 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapturing Polysemanticity with PRISM: A Multi-Concept Feature Description Framework
Jun 18, 2025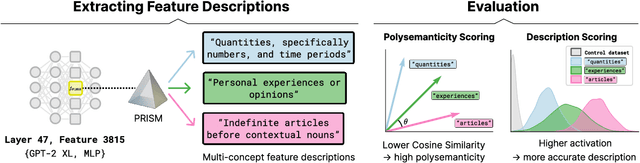

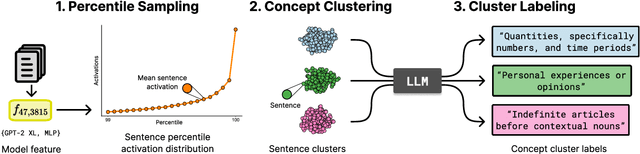

Automated interpretability research aims to identify concepts encoded in neural network features to enhance human understanding of model behavior. Current feature description methods face two critical challenges: limited robustness and the flawed assumption that each neuron encodes only a single concept (monosemanticity), despite growing evidence that neurons are often polysemantic. This assumption restricts the expressiveness of feature descriptions and limits their ability to capture the full range of behaviors encoded in model internals. To address this, we introduce Polysemantic FeatuRe Identification and Scoring Method (PRISM), a novel framework that captures the inherent complexity of neural network features. Unlike prior approaches that assign a single description per feature, PRISM provides more nuanced descriptions for both polysemantic and monosemantic features. We apply PRISM to language models and, through extensive benchmarking against existing methods, demonstrate that our approach produces more accurate and faithful feature descriptions, improving both overall description quality (via a description score) and the ability to capture distinct concepts when polysemanticity is present (via a polysemanticity score).
CoSy: Evaluating Textual Explanations of Neurons
May 30, 2024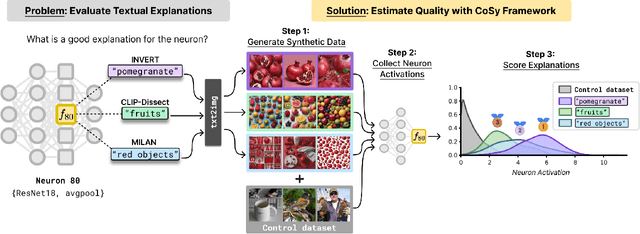


A crucial aspect of understanding the complex nature of Deep Neural Networks (DNNs) is the ability to explain learned concepts within their latent representations. While various methods exist to connect neurons to textual descriptions of human-understandable concepts, evaluating the quality of these explanation methods presents a major challenge in the field due to a lack of unified, general-purpose quantitative evaluation. In this work, we introduce CoSy (Concept Synthesis) -- a novel, architecture-agnostic framework to evaluate the quality of textual explanations for latent neurons. Given textual explanations, our proposed framework leverages a generative model conditioned on textual input to create data points representing the textual explanation. Then, the neuron's response to these explanation data points is compared with the response to control data points, providing a quality estimate of the given explanation. We ensure the reliability of our proposed framework in a series of meta-evaluation experiments and demonstrate practical value through insights from benchmarking various concept-based textual explanation methods for Computer Vision tasks, showing that tested explanation methods significantly differ in quality.
Identifying nonlinear dynamical systems from multi-modal time series data
Nov 04, 2021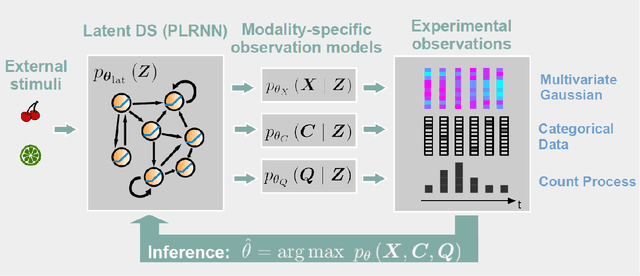
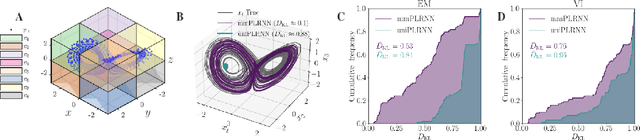
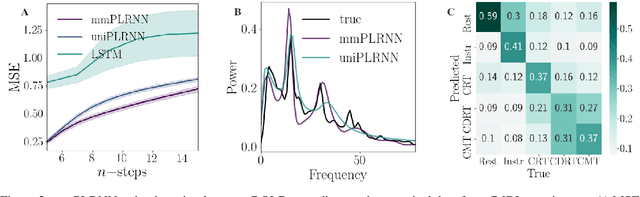
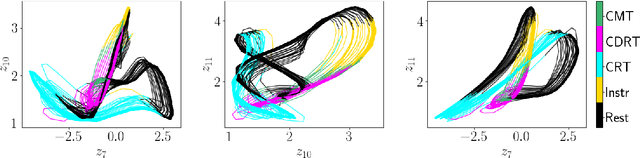
Empirically observed time series in physics, biology, or medicine, are commonly generated by some underlying dynamical system (DS) which is the target of scientific interest. There is an increasing interest to harvest machine learning methods to reconstruct this latent DS in a completely data-driven, unsupervised way. In many areas of science it is common to sample time series observations from many data modalities simultaneously, e.g. electrophysiological and behavioral time series in a typical neuroscience experiment. However, current machine learning tools for reconstructing DSs usually focus on just one data modality. Here we propose a general framework for multi-modal data integration for the purpose of nonlinear DS identification and cross-modal prediction. This framework is based on dynamically interpretable recurrent neural networks as general approximators of nonlinear DSs, coupled to sets of modality-specific decoder models from the class of generalized linear models. Both an expectation-maximization and a variational inference algorithm for model training are advanced and compared. We show on nonlinear DS benchmarks that our algorithms can efficiently compensate for too noisy or missing information in one data channel by exploiting other channels, and demonstrate on experimental neuroscience data how the algorithm learns to link different data domains to the underlying dynamics