 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative analysis of machine learning methods for active flow control
Feb 25, 2022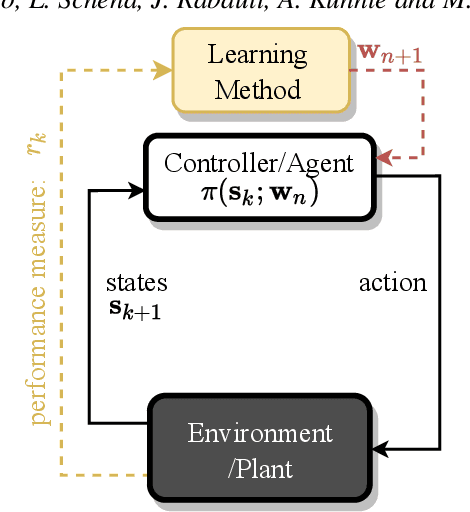

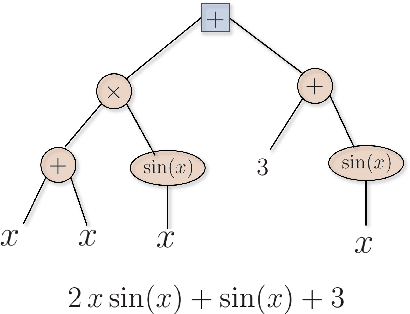
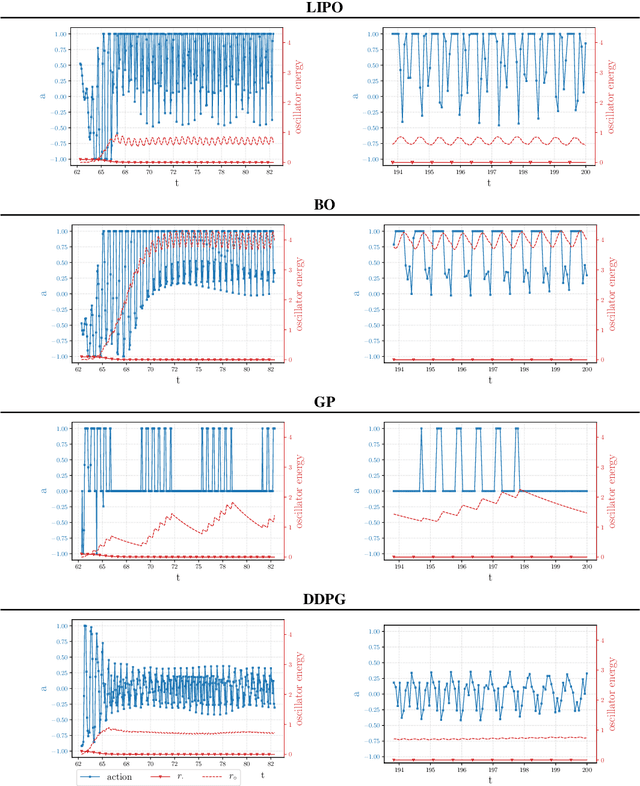
Machine learning frameworks such as Genetic Programming (GP) and Reinforcement Learning (RL) are gaining popularity in flow control. This work presents a comparative analysis of the two, bench-marking some of their most representative algorithms against global optimization techniques such as Bayesian Optimization (BO) and Lipschitz global optimization (LIPO). First, we review the general framework of the flow control problem, linking optimal control theory with model-free machine learning methods. Then, we test the control algorithms on three test cases. These are (1) the stabilization of a nonlinear dynamical system featuring frequency cross-talk, (2) the wave cancellation from a Burgers' flow and (3) the drag reduction in a cylinder wake flow. Although the control of these problems has been tackled in the recent literature with one method or the other, we present a comprehensive comparison to illustrate their differences in exploration versus exploitation and their balance between `model capacity' in the control law definition versus `required complexity'. We believe that such a comparison opens the path towards hybridization of the various methods, and we offer some perspective on their future development in the literature of flow control problems.
Policy Fusion for Adaptive and Customizable Reinforcement Learning Agents
Apr 21, 2021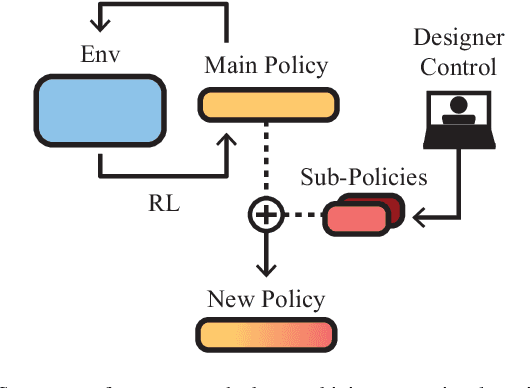
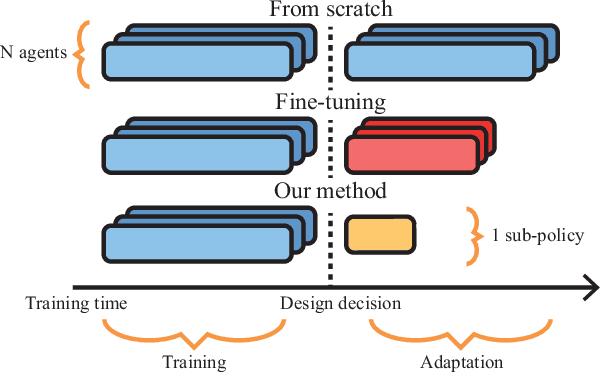

