 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Identification of Types of Alterations in Historical Manuscripts
Paper and Code
Mar 23, 2020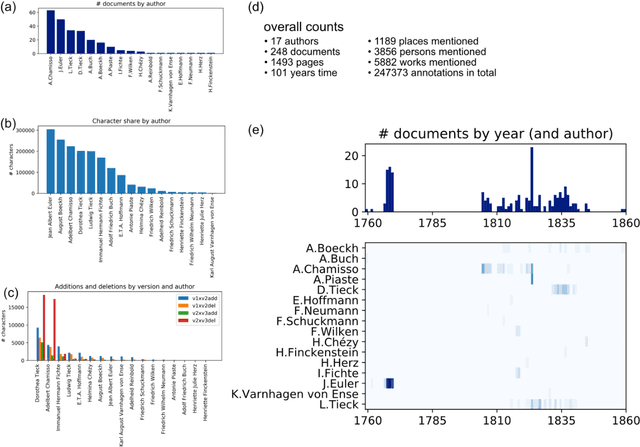
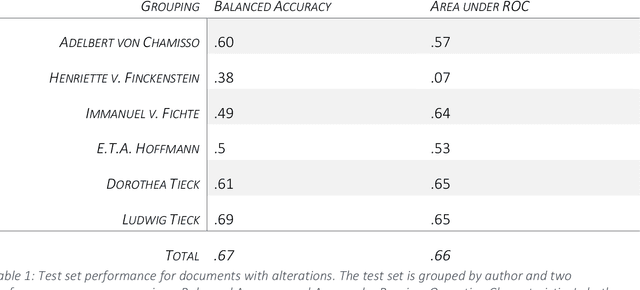


Alterations in historical manuscripts such as letters represent a promising field of research. On the one hand, they help understand the construction of text. On the other hand, topics that are being considered sensitive at the time of the manuscript gain coherence and contextuality when taking alterations into account, especially in the case of deletions. The analysis of alterations in manuscripts, though, is a traditionally very tedious work. In this paper, we present a machine learning-based approach to help categorize alterations in documents. In particular, we present a new probabilistic model (Alteration Latent Dirichlet Allocation, alterLDA in the following) that categorizes content-related alterations. The method proposed here is developed based on experiments carried out on the digital scholarly edition Berlin Intellectuals, for which alterLDA achieves high performance in the recognition of alterations on labelled data. On unlabelled data, applying alterLDA leads to interesting new insights into the alteration behavior of authors, editors and other manuscript contributors, as well as insights into sensitive topics in the correspondence of Berlin intellectuals around 1800. In addition to the findings based on the digital scholarly edition Berlin Intellectuals, we present a general framework for the analysis of text genesis that can be used in the context of other digital resources representing document variants. To that end, we present in detail the methodological steps that are to be followed in order to achieve such results, giving thereby a prime example of an Machine Learning application the Digital Humanities.