 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Black-box Language Models with Human Judgments
Feb 07, 2025Large language models (LLMs) are increasingly used as automated judges to evaluate recommendation systems, search engines, and other subjective tasks, where relying on human evaluators can be costly, time-consuming, and unscalable. LLMs offer an efficient solution for continuous, automated evaluation. However, since the systems that are built and improved with these judgments are ultimately designed for human use, it is crucial that LLM judgments align closely with human evaluators to ensure such systems remain human-centered. On the other hand, aligning LLM judgments with human evaluators is challenging due to individual variability and biases in human judgments. We propose a simple yet effective framework to align LLM judgments with individual human evaluators or their aggregated judgments, without retraining or fine-tuning the LLM. Our approach learns a linear mapping between the LLM's outputs and human judgments, achieving over 142% average improvement in agreement across 29 tasks with only a small number of calibration examples used for training. Notably, our method works in zero-shot and few-shot settings, exceeds inter-human agreement on four out of six tasks, and enables smaller LLMs to achieve performance comparable to that of larger models.
Risk-aware Classification via Uncertainty Quantification
Dec 04, 2024



Autonomous and semi-autonomous systems are using deep learning models to improve decision-making. However, deep classifiers can be overly confident in their incorrect predictions, a major issue especially in safety-critical domains. The present study introduces three foundational desiderata for developing real-world risk-aware classification systems. Expanding upon the previously proposed Evidential Deep Learning (EDL), we demonstrate the unity between these principles and EDL's operational attributes. We then augment EDL empowering autonomous agents to exercise discretion during structured decision-making when uncertainty and risks are inherent. We rigorously examine empirical scenarios to substantiate these theoretical innovations. In contrast to existing risk-aware classifiers, our proposed methodologies consistently exhibit superior performance, underscoring their transformative potential in risk-conscious classification strategies.
Research Note on Uncertain Probabilities and Abstract Argumentation
Aug 23, 2022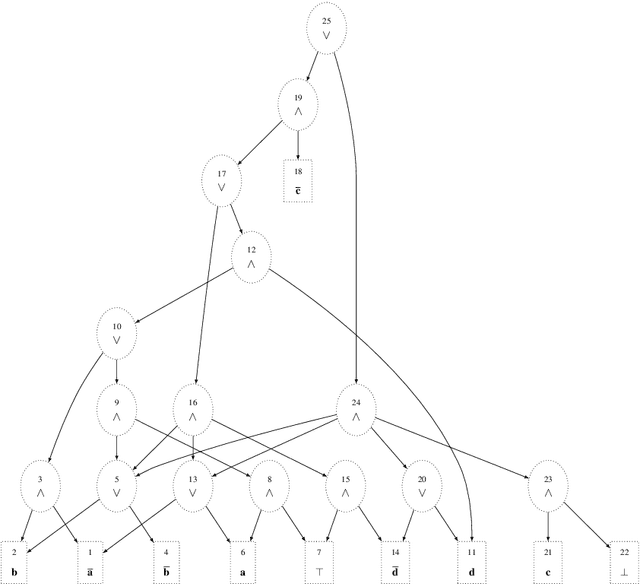
The sixth assessment of the international panel on climate change (IPCC) states that "cumulative net CO2 emissions over the last decade (2010-2019) are about the same size as the 11 remaining carbon budget likely to limit warming to 1.5C (medium confidence)." Such reports directly feed the public discourse, but nuances such as the degree of belief and of confidence are often lost. In this paper, we propose a formal account for allowing such degrees of belief and the associated confidence to be used to label arguments in abstract argumentation settings. Differently from other proposals in probabilistic argumentation, we focus on the task of probabilistic inference over a chosen query building upon Sato's distribution semantics which has been already shown to encompass a variety of cases including the semantics of Bayesian networks. Borrowing from the vast literature on such semantics, we examine how such tasks can be dealt with in practice when considering uncertain probabilities, and discuss the connections with existing proposals for probabilistic argumentation.
A Self-aware Personal Assistant for Making Personalized Privacy Decisions
May 18, 2022


Many software systems, such as online social networks enable users to share information about themselves. While the action of sharing is simple, it requires an elaborate thought process on privacy: what to share, with whom to share, and for what purposes. Thinking about these for each piece of content to be shared is tedious. Recent approaches to tackle this problem build personal assistants that can help users by learning what is private over time and recommending privacy labels such as private or public to individual content that a user considers sharing. However, privacy is inherently ambiguous and highly personal. Existing approaches to recommend privacy decisions do not address these aspects of privacy sufficiently. Ideally, a personal assistant should be able to adjust its recommendation based on a given user, considering that user's privacy understanding. Moreover, the personal assistant should be able to assess when its recommendation would be uncertain and let the user make the decision on her own. Accordingly, this paper proposes a personal assistant that uses evidential deep learning to classify content based on its privacy label. An important characteristic of the personal assistant is that it can model its uncertainty in its decisions explicitly, determine that it does not know the answer, and delegate from making a recommendation when its uncertainty is high. By factoring in the user's own understanding of privacy, such as risk factors or own labels, the personal assistant can personalize its recommendations per user. We evaluate our proposed personal assistant using a well-known data set. Our results show that our personal assistant can accurately identify uncertain cases, personalize them to its user's needs, and thus helps users preserve their privacy well.