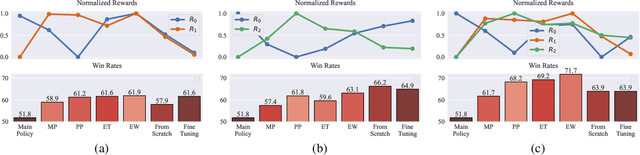
In this article we study the problem of training intelligent agents using Reinforcement Learning for the purpose of game development. Unlike systems built to replace human players and to achieve super-human performance, our agents aim to produce meaningful interactions with the player, and at the same time demonstrate behavioral traits as desired by game designers. We show how to combine distinct behavioral policies to obtain a meaningful "fusion" policy which comprises all these behaviors. To this end, we propose four different policy fusion methods for combining pre-trained policies. We further demonstrate how these methods can be used in combination with Inverse Reinforcement Learning in order to create intelligent agents with specific behavioral styles as chosen by game designers, without having to define many and possibly poorly-designed reward functions. Experiments on two different environments indicate that entropy-weighted policy fusion significantly outperforms all others. We provide several practical examples and use-cases for how these methods are indeed useful for video game production and designers.
Deep Policy Networks for NPC Behaviors that Adapt to Changing Design Parameters in Roguelike Games
Dec 07, 2020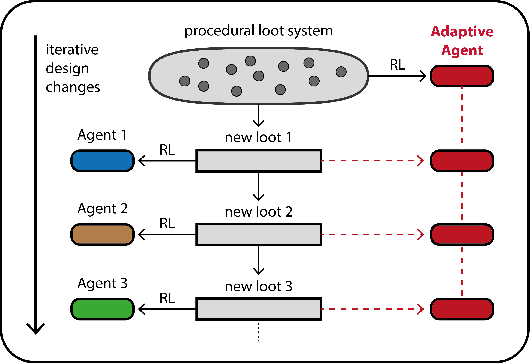


Recent advances in Deep Reinforcement Learning (DRL) have largely focused on improving the performance of agents with the aim of replacing humans in known and well-defined environments. The use of these techniques as a game design tool for video game production, where the aim is instead to create Non-Player Character (NPC) behaviors, has received relatively little attention until recently. Turn-based strategy games like Roguelikes, for example, present unique challenges to DRL. In particular, the categorical nature of their complex game state, composed of many entities with different attributes, requires agents able to learn how to compare and prioritize these entities. Moreover, this complexity often leads to agents that overfit to states seen during training and that are unable to generalize in the face of design changes made during development. In this paper we propose two network architectures which, when combined with a \emph{procedural loot generation} system, are able to better handle complex categorical state spaces and to mitigate the need for retraining forced by design decisions. The first is based on a dense embedding of the categorical input space that abstracts the discrete observation model and renders trained agents more able to generalize. The second proposed architecture is more general and is based on a Transformer network able to reason relationally about input and input attributes. Our experimental evaluation demonstrates that new agents have better adaptation capacity with respect to a baseline architecture, making this framework more robust to dynamic gameplay changes during development. Based on the results shown in this paper, we believe that these solutions represent a step forward towards making DRL more accessible to the gaming industry.
Demonstration-efficient Inverse Reinforcement Learning in Procedurally Generated Environments
Dec 04, 2020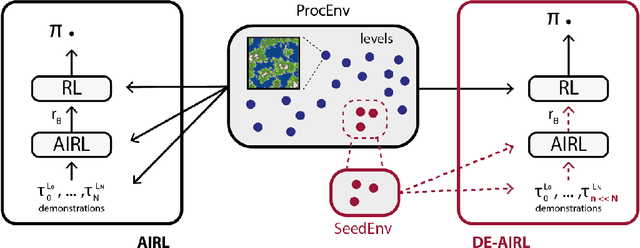
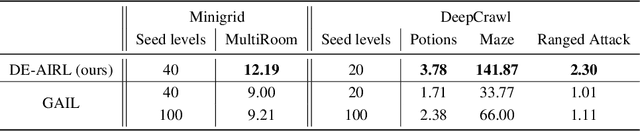


