semantic drift during generation, inefficiency stemming from the need for multiple forward passes, and degradation of detail due to overly rigid intervention rules. To overcome these challenges, this paper introduces Dynamic Logits Calibration (DLC), a novel training-free decoding framework designed to dynamically align text generation with visual evidence at inference time. At the decoding phase, DLC step-wise employs CLIP to assess the semantic alignment between the input image and the generated text sequence. Then, the Relative Visual Advantage (RVA) of candidate tokens is evaluated against a dynamically updated contextual baseline, adaptively adjusting output logits to favor tokens that are visually grounded. Furthermore, an adaptive weighting mechanism, informed by a real-time context alignment score, carefully balances the visual guidance while ensuring the overall quality of the textual output. Extensive experiments conducted across diverse benchmarks and various LVLM architectures (such as LLaVA, InstructBLIP, and MiniGPT-4) demonstrate that DLC significantly reduces hallucinations, outperforming current methods while maintaining high inference efficiency by avoiding multiple forward passes. Overall, we present an effective and efficient decoding-time solution to mitigate hallucinations, thereby enhancing the reliability of LVLMs for more practices. Code will be released on Github.
C3S3: Complementary Competition and Contrastive Selection for Semi-Supervised Medical Image Segmentation
Jun 09, 2025For the immanent challenge of insufficiently annotated samples in the medical field, semi-supervised medical image segmentation (SSMIS) offers a promising solution. Despite achieving impressive results in delineating primary target areas, most current methodologies struggle to precisely capture the subtle details of boundaries. This deficiency often leads to significant diagnostic inaccuracies. To tackle this issue, we introduce C3S3, a novel semi-supervised segmentation model that synergistically integrates complementary competition and contrastive selection. This design significantly sharpens boundary delineation and enhances overall precision. Specifically, we develop an $\textit{Outcome-Driven Contrastive Learning}$ module dedicated to refining boundary localization. Additionally, we incorporate a $\textit{Dynamic Complementary Competition}$ module that leverages two high-performing sub-networks to generate pseudo-labels, thereby further improving segmentation quality. The proposed C3S3 undergoes rigorous validation on two publicly accessible datasets, encompassing the practices of both MRI and CT scans. The results demonstrate that our method achieves superior performance compared to previous cutting-edge competitors. Especially, on the 95HD and ASD metrics, our approach achieves a notable improvement of at least $6\%$, highlighting the significant advancements. The code is available at https://github.com/Y-TARL/C3S3.
Decoupled Competitive Framework for Semi-supervised Medical Image Segmentation
May 30, 2025Confronting the critical challenge of insufficiently annotated samples in medical domain, semi-supervised medical image segmentation (SSMIS) emerges as a promising solution. Specifically, most methodologies following the Mean Teacher (MT) or Dual Students (DS) architecture have achieved commendable results. However, to date, these approaches face a performance bottleneck due to two inherent limitations, \textit{e.g.}, the over-coupling problem within MT structure owing to the employment of exponential moving average (EMA) mechanism, as well as the severe cognitive bias between two students of DS structure, both of which potentially lead to reduced efficacy, or even model collapse eventually. To mitigate these issues, a Decoupled Competitive Framework (DCF) is elaborated in this work, which utilizes a straightforward competition mechanism for the update of EMA, effectively decoupling students and teachers in a dynamical manner. In addition, the seamless exchange of invaluable and precise insights is facilitated among students, guaranteeing a better learning paradigm. The DCF introduced undergoes rigorous validation on three publicly accessible datasets, which encompass both 2D and 3D datasets. The results demonstrate the superiority of our method over previous cutting-edge competitors. Code will be available at https://github.com/JiaheChen2002/DCF.
