 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Guided Iterative Refinement for Frontend Code Generation
Apr 07, 2026Code generation with large language models often relies on multi-stage human-in-the-loop refinement, which is effective but very costly - particularly in domains such as frontend web development where the solution quality depends on rendered visual output. We present a fully automated critic-in-the-loop framework in which a vision-language model serves as a visual critic that provides structured feedback on rendered webpages to guide iterative refinement of generated code. Across real-world user requests from the WebDev Arena dataset, this approach yields consistent improvements in solution quality, achieving up to 17.8% increase in performance over three refinement cycles. Next, we investigate parameter-efficient fine-tuning using LoRA to understand whether the improvements provided by the critic can be internalized by the code-generating LLM. Fine-tuning achieves 25% of the gains from the best critic-in-the-loop solution without a significant increase in token counts. Our findings indicate that automated, VLM-based critique of frontend code generation leads to significantly higher quality solutions than can be achieved through a single LLM inference pass, and highlight the importance of iterative refinement for the complex visual outputs associated with web development.
Aligning Black-box Language Models with Human Judgments
Feb 07, 2025Large language models (LLMs) are increasingly used as automated judges to evaluate recommendation systems, search engines, and other subjective tasks, where relying on human evaluators can be costly, time-consuming, and unscalable. LLMs offer an efficient solution for continuous, automated evaluation. However, since the systems that are built and improved with these judgments are ultimately designed for human use, it is crucial that LLM judgments align closely with human evaluators to ensure such systems remain human-centered. On the other hand, aligning LLM judgments with human evaluators is challenging due to individual variability and biases in human judgments. We propose a simple yet effective framework to align LLM judgments with individual human evaluators or their aggregated judgments, without retraining or fine-tuning the LLM. Our approach learns a linear mapping between the LLM's outputs and human judgments, achieving over 142% average improvement in agreement across 29 tasks with only a small number of calibration examples used for training. Notably, our method works in zero-shot and few-shot settings, exceeds inter-human agreement on four out of six tasks, and enables smaller LLMs to achieve performance comparable to that of larger models.
Efficient Pointwise-Pairwise Learning-to-Rank for News Recommendation
Sep 26, 2024



News recommendation is a challenging task that involves personalization based on the interaction history and preferences of each user. Recent works have leveraged the power of pretrained language models (PLMs) to directly rank news items by using inference approaches that predominately fall into three categories: pointwise, pairwise, and listwise learning-to-rank. While pointwise methods offer linear inference complexity, they fail to capture crucial comparative information between items that is more effective for ranking tasks. Conversely, pairwise and listwise approaches excel at incorporating these comparisons but suffer from practical limitations: pairwise approaches are either computationally expensive or lack theoretical guarantees, and listwise methods often perform poorly in practice. In this paper, we propose a novel framework for PLM-based news recommendation that integrates both pointwise relevance prediction and pairwise comparisons in a scalable manner. We present a rigorous theoretical analysis of our framework, establishing conditions under which our approach guarantees improved performance. Extensive experiments show that our approach outperforms the state-of-the-art methods on the MIND and Adressa news recommendation datasets.
On Memorization in Probabilistic Deep Generative Models
Jun 06, 2021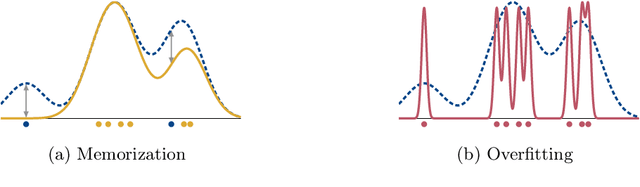



Recent advances in deep generative models have led to impressive results in a variety of application domains. Motivated by the possibility that deep learning models might memorize part of the input data, there have been increased efforts to understand how memorization can occur. In this work, we extend a recently proposed measure of memorization for supervised learning (Feldman, 2019) to the unsupervised density estimation problem and simplify the accompanying estimator. Next, we present an exploratory study that demonstrates how memorization can arise in probabilistic deep generative models, such as variational autoencoders. This reveals that the form of memorization to which these models are susceptible differs fundamentally from mode collapse and overfitting. Finally, we discuss several strategies that can be used to limit memorization in practice.