Deep Reinforcement Learning achieves very good results in domains where reward functions can be manually engineered. At the same time, there is growing interest within the community in using games based on Procedurally Content Generation (PCG) as benchmark environments since this type of environment is perfect for studying overfitting and generalization of agents under domain shift. Inverse Reinforcement Learning (IRL) can instead extrapolate reward functions from expert demonstrations, with good results even on high-dimensional problems, however there are no examples of applying these techniques to procedurally-generated environments. This is mostly due to the number of demonstrations needed to find a good reward model. We propose a technique based on Adversarial Inverse Reinforcement Learning which can significantly decrease the need for expert demonstrations in PCG games. Through the use of an environment with a limited set of initial seed levels, plus some modifications to stabilize training, we show that our approach, DE-AIRL, is demonstration-efficient and still able to extrapolate reward functions which generalize to the fully procedural domain. We demonstrate the effectiveness of our technique on two procedural environments, MiniGrid and DeepCrawl, for a variety of tasks.
DeepCrawl: Deep Reinforcement Learning for Turn-based Strategy Games
Dec 03, 2020



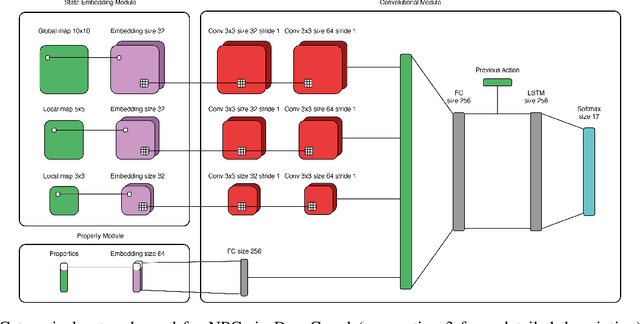
In this paper we introduce DeepCrawl, a fully-playable Roguelike prototype for iOS and Android in which all agents are controlled by policy networks trained using Deep Reinforcement Learning (DRL). Our aim is to understand whether recent advances in DRL can be used to develop convincing behavioral models for non-player characters in videogames. We begin with an analysis of requirements that such an AI system should satisfy in order to be practically applicable in video game development, and identify the elements of the DRL model used in the DeepCrawl prototype. The successes and limitations of DeepCrawl are documented through a series of playability tests performed on the final game. We believe that the techniques we propose offer insight into innovative new avenues for the development of behaviors for non-player characters in video games, as they offer the potential to overcome critical issues with
Process Discovery for Structured Program Synthesis
Aug 13, 2020

