Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat is needed for simple spatial language capabilities in VQA?
Paper and Code

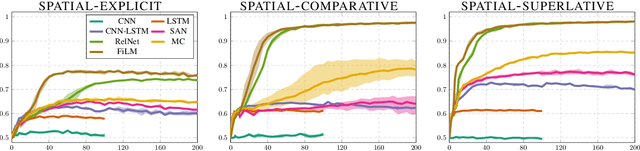
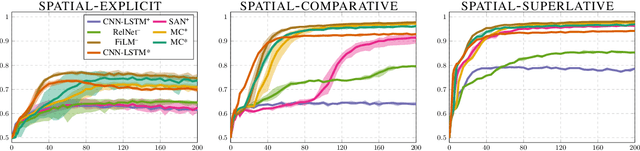
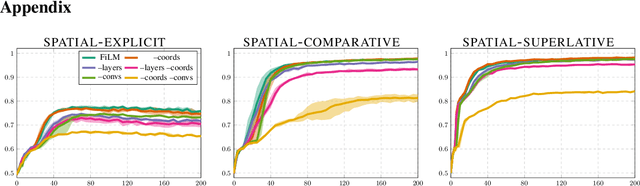
Visual question answering (VQA) comprises a variety of language capabilities. The diagnostic benchmark dataset CLEVR has fueled progress by helping to better assess and distinguish models in basic abilities like counting, comparing and spatial reasoning in vitro. Following this approach, we focus on spatial language capabilities and investigate the question: what are the key ingredients to handle simple visual-spatial relations? We look at the SAN, RelNet, FiLM and MC models and evaluate their learning behavior on diagnostic data which is solely focused on spatial relations. Via comparative analysis and targeted model modification we identify what really is required to substantially improve upon the CNN-LSTM baseline.
View paper on