 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Pooling Bias in E-commerce Search via False Negative Estimation
Nov 18, 2023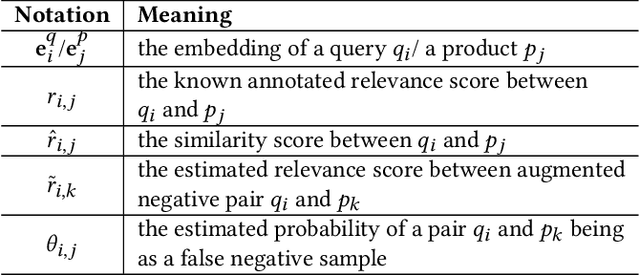
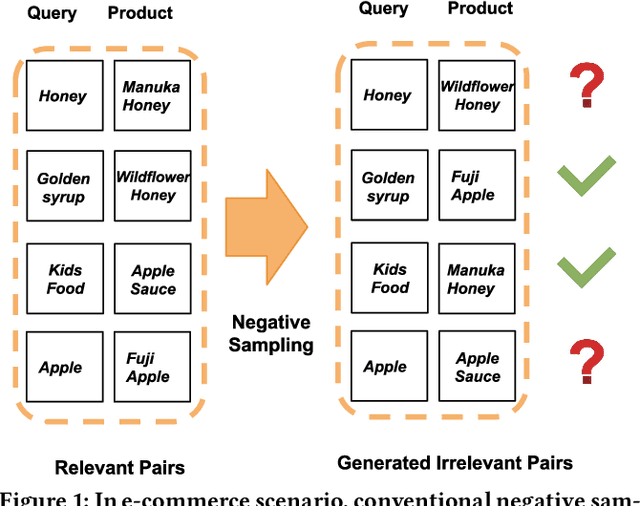
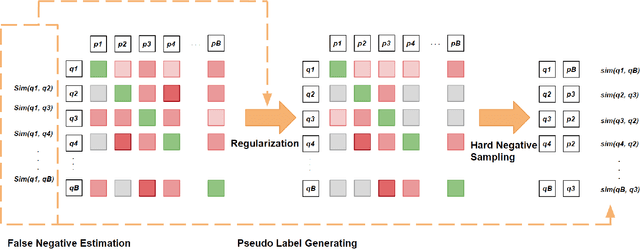
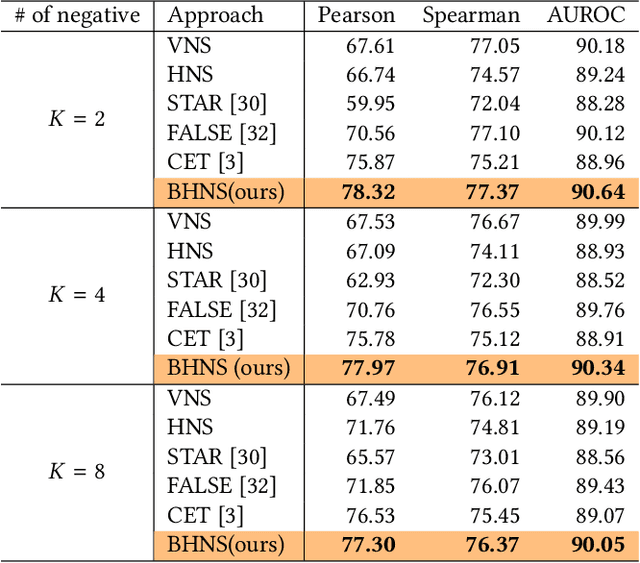
Efficient and accurate product relevance assessment is critical for user experiences and business success. Training a proficient relevance assessment model requires high-quality query-product pairs, often obtained through negative sampling strategies. Unfortunately, current methods introduce pooling bias by mistakenly sampling false negatives, diminishing performance and business impact. To address this, we present Bias-mitigating Hard Negative Sampling (BHNS), a novel negative sampling strategy tailored to identify and adjust for false negatives, building upon our original False Negative Estimation algorithm. Our experiments in the Instacart search setting confirm BHNS as effective for practical e-commerce use. Furthermore, comparative analyses on public dataset showcase its domain-agnostic potential for diverse applications.
An Embedding-Based Grocery Search Model at Instacart
Sep 12, 2022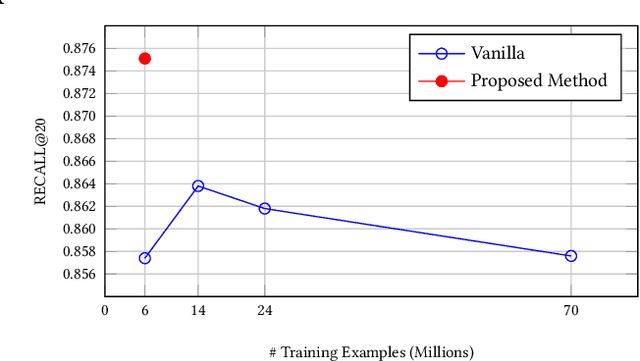

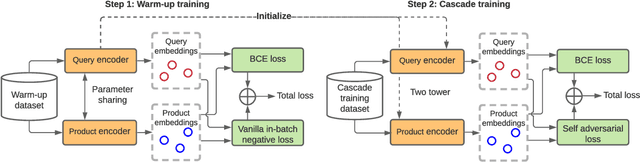
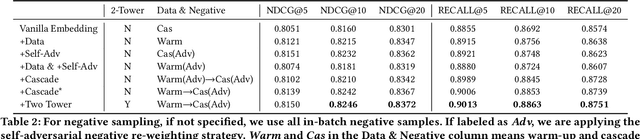
The key to e-commerce search is how to best utilize the large yet noisy log data. In this paper, we present our embedding-based model for grocery search at Instacart. The system learns query and product representations with a two-tower transformer-based encoder architecture. To tackle the cold-start problem, we focus on content-based features. To train the model efficiently on noisy data, we propose a self-adversarial learning method and a cascade training method. AccOn an offline human evaluation dataset, we achieve 10% relative improvement in RECALL@20, and for online A/B testing, we achieve 4.1% cart-adds per search (CAPS) and 1.5% gross merchandise value (GMV) improvement. We describe how we train and deploy the embedding based search model and give a detailed analysis of the effectiveness of our method.