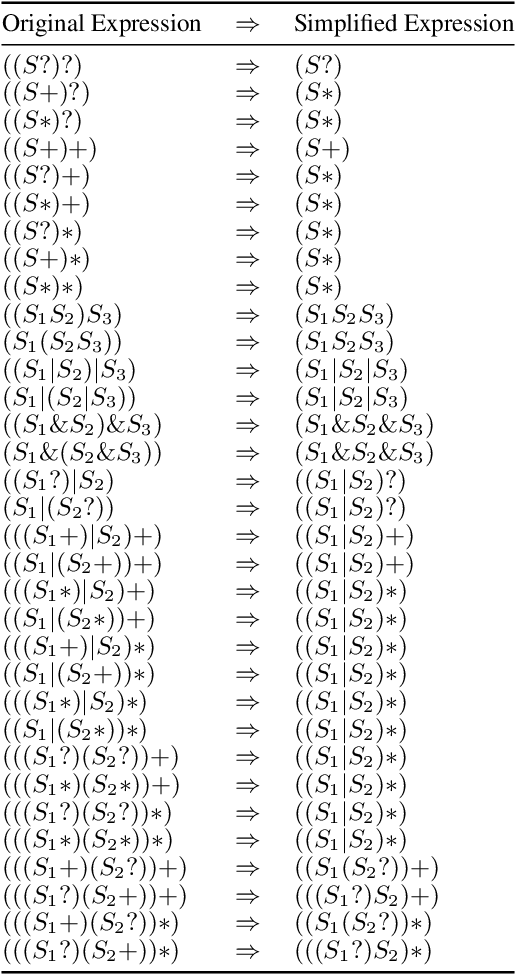

A core task in process mining is process discovery which aims to learn an accurate process model from event log data. In this paper, we propose to use (block-) structured programs directly as target process models so as to establish connections to the field of program synthesis and facilitate the translation from abstract process models to executable processes, e.g., for robotic process automation. Furthermore, we develop a novel bottom-up agglomerative approach to the discovery of such structured program process models. In comparison with the popular top-down recursive inductive miner, our proposed agglomerative miner enjoys the similar theoretical guarantee to produce sound process models (without deadlocks and other anomalies) while exhibiting some advantages like avoiding silent activities and accommodating duplicate activities. The proposed algorithm works by iteratively applying a few graph rewriting rules to the directly-follows-graph of activities. For real-world (sparse) directly-follows-graphs, the algorithm has quadratic computational complexity with respect to the number of distinct activities. To our knowledge, this is the first process discovery algorithm that is made for the purpose of program synthesis. Experiments on the BPI-Challenge 2020 dataset and the Karel programming dataset have demonstrated that our proposed algorithm can outperform the inductive miner not only according to the traditional process discovery metrics but also in terms of the effectiveness in finding out the true underlying structured program from a small number of its execution traces.
Going Beneath the Surface: Evaluating Image Captioning for Grammaticality, Truthfulness and Diversity
Dec 19, 2019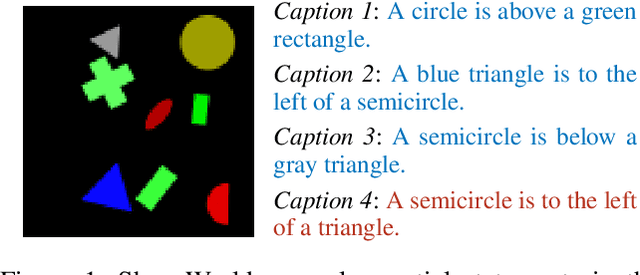
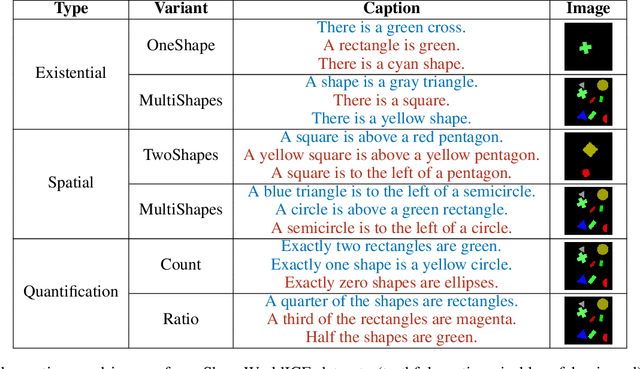
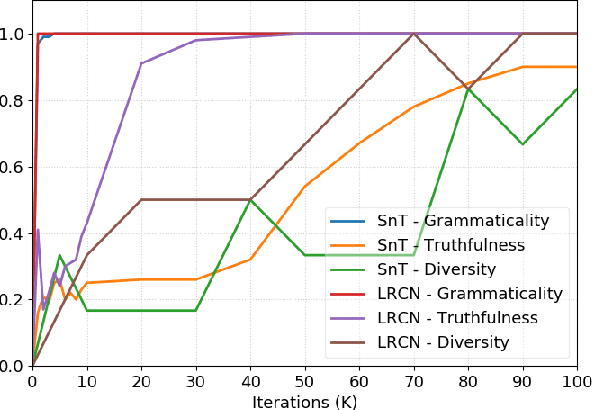
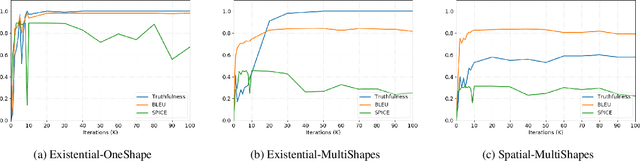
Image captioning as a multimodal task has drawn much interest in recent years. However, evaluation for this task remains a challenging problem. Existing evaluation metrics focus on surface similarity between a candidate caption and a set of reference captions, and do not check the actual relation between a caption and the underlying visual content. We introduce a new diagnostic evaluation framework for the task of image captioning, with the goal of directly assessing models for grammaticality, truthfulness and diversity (GTD) of generated captions. We demonstrate the potential of our evaluation framework by evaluating existing image captioning models on a wide ranging set of synthetic datasets that we construct for diagnostic evaluation. We empirically show how the GTD evaluation framework, in combination with diagnostic datasets, can provide insights into model capabilities and limitations to supplement standard evaluations.
What is needed for simple spatial language capabilities in VQA?
Aug 17, 2019
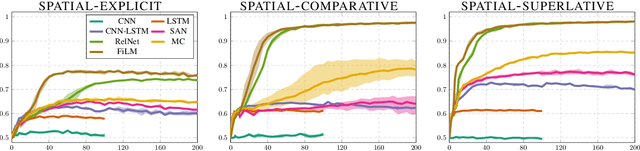
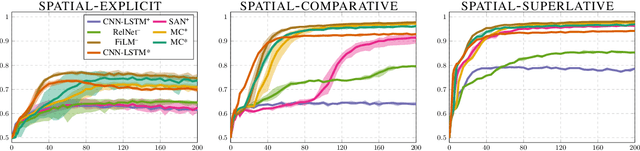
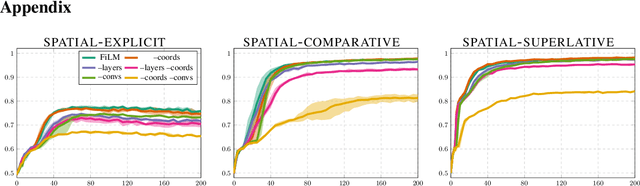
Visual question answering (VQA) comprises a variety of language capabilities. The diagnostic benchmark dataset CLEVR has fueled progress by helping to better assess and distinguish models in basic abilities like counting, comparing and spatial reasoning in vitro. Following this approach, we focus on spatial language capabilities and investigate the question: what are the key ingredients to handle simple visual-spatial relations? We look at the SAN, RelNet, FiLM and MC models and evaluate their learning behavior on diagnostic data which is solely focused on spatial relations. Via comparative analysis and targeted model modification we identify what really is required to substantially improve upon the CNN-LSTM baseline.
A review on Deep Reinforcement Learning for Fluid Mechanics
Aug 12, 2019