High Fidelity Scene Text Synthesis
May 23, 2024

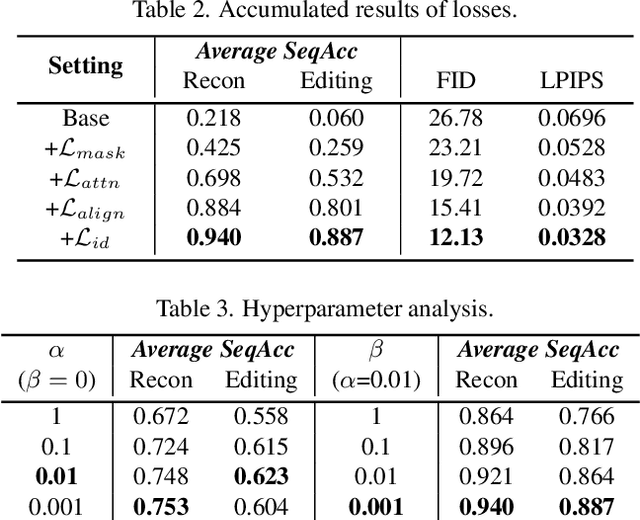

Scene text synthesis involves rendering specified texts onto arbitrary images. Current methods typically formulate this task in an end-to-end manner but lack effective character-level guidance during training. Besides, their text encoders, pre-trained on a single font type, struggle to adapt to the diverse font styles encountered in practical applications. Consequently, these methods suffer from character distortion, repetition, and absence, particularly in polystylistic scenarios. To this end, this paper proposes DreamText for high-fidelity scene text synthesis. Our key idea is to reconstruct the diffusion training process, introducing more refined guidance tailored to this task, to expose and rectify the model's attention at the character level and strengthen its learning of text regions. This transformation poses a hybrid optimization challenge, involving both discrete and continuous variables. To effectively tackle this challenge, we employ a heuristic alternate optimization strategy. Meanwhile, we jointly train the text encoder and generator to comprehensively learn and utilize the diverse font present in the training dataset. This joint training is seamlessly integrated into the alternate optimization process, fostering a synergistic relationship between learning character embedding and re-estimating character attention. Specifically, in each step, we first encode potential character-generated position information from cross-attention maps into latent character masks. These masks are then utilized to update the representation of specific characters in the current step, which, in turn, enables the generator to correct the character's attention in the subsequent steps. Both qualitative and quantitative results demonstrate the superiority of our method to the state of the art.
PrimeComposer: Faster Progressively Combined Diffusion for Image Composition with Attention Steering
Mar 08, 2024



Image composition involves seamlessly integrating given objects into a specific visual context. The current training-free methods rely on composing attention weights from several samplers to guide the generator. However, since these weights are derived from disparate contexts, their combination leads to coherence confusion in synthesis and loss of appearance information. These issues worsen with their excessive focus on background generation, even when unnecessary in this task. This not only slows down inference but also compromises foreground generation quality. Moreover, these methods introduce unwanted artifacts in the transition area. In this paper, we formulate image composition as a subject-based local editing task, solely focusing on foreground generation. At each step, the edited foreground is combined with the noisy background to maintain scene consistency. To address the remaining issues, we propose PrimeComposer, a faster training-free diffuser that composites the images by well-designed attention steering across different noise levels. This steering is predominantly achieved by our Correlation Diffuser, utilizing its self-attention layers at each step. Within these layers, the synthesized subject interacts with both the referenced object and background, capturing intricate details and coherent relationships. This prior information is encoded into the attention weights, which are then integrated into the self-attention layers of the generator to guide the synthesis process. Besides, we introduce a Region-constrained Cross-Attention to confine the impact of specific subject-related words to desired regions, addressing the unwanted artifacts shown in the prior method thereby further improving the coherence in the transition area. Our method exhibits the fastest inference efficiency and extensive experiments demonstrate our superiority both qualitatively and quantitatively.
