 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Document QA with Chain-of-Structured-Thought and Fine-Tuned SLMs
Mar 31, 2026Large language models (LLMs) are widely applied to data analytics over documents, yet direct reasoning over long, noisy documents remains brittle and error-prone. Hence, we study document question answering (QA) that consolidates dispersed evidence into a structured output (e.g., a table, graph, or chunks) to support reliable, verifiable QA. We propose a two-pillar framework, LiteCoST, to achieve both high accuracy and low latency with small language models (SLMs). Pillar 1: Chain-of-Structured-Thought (CoST). We introduce a CoST template, a schema-aware instruction that guides a strong LLM to produce both a step-wise CoST trace and the corresponding structured output. The process induces a minimal structure, normalizes entities/units, aligns records, serializes the output, and verifies/refines it, yielding auditable supervision. Pillar 2: SLM fine-tuning. The compact models are trained on LLM-generated CoST data in two stages: Supervised Fine-Tuning for structural alignment, followed by Group Relative Policy Optimization (GRPO) incorporating triple rewards for answer/format quality and process consistency. By distilling structure-first behavior into SLMs, this approach achieves LLM-comparable quality on multi-domain long-document QA using 3B/7B SLMs, while delivering 2-4x lower latency than GPT-4o and DeepSeek-R1 (671B). The code is available at https://github.com/HKUSTDial/LiteCoST.
You Are What You Bought: Generating Customer Personas for E-commerce Applications
Apr 24, 2025In e-commerce, user representations are essential for various applications. Existing methods often use deep learning techniques to convert customer behaviors into implicit embeddings. However, these embeddings are difficult to understand and integrate with external knowledge, limiting the effectiveness of applications such as customer segmentation, search navigation, and product recommendations. To address this, our paper introduces the concept of the customer persona. Condensed from a customer's numerous purchasing histories, a customer persona provides a multi-faceted and human-readable characterization