 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Predictive Models to Understand Risk Factors for Maternal and Fetal Outcomes
Oct 16, 2023Although most pregnancies result in a good outcome, complications are not uncommon and can be associated with serious implications for mothers and babies. Predictive modeling has the potential to improve outcomes through better understanding of risk factors, heightened surveillance for high risk patients, and more timely and appropriate interventions, thereby helping obstetricians deliver better care. We identify and study the most important risk factors for four types of pregnancy complications: (i) severe maternal morbidity, (ii) shoulder dystocia, (iii) preterm preeclampsia, and (iv) antepartum stillbirth. We use an Explainable Boosting Machine (EBM), a high-accuracy glass-box learning method, for prediction and identification of important risk factors. We undertake external validation and perform an extensive robustness analysis of the EBM models. EBMs match the accuracy of other black-box ML methods such as deep neural networks and random forests, and outperform logistic regression, while being more interpretable. EBMs prove to be robust. The interpretability of the EBM models reveals surprising insights into the features contributing to risk (e.g. maternal height is the second most important feature for shoulder dystocia) and may have potential for clinical application in the prediction and prevention of serious complications in pregnancy.
The Missing Indicator Method: From Low to High Dimensions
Nov 16, 2022



Missing data is common in applied data science, particularly for tabular data sets found in healthcare, social sciences, and natural sciences. Most supervised learning methods work only on complete data, thus requiring preprocessing, such as missing value imputation, to work on incomplete data sets. However, imputation discards potentially useful information encoded by the pattern of missing values. For data sets with informative missing patterns, the Missing Indicator Method (MIM), which adds indicator variables to indicate the missing pattern, can be used in conjunction with imputation to improve model performance. We show experimentally that MIM improves performance for informative missing values, and we prove that MIM does not hurt linear models asymptotically for uninformative missing values. Nonetheless, MIM can increase variance if many of the added indicators are uninformative, causing harm particularly for high-dimensional data sets. To address this issue, we introduce Selective MIM (SMIM), a method that adds missing indicators only for features that have informative missing patterns. We show empirically that SMIM performs at least as well as MIM across a range of experimental settings, and improves MIM for high-dimensional data.
Using Interpretable Machine Learning to Predict Maternal and Fetal Outcomes
Jul 12, 2022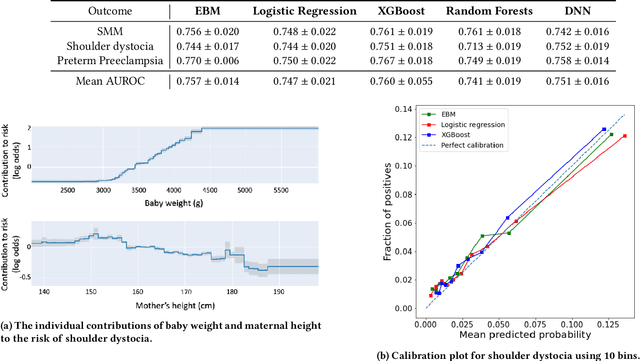

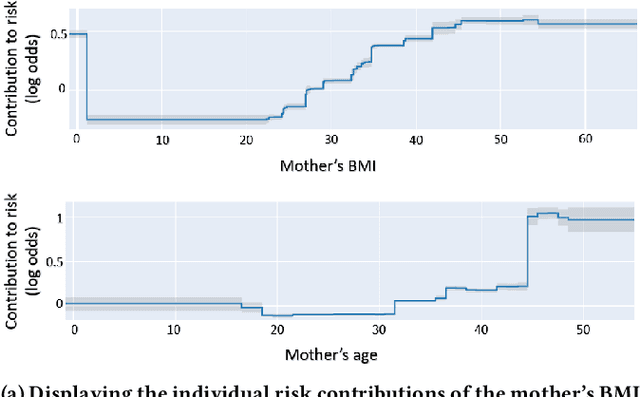
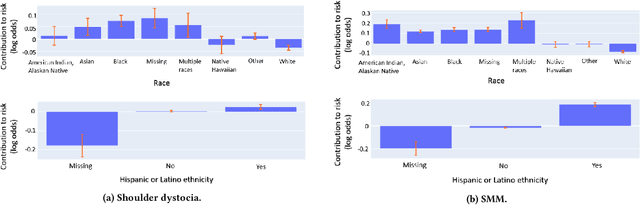
Most pregnancies and births result in a good outcome, but complications are not uncommon and when they do occur, they can be associated with serious implications for mothers and babies. Predictive modeling has the potential to improve outcomes through better understanding of risk factors, heightened surveillance, and more timely and appropriate interventions, thereby helping obstetricians deliver better care. For three types of complications we identify and study the most important risk factors using Explainable Boosting Machine (EBM), a glass box model, in order to gain intelligibility: (i) Severe Maternal Morbidity (SMM), (ii) shoulder dystocia, and (iii) preterm preeclampsia. While using the interpretability of EBM's to reveal surprising insights into the features contributing to risk, our experiments show EBMs match the accuracy of other black-box ML methods such as deep neural nets and random forests.