 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Specific Word Embeddings with Structure Prediction
Oct 06, 2022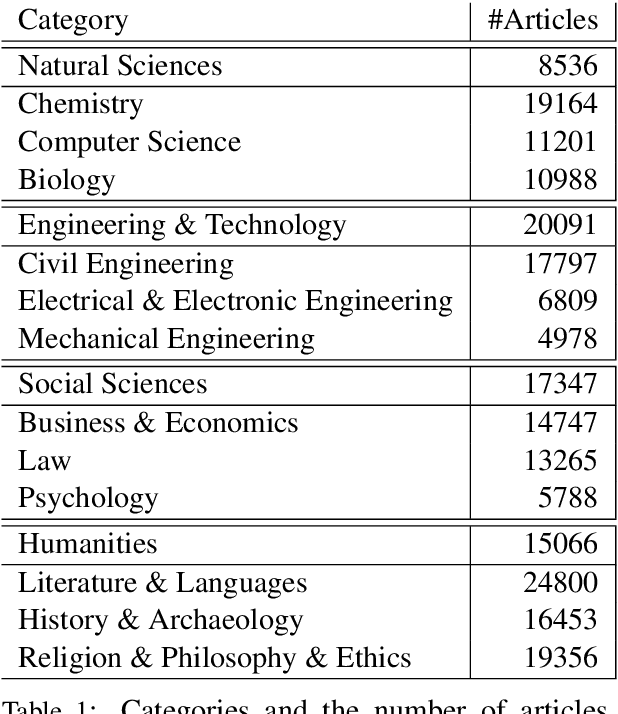
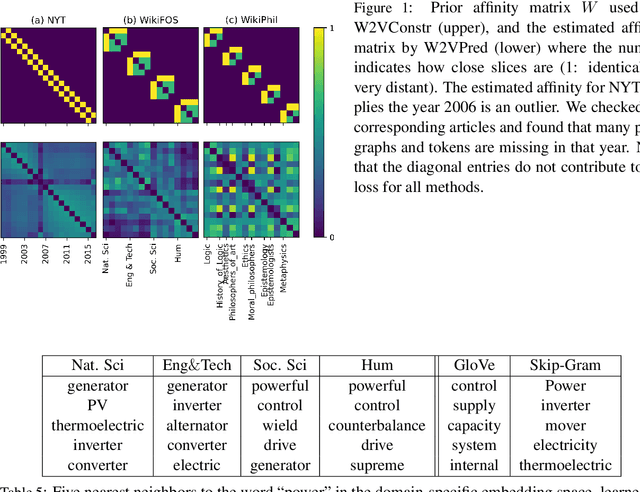
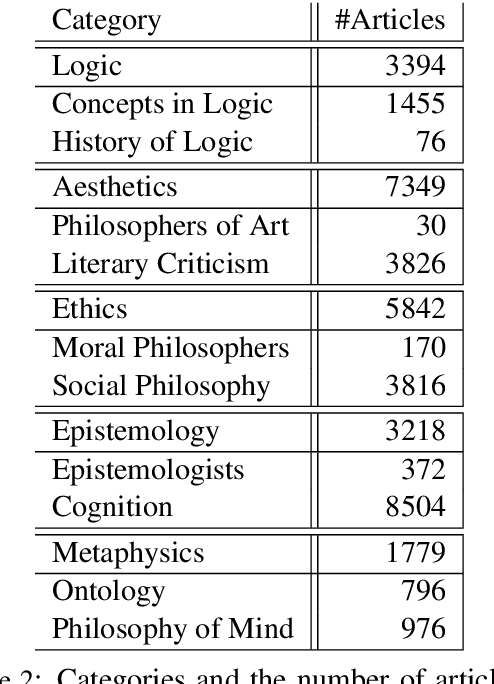
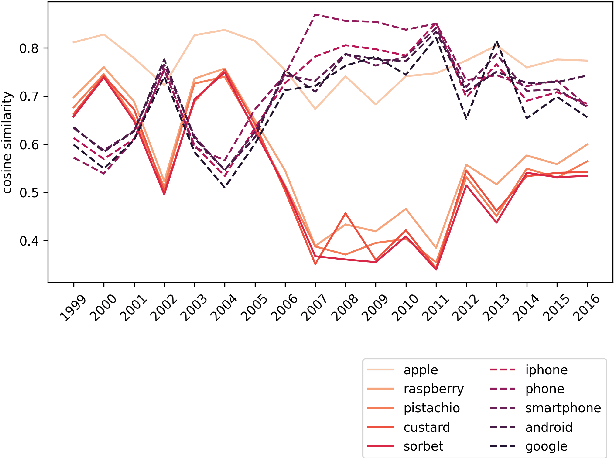
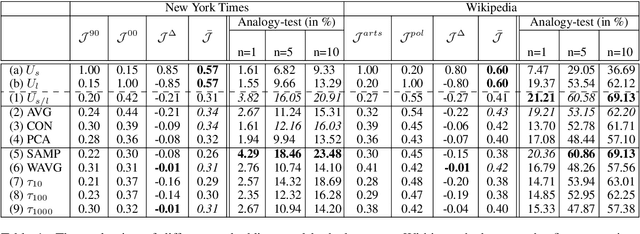
Complementary to finding good general word embeddings, an important question for representation learning is to find dynamic word embeddings, e.g., across time or domain. Current methods do not offer a way to use or predict information on structure between sub-corpora, time or domain and dynamic embeddings can only be compared after post-alignment. We propose novel word embedding methods that provide general word representations for the whole corpus, domain-specific representations for each sub-corpus, sub-corpus structure, and embedding alignment simultaneously. We present an empirical evaluation on New York Times articles and two English Wikipedia datasets with articles on science and philosophy. Our method, called Word2Vec with Structure Prediction (W2VPred), provides better performance than baselines in terms of the general analogy tests, domain-specific analogy tests, and multiple specific word embedding evaluations as well as structure prediction performance when no structure is given a priori. As a use case in the field of Digital Humanities we demonstrate how to raise novel research questions for high literature from the German Text Archive.
Automatic Identification of Types of Alterations in Historical Manuscripts
Mar 23, 2020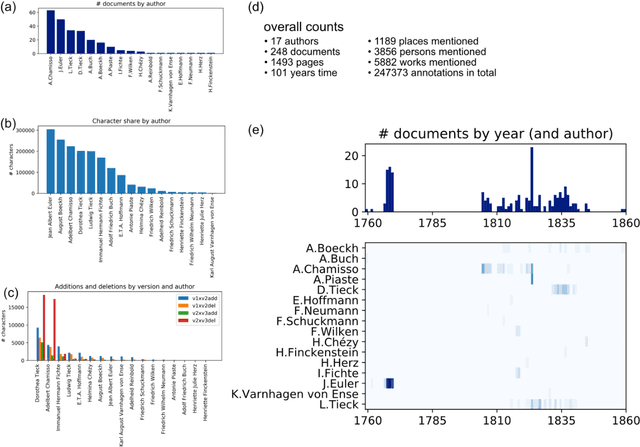
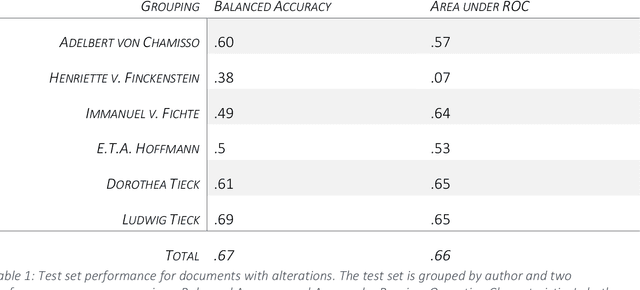


Alterations in historical manuscripts such as letters represent a promising field of research. On the one hand, they help understand the construction of text. On the other hand, topics that are being considered sensitive at the time of the manuscript gain coherence and contextuality when taking alterations into account, especially in the case of deletions. The analysis of alterations in manuscripts, though, is a traditionally very tedious work. In this paper, we present a machine learning-based approach to help categorize alterations in documents. In particular, we present a new probabilistic model (Alteration Latent Dirichlet Allocation, alterLDA in the following) that categorizes content-related alterations. The method proposed here is developed based on experiments carried out on the digital scholarly edition Berlin Intellectuals, for which alterLDA achieves high performance in the recognition of alterations on labelled data. On unlabelled data, applying alterLDA leads to interesting new insights into the alteration behavior of authors, editors and other manuscript contributors, as well as insights into sensitive topics in the correspondence of Berlin intellectuals around 1800. In addition to the findings based on the digital scholarly edition Berlin Intellectuals, we present a general framework for the analysis of text genesis that can be used in the context of other digital resources representing document variants. To that end, we present in detail the methodological steps that are to be followed in order to achieve such results, giving thereby a prime example of an Machine Learning application the Digital Humanities.
