 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBootstrapping NLU Models with Multi-task Learning
Paper and Code
Nov 15, 2019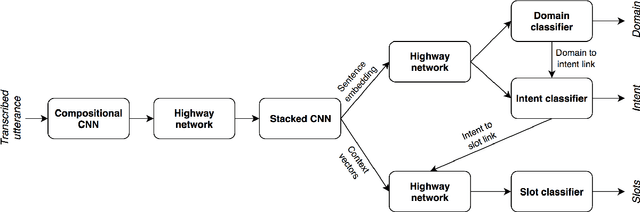

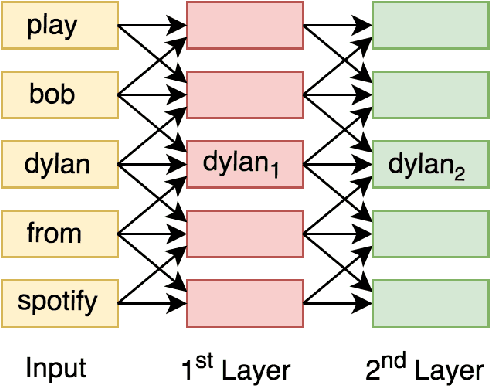
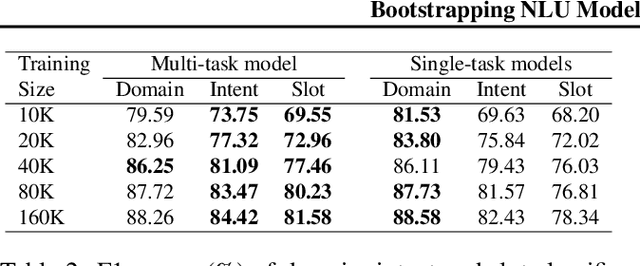
Bootstrapping natural language understanding (NLU) systems with minimal training data is a fundamental challenge of extending digital assistants like Alexa and Siri to a new language. A common approach that is adapted in digital assistants when responding to a user query is to process the input in a pipeline manner where the first task is to predict the domain, followed by the inference of intent and slots. However, this cascaded approach instigates error propagation and prevents information sharing among these tasks. Further, the use of words as the atomic units of meaning as done in many studies might lead to coverage problems for morphologically rich languages such as German and French when data is limited. We address these issues by introducing a character-level unified neural architecture for joint modeling of the domain, intent, and slot classification. We compose word-embeddings from characters and jointly optimize all classification tasks via multi-task learning. In our results, we show that the proposed architecture is an optimal choice for bootstrapping NLU systems in low-resource settings thus saving time, cost and human effort.