 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR-LLaVA: Improving Med-VQA Understanding through Visual Region of Interest
Oct 27, 2024



Artificial intelligence has made significant strides in medical visual question answering (Med-VQA), yet prevalent studies often interpret images holistically, overlooking the visual regions of interest that may contain crucial information, potentially aligning with a doctor's prior knowledge that can be incorporated with minimal annotations (e.g., bounding boxes). To address this gap, this paper introduces R-LLaVA, designed to enhance biomedical VQA understanding by integrating simple medical annotations as prior knowledge directly into the image space through CLIP. These annotated visual regions of interest are then fed into the LLaVA model during training, aiming to enrich the model's understanding of biomedical queries. Experimental evaluation on four standard Med-VQA datasets demonstrates R-LLaVA's superiority over existing state-of-the-art (SoTA) methods. Additionally, to verify the model's capability in visual comprehension, a novel multiple-choice medical visual understanding dataset is introduced, confirming the positive impact of focusing on visual regions of interest in advancing biomedical VQA understanding.
Test Time Learning for Time Series Forecasting
Sep 21, 2024Time-series forecasting has seen significant advancements with the introduction of token prediction mechanisms such as multi-head attention. However, these methods often struggle to achieve the same performance as in language modeling, primarily due to the quadratic computational cost and the complexity of capturing long-range dependencies in time-series data. State-space models (SSMs), such as Mamba, have shown promise in addressing these challenges by offering efficient solutions with linear RNNs capable of modeling long sequences with larger context windows. However, there remains room for improvement in accuracy and scalability. We propose the use of Test-Time Training (TTT) modules in a parallel architecture to enhance performance in long-term time series forecasting. Through extensive experiments on standard benchmark datasets, we demonstrate that TTT modules consistently outperform state-of-the-art models, including the Mamba-based TimeMachine, particularly in scenarios involving extended sequence and prediction lengths. Our results show significant improvements in Mean Squared Error (MSE) and Mean Absolute Error (MAE), especially on larger datasets such as Electricity, Traffic, and Weather, underscoring the effectiveness of TTT in capturing long-range dependencies. Additionally, we explore various convolutional architectures within the TTT framework, showing that even simple configurations like 1D convolution with small filters can achieve competitive results. This work sets a new benchmark for time-series forecasting and lays the groundwork for future research in scalable, high-performance forecasting models.
Using the Split Bregman Algorithm to Solve the Self-Repelling Snake Model
Mar 28, 2020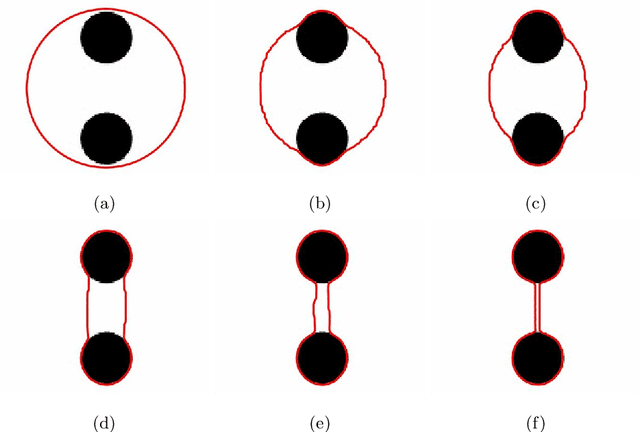

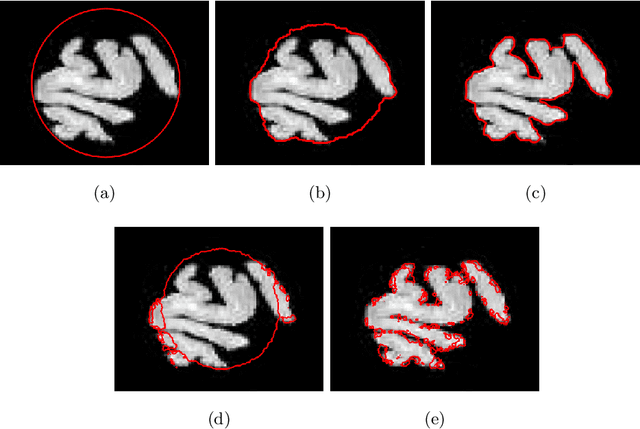

Preserving the contour topology during image segmentation is useful in manypractical scenarios. By keeping the contours isomorphic, it is possible to pre-vent over-segmentation and under-segmentation, as well as to adhere to giventopologies. The self-repelling snake model (SR) is a variational model thatpreserves contour topology by combining a non-local repulsion term with thegeodesic active contour model (GAC). The SR is traditionally solved using theadditive operator splitting (AOS) scheme. Although this solution is stable, thememory requirement grows quickly as the image size increases. In our paper,we propose an alternative solution to the SR using the Split Bregman method.Our algorithm breaks the problem down into simpler subproblems to use lower-order evolution equations and approximation schemes. The memory usage issignificantly reduced as a result. Experiments show comparable performance to the original algorithm with shorter iteration times.