An Evaluation of Change Point Detection Algorithms
Mar 13, 2020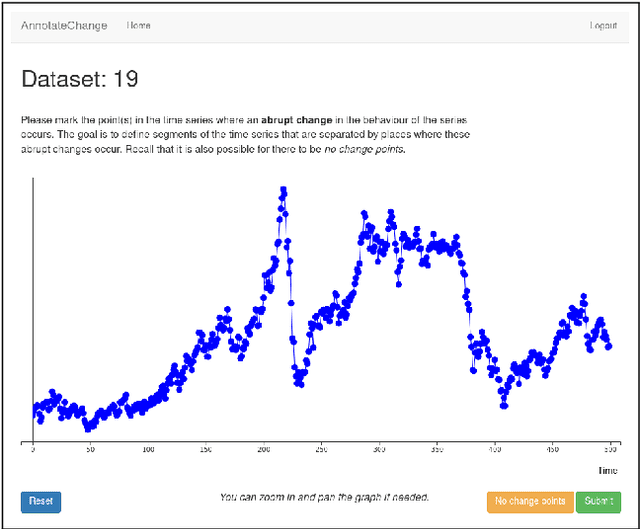

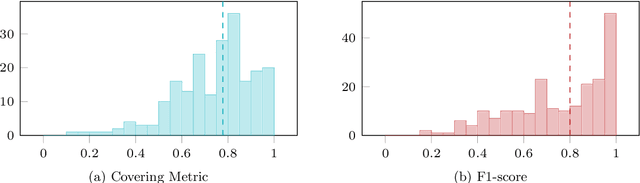
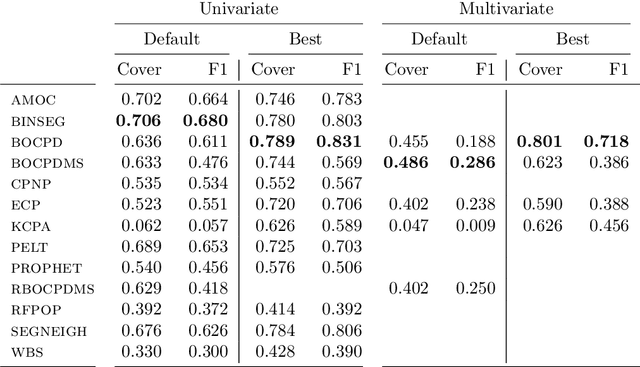
Change point detection is an important part of time series analysis, as the presence of a change point indicates an abrupt and significant change in the data generating process. While many algorithms for change point detection exist, little attention has been paid to evaluating their performance on real-world time series. Algorithms are typically evaluated on simulated data and a small number of commonly-used series with unreliable ground truth. Clearly this does not provide sufficient insight into the comparative performance of these algorithms. Therefore, instead of developing yet another change point detection method, we consider it vastly more important to properly evaluate existing algorithms on real-world data. To achieve this, we present the first data set specifically designed for the evaluation of change point detection algorithms, consisting of 37 time series from various domains. Each time series was annotated by five expert human annotators to provide ground truth on the presence and location of change points. We analyze the consistency of the human annotators, and describe evaluation metrics that can be used to measure algorithm performance in the presence of multiple ground truth annotations. Subsequently, we present a benchmark study where 13 existing algorithms are evaluated on each of the time series in the data set. This study shows that binary segmentation (Scott and Knott, 1974) and Bayesian online change point detection (Adams and MacKay, 2007) are among the best performing methods. Our aim is that this data set will serve as a proving ground in the development of novel change point detection algorithms.