Enhancing Object Coherence in Layout-to-Image Synthesis
Nov 25, 2023



Layout-to-image synthesis is an emerging technique in conditional image generation. It aims to generate complex scenes, where users require fine control over the layout of the objects in a scene. However, it remains challenging to control the object coherence, including semantic coherence (e.g., the cat looks at the flowers or not) and physical coherence (e.g., the hand and the racket should not be misaligned). In this paper, we propose a novel diffusion model with effective global semantic fusion (GSF) and self-similarity feature enhancement modules to guide the object coherence for this task. For semantic coherence, we argue that the image caption contains rich information for defining the semantic relationship within the objects in the images. Instead of simply employing cross-attention between captions and generated images, which addresses the highly relevant layout restriction and semantic coherence separately and thus leads to unsatisfying results shown in our experiments, we develop GSF to fuse the supervision from the layout restriction and semantic coherence requirement and exploit it to guide the image synthesis process. Moreover, to improve the physical coherence, we develop a Self-similarity Coherence Attention (SCA) module to explicitly integrate local contextual physical coherence into each pixel's generation process. Specifically, we adopt a self-similarity map to encode the coherence restrictions and employ it to extract coherent features from text embedding. Through visualization of our self-similarity map, we explore the essence of SCA, revealing that its effectiveness is not only in capturing reliable physical coherence patterns but also in enhancing complex texture generation. Extensive experiments demonstrate the superiority of our proposed method in both image generation quality and controllability.
High-fidelity Person-centric Subject-to-Image Synthesis
Nov 17, 2023



Current subject-driven image generation methods encounter significant challenges in person-centric image generation. The reason is that they learn the semantic scene and person generation by fine-tuning a common pre-trained diffusion, which involves an irreconcilable training imbalance. Precisely, to generate realistic persons, they need to sufficiently tune the pre-trained model, which inevitably causes the model to forget the rich semantic scene prior and makes scene generation over-fit to the training data. Moreover, even with sufficient fine-tuning, these methods can still not generate high-fidelity persons since joint learning of the scene and person generation also lead to quality compromise. In this paper, we propose Face-diffuser, an effective collaborative generation pipeline to eliminate the above training imbalance and quality compromise. Specifically, we first develop two specialized pre-trained diffusion models, i.e., Text-driven Diffusion Model (TDM) and Subject-augmented Diffusion Model (SDM), for scene and person generation, respectively. The sampling process is divided into three sequential stages, i.e., semantic scene construction, subject-scene fusion, and subject enhancement. The first and last stages are performed by TDM and SDM respectively. The subject-scene fusion stage, that is the collaboration achieved through a novel and highly effective mechanism, Saliency-adaptive Noise Fusion (SNF). Specifically, it is based on our key observation that there exists a robust link between classifier-free guidance responses and the saliency of generated images. In each time step, SNF leverages the unique strengths of each model and allows for the spatial blending of predicted noises from both models automatically in a saliency-aware manner. Extensive experiments confirm the impressive effectiveness and robustness of the Face-diffuser.
GA-HQS: MRI reconstruction via a generically accelerated unfolding approach
Apr 06, 2023



Deep unfolding networks (DUNs) are the foremost methods in the realm of compressed sensing MRI, as they can employ learnable networks to facilitate interpretable forward-inference operators. However, several daunting issues still exist, including the heavy dependency on the first-order optimization algorithms, the insufficient information fusion mechanisms, and the limitation of capturing long-range relationships. To address the issues, we propose a Generically Accelerated Half-Quadratic Splitting (GA-HQS) algorithm that incorporates second-order gradient information and pyramid attention modules for the delicate fusion of inputs at the pixel level. Moreover, a multi-scale split transformer is also designed to enhance the global feature representation. Comprehensive experiments demonstrate that our method surpasses previous ones on single-coil MRI acceleration tasks.
