 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChronosX: Adapting Pretrained Time Series Models with Exogenous Variables
Mar 15, 2025



Covariates provide valuable information on external factors that influence time series and are critical in many real-world time series forecasting tasks. For example, in retail, covariates may indicate promotions or peak dates such as holiday seasons that heavily influence demand forecasts. Recent advances in pretraining large language model architectures for time series forecasting have led to highly accurate forecasters. However, the majority of these models do not readily use covariates as they are often specific to a certain task or domain. This paper introduces a new method to incorporate covariates into pretrained time series forecasting models. Our proposed approach incorporates covariate information into pretrained forecasting models through modular blocks that inject past and future covariate information, without necessarily modifying the pretrained model in consideration. In order to evaluate our approach, we introduce a benchmark composed of 32 different synthetic datasets with varying dynamics to evaluate the effectivity of forecasting models with covariates. Extensive evaluations on both synthetic and real datasets show that our approach effectively incorporates covariate information into pretrained models, outperforming existing baselines.
Chronos: Learning the Language of Time Series
Mar 12, 2024We introduce Chronos, a simple yet effective framework for pretrained probabilistic time series models. Chronos tokenizes time series values using scaling and quantization into a fixed vocabulary and trains existing transformer-based language model architectures on these tokenized time series via the cross-entropy loss. We pretrained Chronos models based on the T5 family (ranging from 20M to 710M parameters) on a large collection of publicly available datasets, complemented by a synthetic dataset that we generated via Gaussian processes to improve generalization. In a comprehensive benchmark consisting of 42 datasets, and comprising both classical local models and deep learning methods, we show that Chronos models: (a) significantly outperform other methods on datasets that were part of the training corpus; and (b) have comparable and occasionally superior zero-shot performance on new datasets, relative to methods that were trained specifically on them. Our results demonstrate that Chronos models can leverage time series data from diverse domains to improve zero-shot accuracy on unseen forecasting tasks, positioning pretrained models as a viable tool to greatly simplify forecasting pipelines.
Adaptive Sampling for Probabilistic Forecasting under Distribution Shift
Feb 23, 2023



The world is not static: This causes real-world time series to change over time through external, and potentially disruptive, events such as macroeconomic cycles or the COVID-19 pandemic. We present an adaptive sampling strategy that selects the part of the time series history that is relevant for forecasting. We achieve this by learning a discrete distribution over relevant time steps by Bayesian optimization. We instantiate this idea with a two-step method that is pre-trained with uniform sampling and then training a lightweight adaptive architecture with adaptive sampling. We show with synthetic and real-world experiments that this method adapts to distribution shift and significantly reduces the forecasting error of the base model for three out of five datasets.
Resilient Neural Forecasting Systems
Mar 16, 2022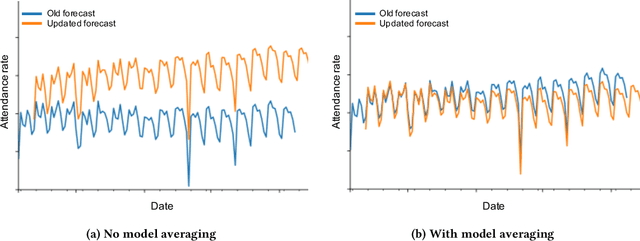
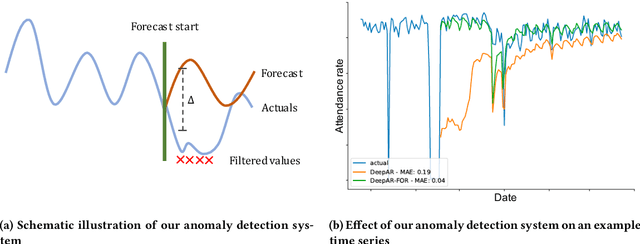
Industrial machine learning systems face data challenges that are often under-explored in the academic literature. Common data challenges are data distribution shifts, missing values and anomalies. In this paper, we discuss data challenges and solutions in the context of a Neural Forecasting application on labor planning.We discuss how to make this forecasting system resilient to these data challenges. We address changes in data distribution with a periodic retraining scheme and discuss the critical importance of model stability in this setting. Furthermore, we show how our deep learning model deals with missing values natively without requiring imputation. Finally, we describe how we detect anomalies in the input data and mitigate their effect before they impact the forecasts. This results in a fully autonomous forecasting system that compares favorably to a hybrid system consisting of the algorithm and human overrides.
Bootstrapping NLU Models with Multi-task Learning
Nov 15, 2019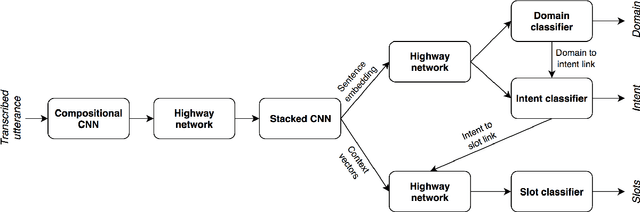

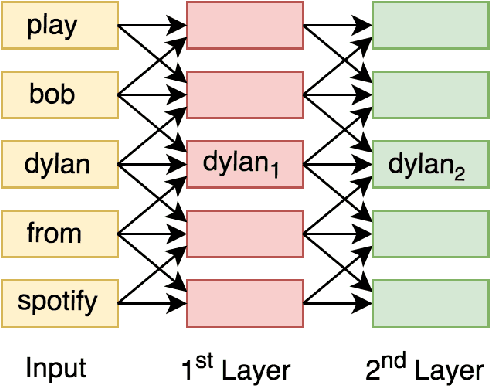
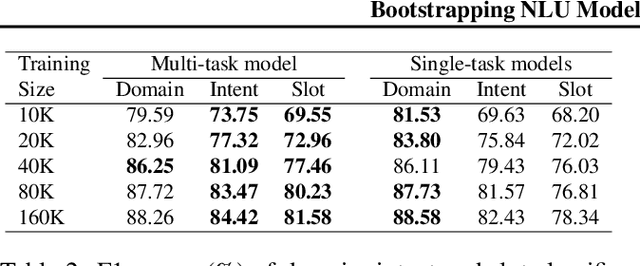
Bootstrapping natural language understanding (NLU) systems with minimal training data is a fundamental challenge of extending digital assistants like Alexa and Siri to a new language. A common approach that is adapted in digital assistants when responding to a user query is to process the input in a pipeline manner where the first task is to predict the domain, followed by the inference of intent and slots. However, this cascaded approach instigates error propagation and prevents information sharing among these tasks. Further, the use of words as the atomic units of meaning as done in many studies might lead to coverage problems for morphologically rich languages such as German and French when data is limited. We address these issues by introducing a character-level unified neural architecture for joint modeling of the domain, intent, and slot classification. We compose word-embeddings from characters and jointly optimize all classification tasks via multi-task learning. In our results, we show that the proposed architecture is an optimal choice for bootstrapping NLU systems in low-resource settings thus saving time, cost and human effort.