Fast Meta-Learning for Adaptive Hierarchical Classifier Design
Nov 09, 2017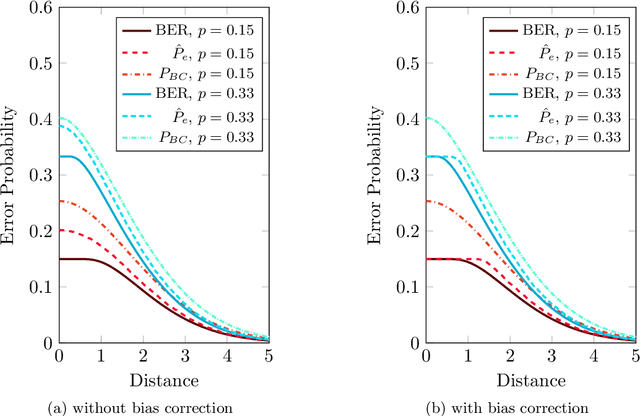
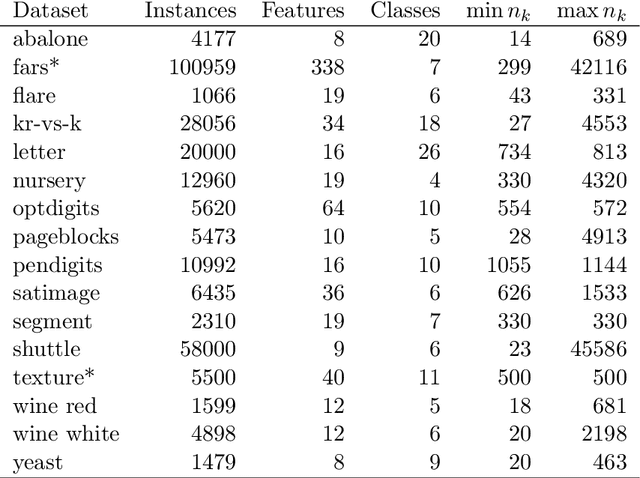
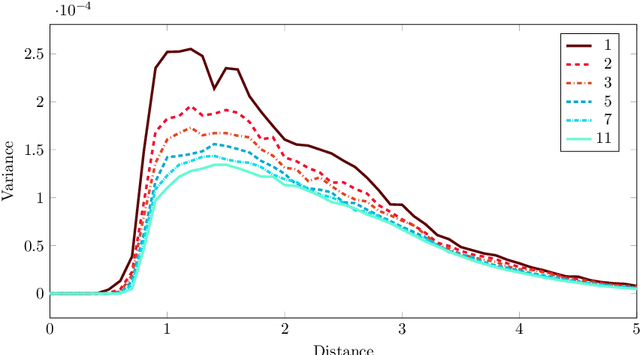
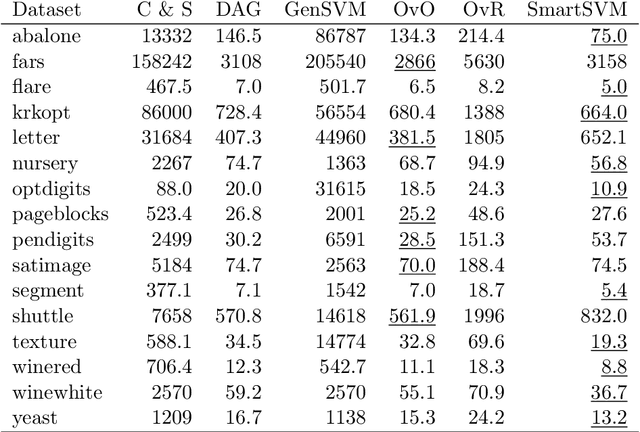
We propose a new splitting criterion for a meta-learning approach to multiclass classifier design that adaptively merges the classes into a tree-structured hierarchy of increasingly difficult binary classification problems. The classification tree is constructed from empirical estimates of the Henze-Penrose bounds on the pairwise Bayes misclassification rates that rank the binary subproblems in terms of difficulty of classification. The proposed empirical estimates of the Bayes error rate are computed from the minimal spanning tree (MST) of the samples from each pair of classes. Moreover, a meta-learning technique is presented for quantifying the one-vs-rest Bayes error rate for each individual class from a single MST on the entire dataset. Extensive simulations on benchmark datasets show that the proposed hierarchical method can often be learned much faster than competing methods, while achieving competitive accuracy.