of specific purchase behaviors and preferences, such as Busy Parents or Bargain Hunters. This work then focuses on representing each customer by multiple personas from a predefined set, achieving readable and informative explicit user representations. To this end, we propose an effective and efficient solution GPLR. To ensure effectiveness, GPLR leverages pre-trained LLMs to infer personas for customers. To reduce overhead, GPLR applies LLM-based labeling to only a fraction of users and utilizes a random walk technique to predict personas for the remaining customers. We further propose RevAff, which provides an absolute error $\epsilon$ guarantee while improving the time complexity of the exact solution by a factor of at least $O(\frac{\epsilon\cdot|E|N}{|E|+N\log N})$, where $N$ represents the number of customers and products, and $E$ represents the interactions between them. We evaluate the performance of our persona-based representation in terms of accuracy and robustness for recommendation and customer segmentation tasks using three real-world e-commerce datasets. Most notably, we find that integrating customer persona representations improves the state-of-the-art graph convolution-based recommendation model by up to 12% in terms of NDCG@K and F1-Score@K.
Rethinking E-Commerce Search
Dec 06, 2023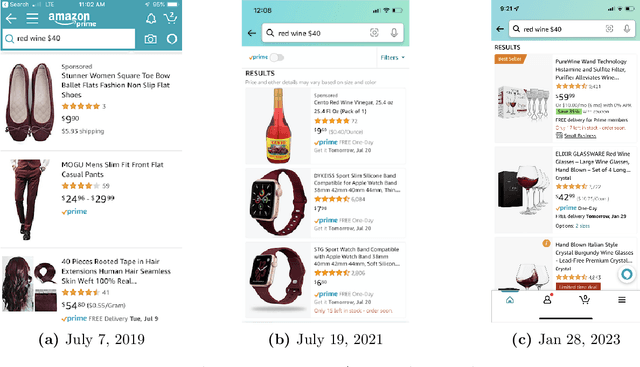
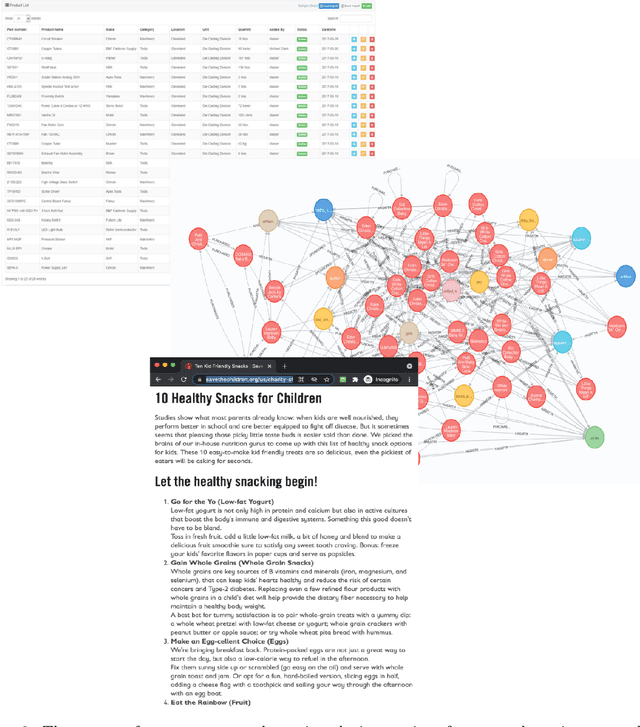
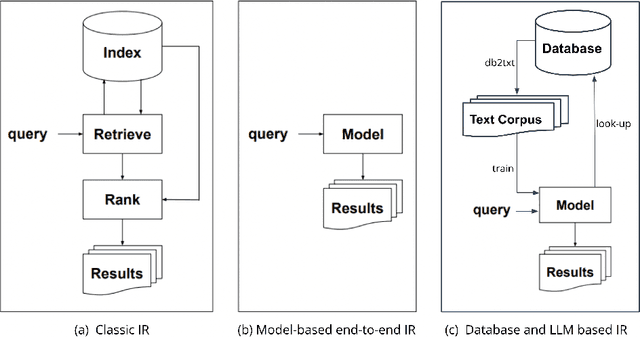

E-commerce search and recommendation usually operate on structured data such as product catalogs and taxonomies. However, creating better search and recommendation systems often requires a large variety of unstructured data including customer reviews and articles on the web. Traditionally, the solution has always been converting unstructured data into structured data through information extraction, and conducting search over the structured data. However, this is a costly approach that often has low quality. In this paper, we envision a solution that does entirely the opposite. Instead of converting unstructured data (web pages, customer reviews, etc) to structured data, we instead convert structured data (product inventory, catalogs, taxonomies, etc) into textual data, which can be easily integrated into the text corpus that trains LLMs. Then, search and recommendation can be performed through a Q/A mechanism through an LLM instead of using traditional information retrieval methods over structured data.
