 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResilient Neural Forecasting Systems
Paper and Code
Mar 16, 2022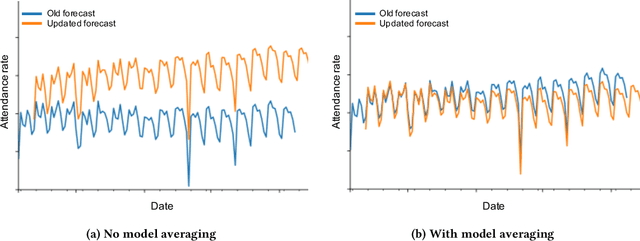
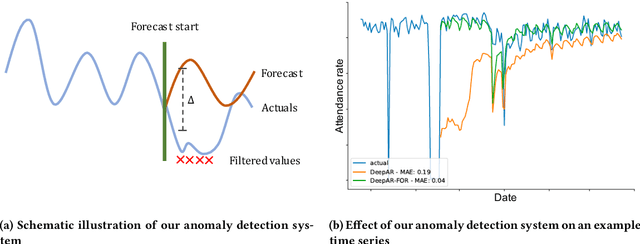
Industrial machine learning systems face data challenges that are often under-explored in the academic literature. Common data challenges are data distribution shifts, missing values and anomalies. In this paper, we discuss data challenges and solutions in the context of a Neural Forecasting application on labor planning.We discuss how to make this forecasting system resilient to these data challenges. We address changes in data distribution with a periodic retraining scheme and discuss the critical importance of model stability in this setting. Furthermore, we show how our deep learning model deals with missing values natively without requiring imputation. Finally, we describe how we detect anomalies in the input data and mitigate their effect before they impact the forecasts. This results in a fully autonomous forecasting system that compares favorably to a hybrid system consisting of the algorithm and human overrides.