Handling Epistemic and Aleatory Uncertainties in Probabilistic Circuits
Feb 22, 2021


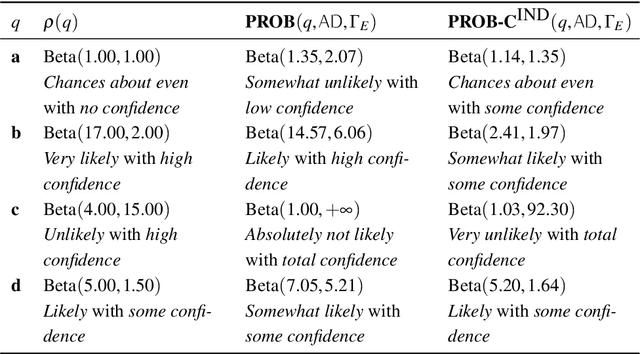
When collaborating with an AI system, we need to assess when to trust its recommendations. If we mistakenly trust it in regions where it is likely to err, catastrophic failures may occur, hence the need for Bayesian approaches for probabilistic reasoning in order to determine the confidence (or epistemic uncertainty) in the probabilities in light of the training data. We propose an approach to overcome the independence assumption behind most of the approaches dealing with a large class of probabilistic reasoning that includes Bayesian networks as well as several instances of probabilistic logic. We provide an algorithm for Bayesian learning from sparse, albeit complete, observations, and for deriving inferences and their confidences keeping track of the dependencies between variables when they are manipulated within the unifying computational formalism provided by probabilistic circuits. Each leaf of such circuits is labelled with a beta-distributed random variable that provides us with an elegant framework for representing uncertain probabilities. We achieve better estimation of epistemic uncertainty than state-of-the-art approaches, including highly engineered ones, while being able to handle general circuits and with just a modest increase in the computational effort compared to using point probabilities.
Process Discovery for Structured Program Synthesis
Aug 13, 2020


A core task in process mining is process discovery which aims to learn an accurate process model from event log data. In this paper, we propose to use (block-) structured programs directly as target process models so as to establish connections to the field of program synthesis and facilitate the translation from abstract process models to executable processes, e.g., for robotic process automation. Furthermore, we develop a novel bottom-up agglomerative approach to the discovery of such structured program process models. In comparison with the popular top-down recursive inductive miner, our proposed agglomerative miner enjoys the similar theoretical guarantee to produce sound process models (without deadlocks and other anomalies) while exhibiting some advantages like avoiding silent activities and accommodating duplicate activities. The proposed algorithm works by iteratively applying a few graph rewriting rules to the directly-follows-graph of activities. For real-world (sparse) directly-follows-graphs, the algorithm has quadratic computational complexity with respect to the number of distinct activities. To our knowledge, this is the first process discovery algorithm that is made for the purpose of program synthesis. Experiments on the BPI-Challenge 2020 dataset and the Karel programming dataset have demonstrated that our proposed algorithm can outperform the inductive miner not only according to the traditional process discovery metrics but also in terms of the effectiveness in finding out the true underlying structured program from a small number of its execution traces.
Uncertainty-Aware Deep Classifiers using Generative Models
Jun 07, 2020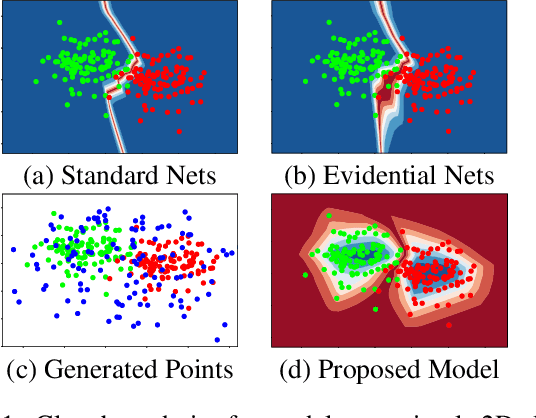


Deep neural networks are often ignorant about what they do not know and overconfident when they make uninformed predictions. Some recent approaches quantify classification uncertainty directly by training the model to output high uncertainty for the data samples close to class boundaries or from the outside of the training distribution. These approaches use an auxiliary data set during training to represent out-of-distribution samples. However, selection or creation of such an auxiliary data set is non-trivial, especially for high dimensional data such as images. In this work we develop a novel neural network model that is able to express both aleatoric and epistemic uncertainty to distinguish decision boundary and out-of-distribution regions of the feature space. To this end, variational autoencoders and generative adversarial networks are incorporated to automatically generate out-of-distribution exemplars for training. Through extensive analysis, we demonstrate that the proposed approach provides better estimates of uncertainty for in- and out-of-distribution samples, and adversarial examples on well-known data sets against state-of-the-art approaches including recent Bayesian approaches for neural networks and anomaly detection methods.
