 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDNAMite: Interpretable Calibrated Survival Analysis with Discretized Additive Models
Nov 08, 2024Survival analysis is a classic problem in statistics with important applications in healthcare. Most machine learning models for survival analysis are black-box models, limiting their use in healthcare settings where interpretability is paramount. More recently, glass-box machine learning models have been introduced for survival analysis, with both strong predictive performance and interpretability. Still, several gaps remain, as no prior glass-box survival model can produce calibrated shape functions with enough flexibility to capture the complex patterns often found in real data. To fill this gap, we introduce a new glass-box machine learning model for survival analysis called DNAMite. DNAMite uses feature discretization and kernel smoothing in its embedding module, making it possible to learn shape functions with a flexible balance of smoothness and jaggedness. Further, DNAMite produces calibrated shape functions that can be directly interpreted as contributions to the cumulative incidence function. Our experiments show that DNAMite generates shape functions closer to true shape functions on synthetic data, while making predictions with comparable predictive performance and better calibration than previous glass-box and black-box models.
Interpretable Prediction and Feature Selection for Survival Analysis
Apr 23, 2024Survival analysis is widely used as a technique to model time-to-event data when some data is censored, particularly in healthcare for predicting future patient risk. In such settings, survival models must be both accurate and interpretable so that users (such as doctors) can trust the model and understand model predictions. While most literature focuses on discrimination, interpretability is equally as important. A successful interpretable model should be able to describe how changing each feature impacts the outcome, and should only use a small number of features. In this paper, we present DyS (pronounced ``dice''), a new survival analysis model that achieves both strong discrimination and interpretability. DyS is a feature-sparse Generalized Additive Model, combining feature selection and interpretable prediction into one model. While DyS works well for all survival analysis problems, it is particularly useful for large (in $n$ and $p$) survival datasets such as those commonly found in observational healthcare studies. Empirical studies show that DyS competes with other state-of-the-art machine learning models for survival analysis, while being highly interpretable.
Interpretable Survival Analysis for Heart Failure Risk Prediction
Oct 24, 2023
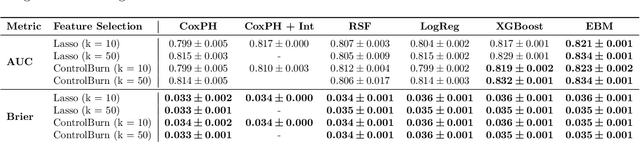


Survival analysis, or time-to-event analysis, is an important and widespread problem in healthcare research. Medical research has traditionally relied on Cox models for survival analysis, due to their simplicity and interpretability. Cox models assume a log-linear hazard function as well as proportional hazards over time, and can perform poorly when these assumptions fail. Newer survival models based on machine learning avoid these assumptions and offer improved accuracy, yet sometimes at the expense of model interpretability, which is vital for clinical use. We propose a novel survival analysis pipeline that is both interpretable and competitive with state-of-the-art survival models. Specifically, we use an improved version of survival stacking to transform a survival analysis problem to a classification problem, ControlBurn to perform feature selection, and Explainable Boosting Machines to generate interpretable predictions. To evaluate our pipeline, we predict risk of heart failure using a large-scale EHR database. Our pipeline achieves state-of-the-art performance and provides interesting and novel insights about risk factors for heart failure.
Cross-Frequency Time Series Meta-Forecasting
Feb 04, 2023



Meta-forecasting is a newly emerging field which combines meta-learning and time series forecasting. The goal of meta-forecasting is to train over a collection of source time series and generalize to new time series one-at-a-time. Previous approaches in meta-forecasting achieve competitive performance, but with the restriction of training a separate model for each sampling frequency. In this work, we investigate meta-forecasting over different sampling frequencies, and introduce a new model, the Continuous Frequency Adapter (CFA), specifically designed to learn frequency-invariant representations. We find that CFA greatly improves performance when generalizing to unseen frequencies, providing a first step towards forecasting over larger multi-frequency datasets.
The Missing Indicator Method: From Low to High Dimensions
Nov 16, 2022



Missing data is common in applied data science, particularly for tabular data sets found in healthcare, social sciences, and natural sciences. Most supervised learning methods work only on complete data, thus requiring preprocessing, such as missing value imputation, to work on incomplete data sets. However, imputation discards potentially useful information encoded by the pattern of missing values. For data sets with informative missing patterns, the Missing Indicator Method (MIM), which adds indicator variables to indicate the missing pattern, can be used in conjunction with imputation to improve model performance. We show experimentally that MIM improves performance for informative missing values, and we prove that MIM does not hurt linear models asymptotically for uninformative missing values. Nonetheless, MIM can increase variance if many of the added indicators are uninformative, causing harm particularly for high-dimensional data sets. To address this issue, we introduce Selective MIM (SMIM), a method that adds missing indicators only for features that have informative missing patterns. We show empirically that SMIM performs at least as well as MIM across a range of experimental settings, and improves MIM for high-dimensional data.