Deep reinforcement learning (DRL) has recently been adopted in a wide range of physics and engineering domains for its ability to solve decision-making problems that were previously out of reach due to a combination of non-linearity and high dimensionality. In the last few years, it has spread in the field of computational mechanics, and particularly in fluid dynamics, with recent applications in flow control and shape optimization. In this work, we conduct a detailed review of existing DRL applications to fluid mechanics problems. In addition, we present recent results that further illustrate the potential of DRL in Fluid Mechanics. The coupling methods used in each case are covered, detailing their advantages and limitations. Our review also focuses on the comparison with classical methods for optimal control and optimization. Finally, several test cases are described that illustrate recent progress made in this field. The goal of this publication is to provide an understanding of DRL capabilities along with state-of-the-art applications in fluid dynamics to researchers wishing to address new problems with these methods.
The meaning of "most" for visual question answering models
Dec 31, 2018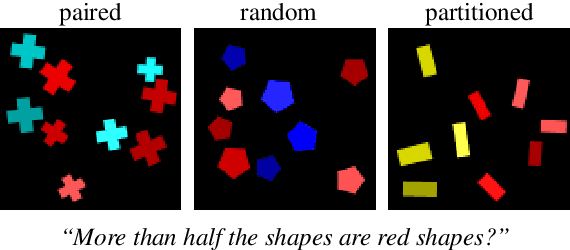


The correct interpretation of quantifier statements in the context of a visual scene requires non-trivial inference mechanisms. For the example of "most", we discuss two strategies which rely on fundamentally different cognitive concepts. Our aim is to identify what strategy deep learning models for visual question answering learn when trained on such questions. To this end, we carefully design data to replicate experiments from psycholinguistics where the same question was investigated for humans. Focusing on the FiLM visual question answering model, our experiments indicate that a form of approximate number system emerges whose performance declines with more difficult scenes as predicted by Weber's law. Moreover, we identify confounding factors, like spatial arrangement of the scene, which impede the effectiveness of this system.