Evidential Deep Learning to Quantify Classification Uncertainty
Oct 31, 2018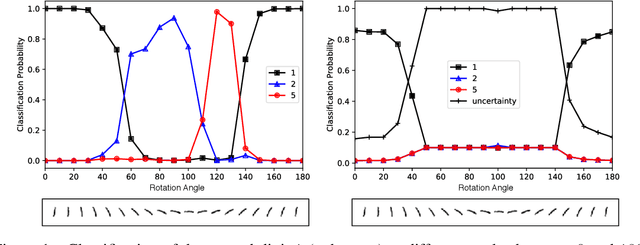
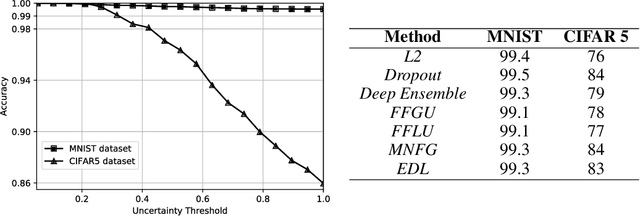
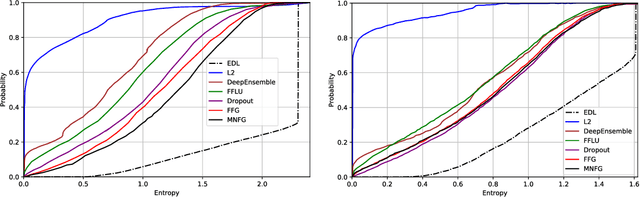
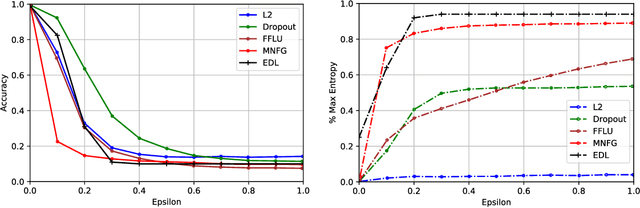
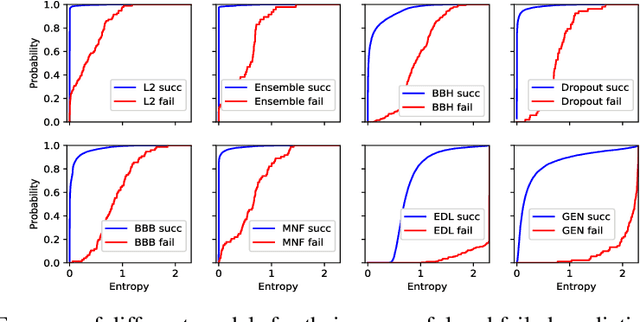
Deterministic neural nets have been shown to learn effective predictors on a wide range of machine learning problems. However, as the standard approach is to train the network to minimize a prediction loss, the resultant model remains ignorant to its prediction confidence. Orthogonally to Bayesian neural nets that indirectly infer prediction uncertainty through weight uncertainties, we propose explicit modeling of the same using the theory of subjective logic. By placing a Dirichlet distribution on the class probabilities, we treat predictions of a neural net as subjective opinions and learn the function that collects the evidence leading to these opinions by a deterministic neural net from data. The resultant predictor for a multi-class classification problem is another Dirichlet distribution whose parameters are set by the continuous output of a neural net. We provide a preliminary analysis on how the peculiarities of our new loss function drive improved uncertainty estimation. We observe that our method achieves unprecedented success on detection of out-of-distribution queries and endurance against adversarial perturbations.