Image Denoising Using Sparsifying Transform Learning and Weighted Singular Values Minimization
Apr 02, 2020
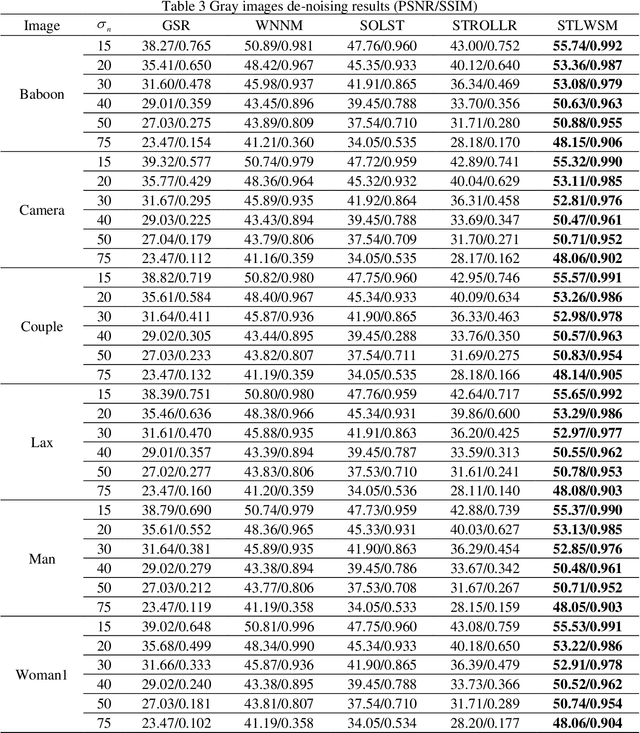
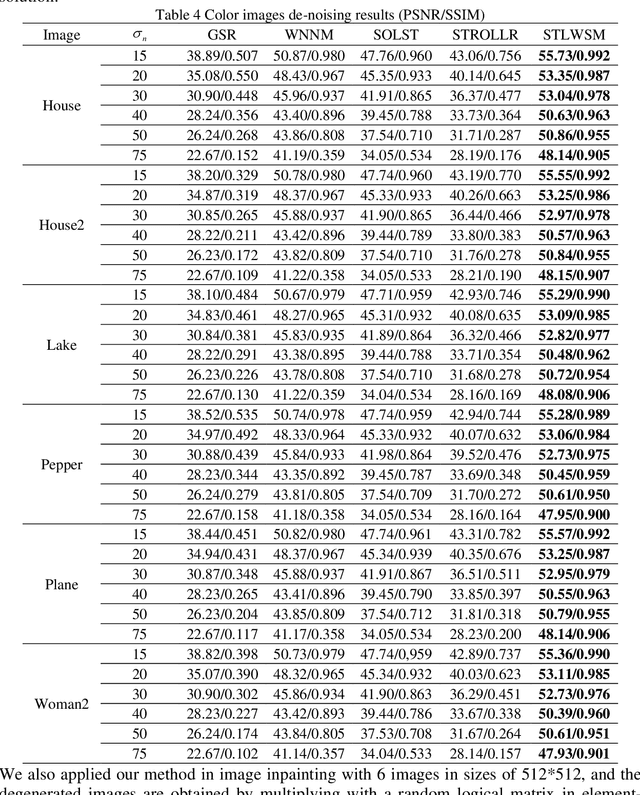
In image denoising (IDN) processing, the low-rank property is usually considered as an important image prior. As a convex relaxation approximation of low rank, nuclear norm based algorithms and their variants have attracted significant attention. These algorithms can be collectively called image domain based methods, whose common drawback is the requirement of great number of iterations for some acceptable solution. Meanwhile, the sparsity of images in a certain transform domain has also been exploited in image denoising problems. Sparsity transform learning algorithms can achieve extremely fast computations as well as desirable performance. By taking both advantages of image domain and transform domain in a general framework, we propose a sparsity transform learning and weighted singular values minimization method (STLWSM) for IDN problems. The proposed method can make full use of the preponderance of both domains. For solving the non-convex cost function, we also present an efficient alternative solution for acceleration. Experimental results show that the proposed STLWSM achieves improvement both visually and quantitatively with a large margin over state-of-the-art approaches based on an alternatively single domain. It also needs much less iteration than all the image domain algorithms.