Mitigating Pooling Bias in E-commerce Search via False Negative Estimation
Nov 18, 2023
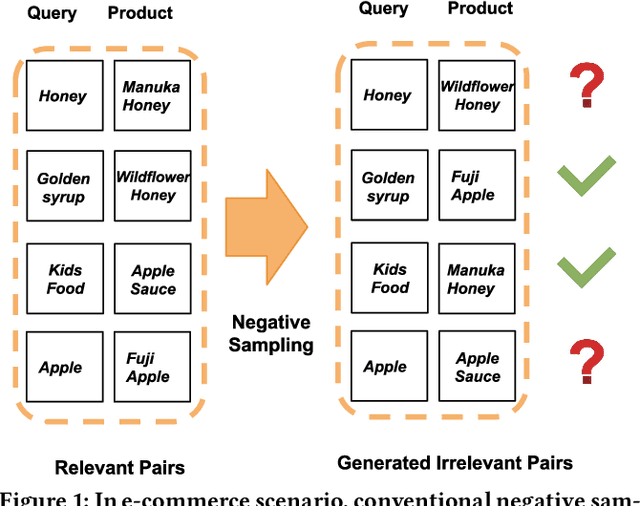
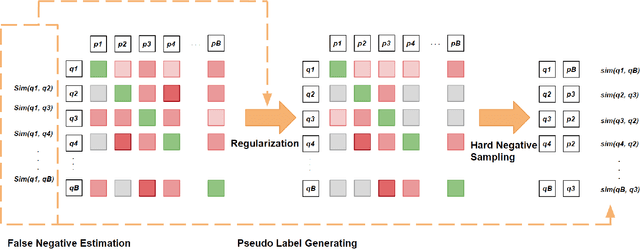
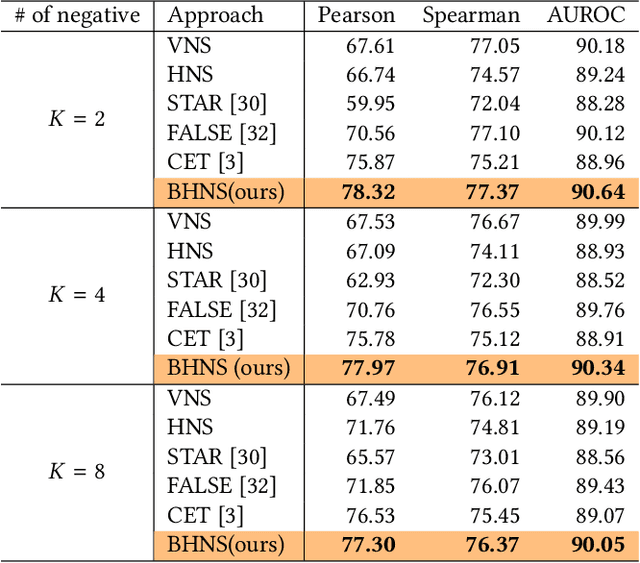
Efficient and accurate product relevance assessment is critical for user experiences and business success. Training a proficient relevance assessment model requires high-quality query-product pairs, often obtained through negative sampling strategies. Unfortunately, current methods introduce pooling bias by mistakenly sampling false negatives, diminishing performance and business impact. To address this, we present Bias-mitigating Hard Negative Sampling (BHNS), a novel negative sampling strategy tailored to identify and adjust for false negatives, building upon our original False Negative Estimation algorithm. Our experiments in the Instacart search setting confirm BHNS as effective for practical e-commerce use. Furthermore, comparative analyses on public dataset showcase its domain-agnostic potential for diverse applications.
An Embedding-Based Grocery Search Model at Instacart
Sep 12, 2022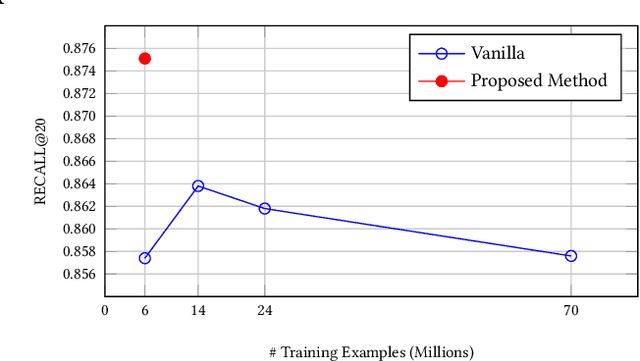

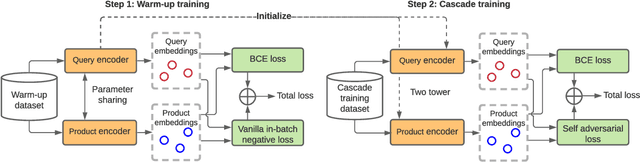
The key to e-commerce search is how to best utilize the large yet noisy log data. In this paper, we present our embedding-based model for grocery search at Instacart. The system learns query and product representations with a two-tower transformer-based encoder architecture. To tackle the cold-start problem, we focus on content-based features. To train the model efficiently on noisy data, we propose a self-adversarial learning method and a cascade training method. AccOn an offline human evaluation dataset, we achieve 10% relative improvement in RECALL@20, and for online A/B testing, we achieve 4.1% cart-adds per search (CAPS) and 1.5% gross merchandise value (GMV) improvement. We describe how we train and deploy the embedding based search model and give a detailed analysis of the effectiveness of our method.