Probabilistic Logic Programming with Beta-Distributed Random Variables
Oct 31, 2018


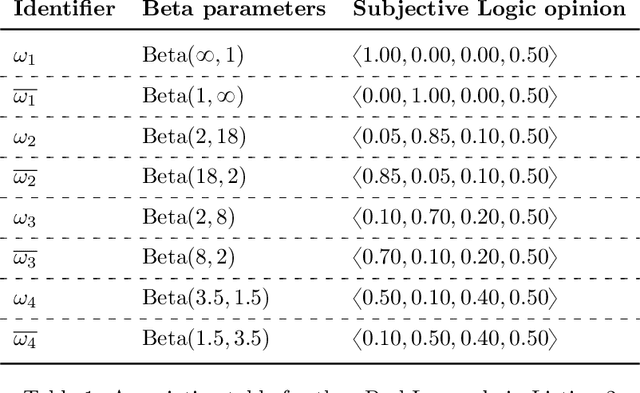
We enable aProbLog---a probabilistic logical programming approach---to reason in presence of uncertain probabilities represented as Beta-distributed random variables. We achieve the same performance of state-of-the-art algorithms for highly specified and engineered domains, while simultaneously we maintain the flexibility offered by aProbLog in handling complex relational domains. Our motivation is that faithfully capturing the distribution of probabilities is necessary to compute an expected utility for effective decision making under uncertainty: unfortunately, these probability distributions can be highly uncertain due to sparse data. To understand and accurately manipulate such probability distributions we need a well-defined theoretical framework that is provided by the Beta distribution, which specifies a distribution of probabilities representing all the possible values of a probability when the exact value is unknown.
Uncertainty Aware AI ML: Why and How
Sep 20, 2018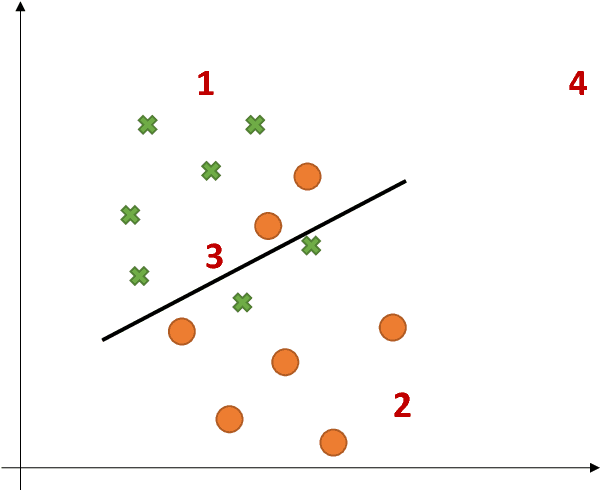
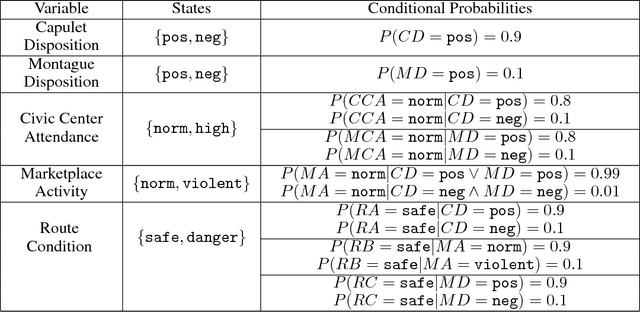
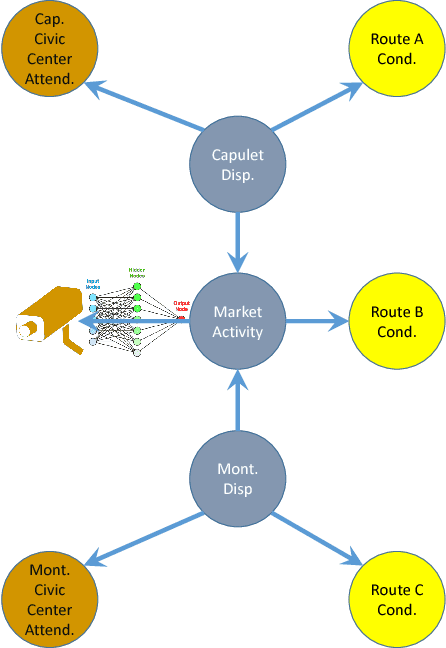
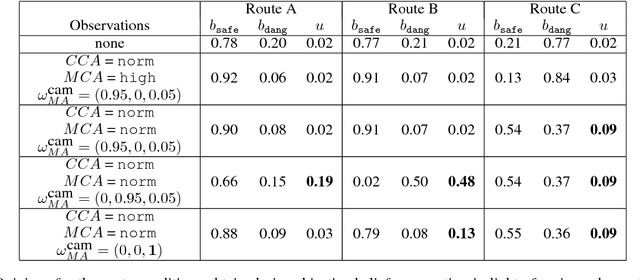
This paper argues the need for research to realize uncertainty-aware artificial intelligence and machine learning (AI\&ML) systems for decision support by describing a number of motivating scenarios. Furthermore, the paper defines uncertainty-awareness and lays out the challenges along with surveying some promising research directions. A theoretical demonstration illustrates how two emerging uncertainty-aware ML and AI technologies could be integrated and be of value for a route planning operation.