 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Semi-supervised Word Sense Disambiguation with Neural Models
Nov 05, 2016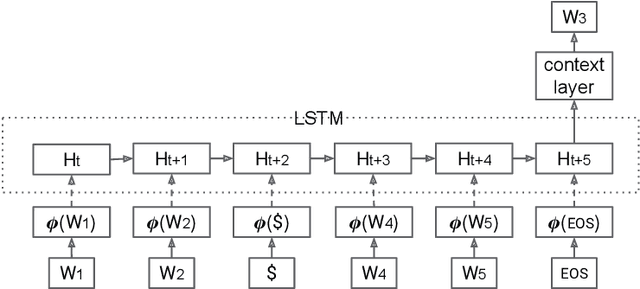
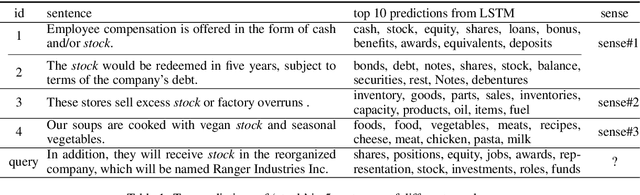
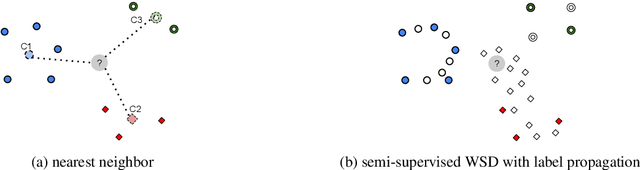
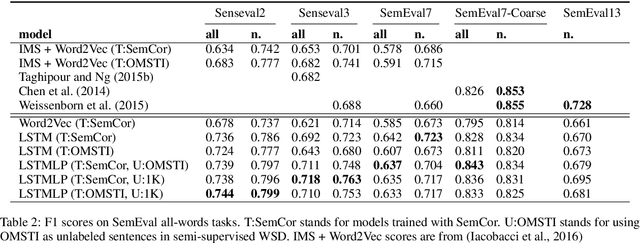
Determining the intended sense of words in text - word sense disambiguation (WSD) - is a long standing problem in natural language processing. Recently, researchers have shown promising results using word vectors extracted from a neural network language model as features in WSD algorithms. However, a simple average or concatenation of word vectors for each word in a text loses the sequential and syntactic information of the text. In this paper, we study WSD with a sequence learning neural net, LSTM, to better capture the sequential and syntactic patterns of the text. To alleviate the lack of training data in all-words WSD, we employ the same LSTM in a semi-supervised label propagation classifier. We demonstrate state-of-the-art results, especially on verbs.
Swivel: Improving Embeddings by Noticing What's Missing
Feb 06, 2016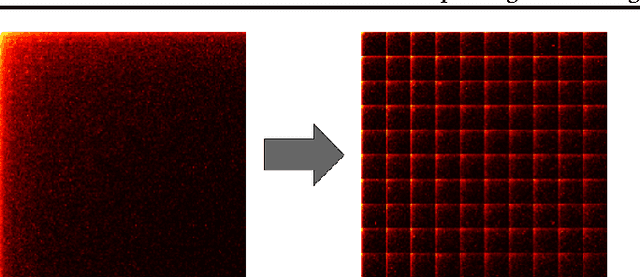



We present Submatrix-wise Vector Embedding Learner (Swivel), a method for generating low-dimensional feature embeddings from a feature co-occurrence matrix. Swivel performs approximate factorization of the point-wise mutual information matrix via stochastic gradient descent. It uses a piecewise loss with special handling for unobserved co-occurrences, and thus makes use of all the information in the matrix. While this requires computation proportional to the size of the entire matrix, we make use of vectorized multiplication to process thousands of rows and columns at once to compute millions of predicted values. Furthermore, we partition the matrix into shards in order to parallelize the computation across many nodes. This approach results in more accurate embeddings than can be achieved with methods that consider only observed co-occurrences, and can scale to much larger corpora than can be handled with sampling methods.