From Intrinsic to Counterfactual: On the Explainability of Contextualized Recommender Systems
Oct 28, 2021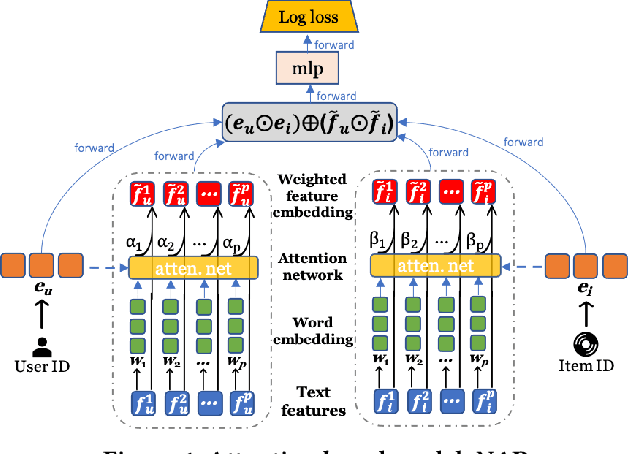

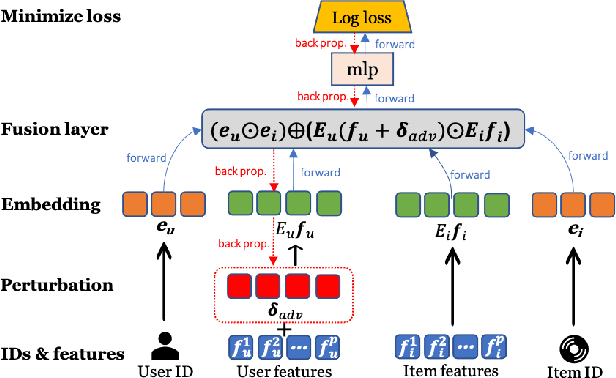
With the prevalence of deep learning based embedding approaches, recommender systems have become a proven and indispensable tool in various information filtering applications. However, many of them remain difficult to diagnose what aspects of the deep models' input drive the final ranking decision, thus, they cannot often be understood by human stakeholders. In this paper, we investigate the dilemma between recommendation and explainability, and show that by utilizing the contextual features (e.g., item reviews from users), we can design a series of explainable recommender systems without sacrificing their performance. In particular, we propose three types of explainable recommendation strategies with gradual change of model transparency: whitebox, graybox, and blackbox. Each strategy explains its ranking decisions via different mechanisms: attention weights, adversarial perturbations, and counterfactual perturbations. We apply these explainable models on five real-world data sets under the contextualized setting where users and items have explicit interactions. The empirical results show that our model achieves highly competitive ranking performance, and generates accurate and effective explanations in terms of numerous quantitative metrics and qualitative visualizations.
Ultra-Fine Entity Typing with Weak Supervision from a Masked Language Model
Jun 08, 2021

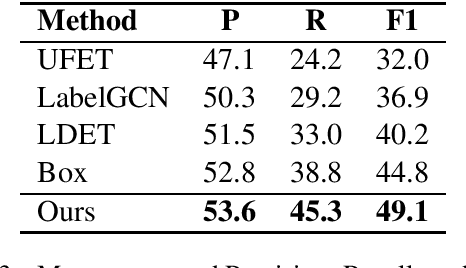
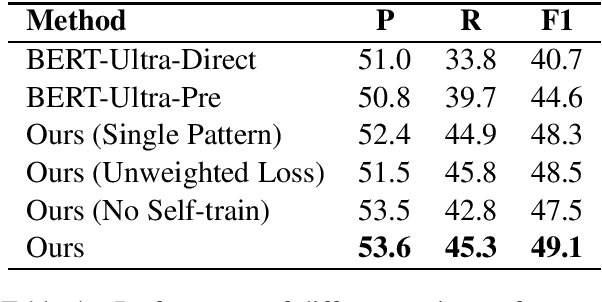
Recently, there is an effort to extend fine-grained entity typing by using a richer and ultra-fine set of types, and labeling noun phrases including pronouns and nominal nouns instead of just named entity mentions. A key challenge for this ultra-fine entity typing task is that human annotated data are extremely scarce, and the annotation ability of existing distant or weak supervision approaches is very limited. To remedy this problem, in this paper, we propose to obtain training data for ultra-fine entity typing by using a BERT Masked Language Model (MLM). Given a mention in a sentence, our approach constructs an input for the BERT MLM so that it predicts context dependent hypernyms of the mention, which can be used as type labels. Experimental results demonstrate that, with the help of these automatically generated labels, the performance of an ultra-fine entity typing model can be improved substantially. We also show that our approach can be applied to improve traditional fine-grained entity typing after performing simple type mapping.