Balancing the composition of word embeddings across heterogenous data sets
Jan 14, 2020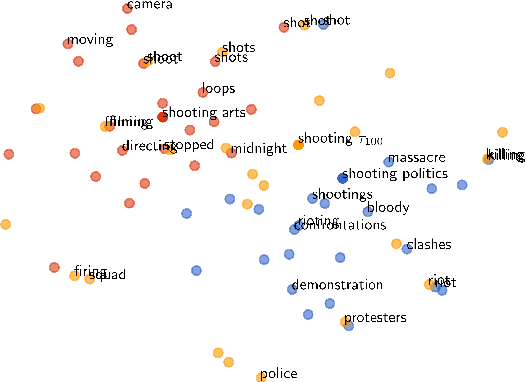
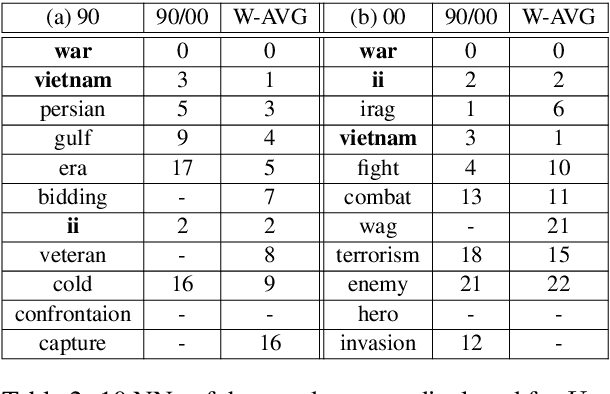
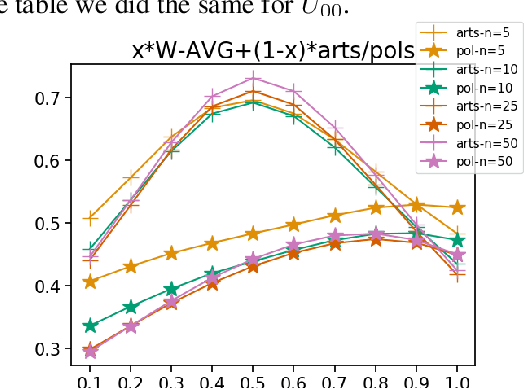
Word embeddings capture semantic relationships based on contextual information and are the basis for a wide variety of natural language processing applications. Notably these relationships are solely learned from the data and subsequently the data composition impacts the semantic of embeddings which arguably can lead to biased word vectors. Given qualitatively different data subsets, we aim to align the influence of single subsets on the resulting word vectors, while retaining their quality. In this regard we propose a criteria to measure the shift towards a single data subset and develop approaches to meet both objectives. We find that a weighted average of the two subset embeddings balances the influence of those subsets while word similarity performance decreases. We further propose a promising optimization approach to balance influences and quality of word embeddings.