 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcess Discovery for Structured Program Synthesis
Aug 13, 2020

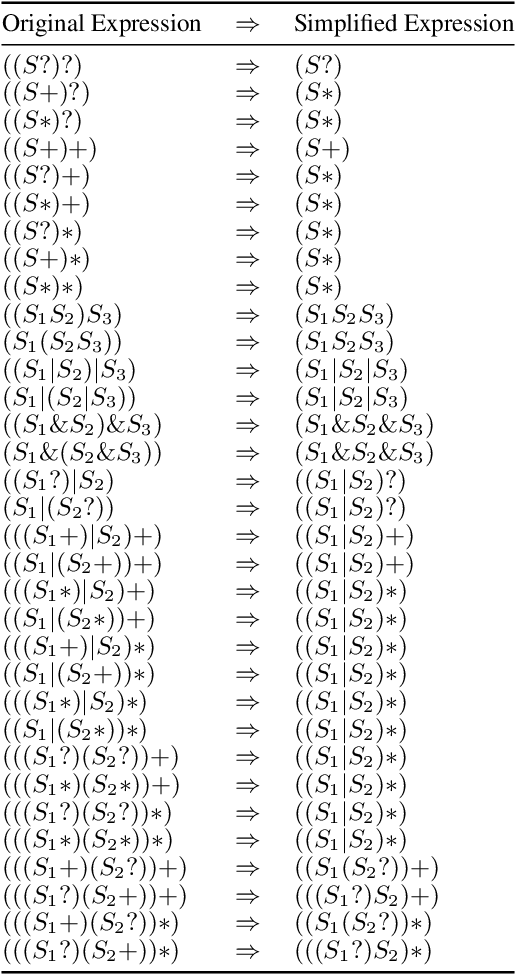

A core task in process mining is process discovery which aims to learn an accurate process model from event log data. In this paper, we propose to use (block-) structured programs directly as target process models so as to establish connections to the field of program synthesis and facilitate the translation from abstract process models to executable processes, e.g., for robotic process automation. Furthermore, we develop a novel bottom-up agglomerative approach to the discovery of such structured program process models. In comparison with the popular top-down recursive inductive miner, our proposed agglomerative miner enjoys the similar theoretical guarantee to produce sound process models (without deadlocks and other anomalies) while exhibiting some advantages like avoiding silent activities and accommodating duplicate activities. The proposed algorithm works by iteratively applying a few graph rewriting rules to the directly-follows-graph of activities. For real-world (sparse) directly-follows-graphs, the algorithm has quadratic computational complexity with respect to the number of distinct activities. To our knowledge, this is the first process discovery algorithm that is made for the purpose of program synthesis. Experiments on the BPI-Challenge 2020 dataset and the Karel programming dataset have demonstrated that our proposed algorithm can outperform the inductive miner not only according to the traditional process discovery metrics but also in terms of the effectiveness in finding out the true underlying structured program from a small number of its execution traces.
Semi-supervised Word Sense Disambiguation with Neural Models
Nov 05, 2016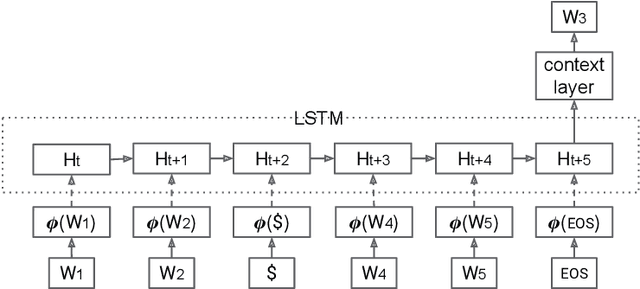
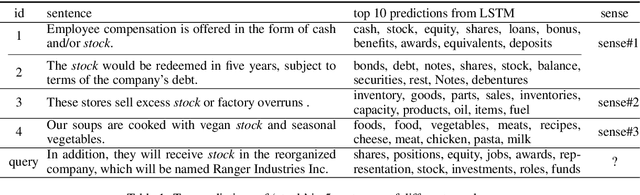
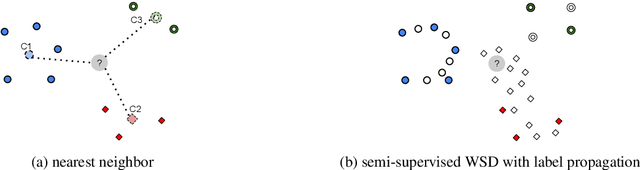
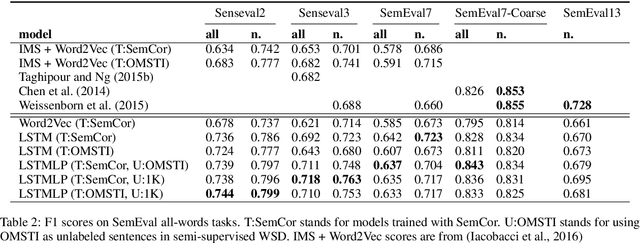
Determining the intended sense of words in text - word sense disambiguation (WSD) - is a long standing problem in natural language processing. Recently, researchers have shown promising results using word vectors extracted from a neural network language model as features in WSD algorithms. However, a simple average or concatenation of word vectors for each word in a text loses the sequential and syntactic information of the text. In this paper, we study WSD with a sequence learning neural net, LSTM, to better capture the sequential and syntactic patterns of the text. To alleviate the lack of training data in all-words WSD, we employ the same LSTM in a semi-supervised label propagation classifier. We demonstrate state-of-the-art results, especially on verbs.