SpatialNLI: A Spatial Domain Natural Language Interface to Databases Using Spatial Comprehension
Aug 28, 2019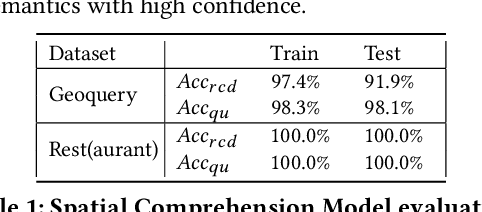
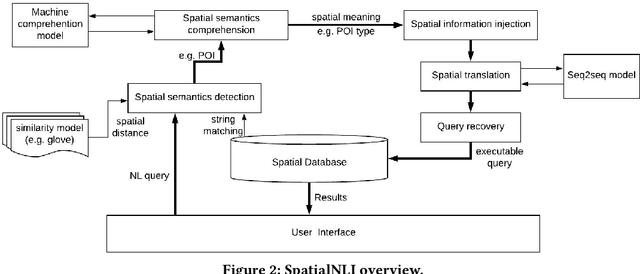
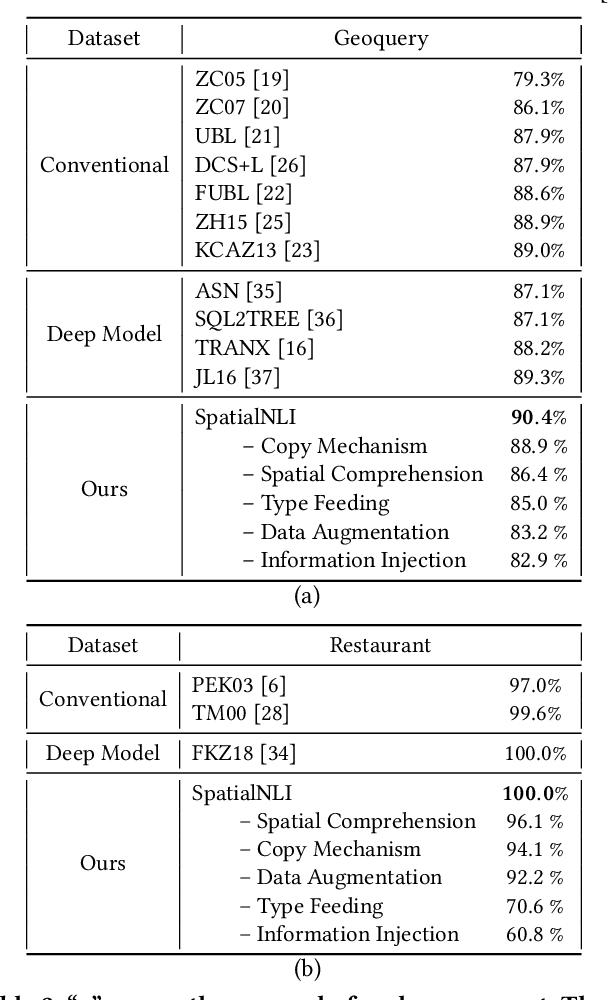

A natural language interface (NLI) to databases is an interface that translates a natural language question to a structured query that is executable by database management systems (DBMS). However, an NLI that is trained in the general domain is hard to apply in the spatial domain due to the idiosyncrasy and expressiveness of the spatial questions. Inspired by the machine comprehension model, we propose a spatial comprehension model that is able to recognize the meaning of spatial entities based on the semantics of the context. The spatial semantics learned from the spatial comprehension model is then injected to the natural language question to ease the burden of capturing the spatial-specific semantics. With our spatial comprehension model and information injection, our NLI for the spatial domain, named SpatialNLI, is able to capture the semantic structure of the question and translate it to the corresponding syntax of an executable query accurately. We also experimentally ascertain that SpatialNLI outperforms state-of-the-art methods.
KBQA: Learning Question Answering over QA Corpora and Knowledge Bases
Mar 06, 2019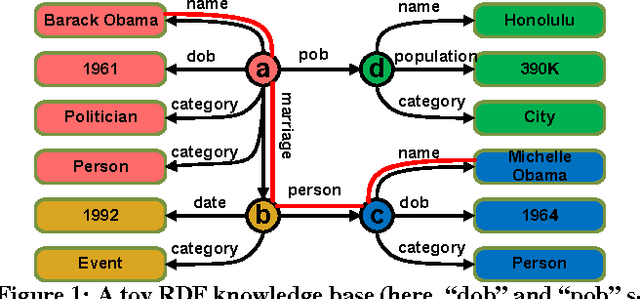

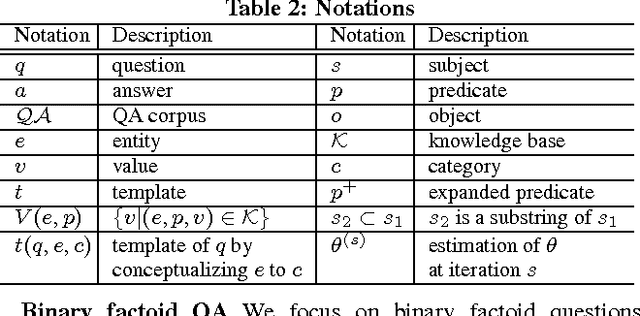
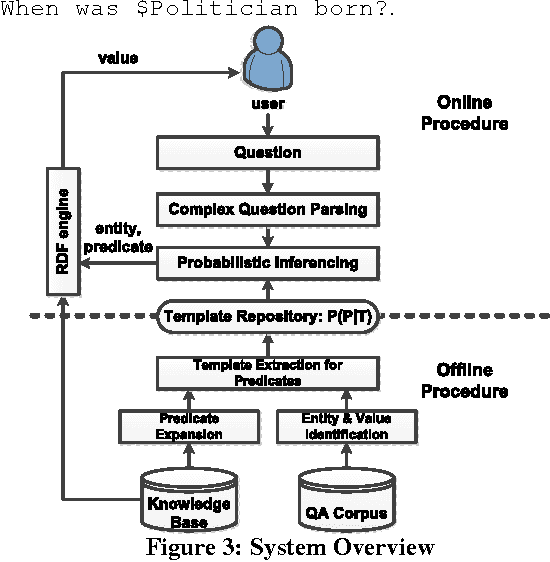
Question answering (QA) has become a popular way for humans to access billion-scale knowledge bases. Unlike web search, QA over a knowledge base gives out accurate and concise results, provided that natural language questions can be understood and mapped precisely to structured queries over the knowledge base. The challenge, however, is that a human can ask one question in many different ways. Previous approaches have natural limits due to their representations: rule based approaches only understand a small set of "canned" questions, while keyword based or synonym based approaches cannot fully understand the questions. In this paper, we design a new kind of question representation: templates, over a billion scale knowledge base and a million scale QA corpora. For example, for questions about a city's population, we learn templates such as What's the population of $city?, How many people are there in $city?. We learned 27 million templates for 2782 intents. Based on these templates, our QA system KBQA effectively supports binary factoid questions, as well as complex questions which are composed of a series of binary factoid questions. Furthermore, we expand predicates in RDF knowledge base, which boosts the coverage of knowledge base by 57 times. Our QA system beats all other state-of-art works on both effectiveness and efficiency over QALD benchmarks.
A Transfer-Learnable Natural Language Interface for Databases
Sep 07, 2018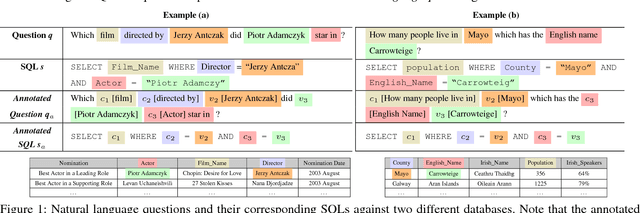
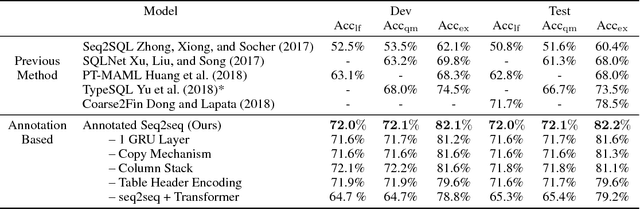
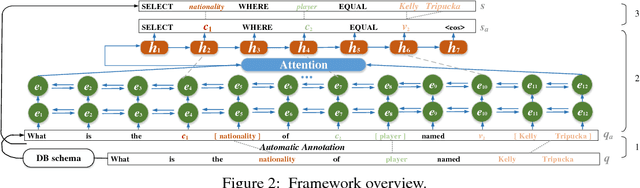
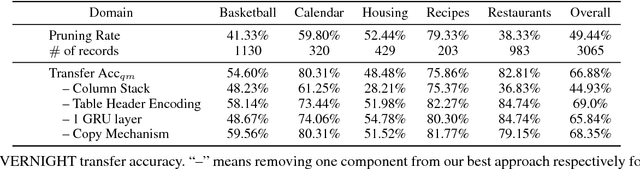
Relational database management systems (RDBMSs) are powerful because they are able to optimize and answer queries against any relational database. A natural language interface (NLI) for a database, on the other hand, is tailored to support that specific database. In this work, we introduce a general purpose transfer-learnable NLI with the goal of learning one model that can be used as NLI for any relational database. We adopt the data management principle of separating data and its schema, but with the additional support for the idiosyncrasy and complexity of natural languages. Specifically, we introduce an automatic annotation mechanism that separates the schema and the data, where the schema also covers knowledge about natural language. Furthermore, we propose a customized sequence model that translates annotated natural language queries to SQL statements. We show in experiments that our approach outperforms previous NLI methods on the WikiSQL dataset and the model we learned can be applied to another benchmark dataset OVERNIGHT without retraining.