 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Analysis of Korean Public AI Hub Parallel Corpora and in-depth Analysis using LIWC
Paper and Code
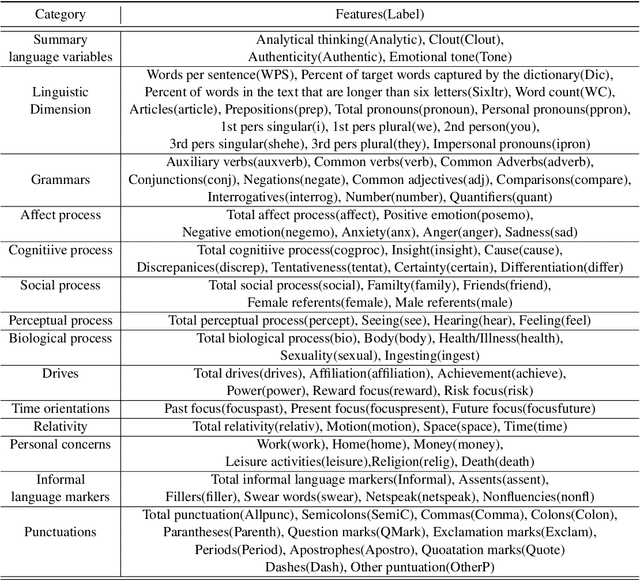
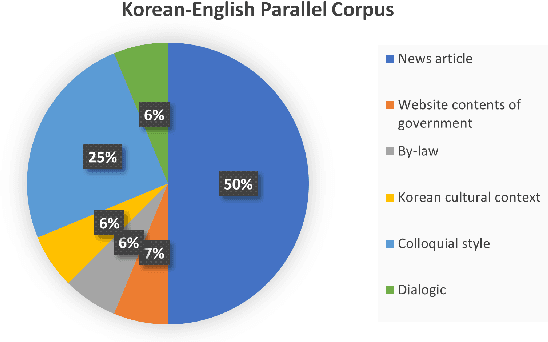
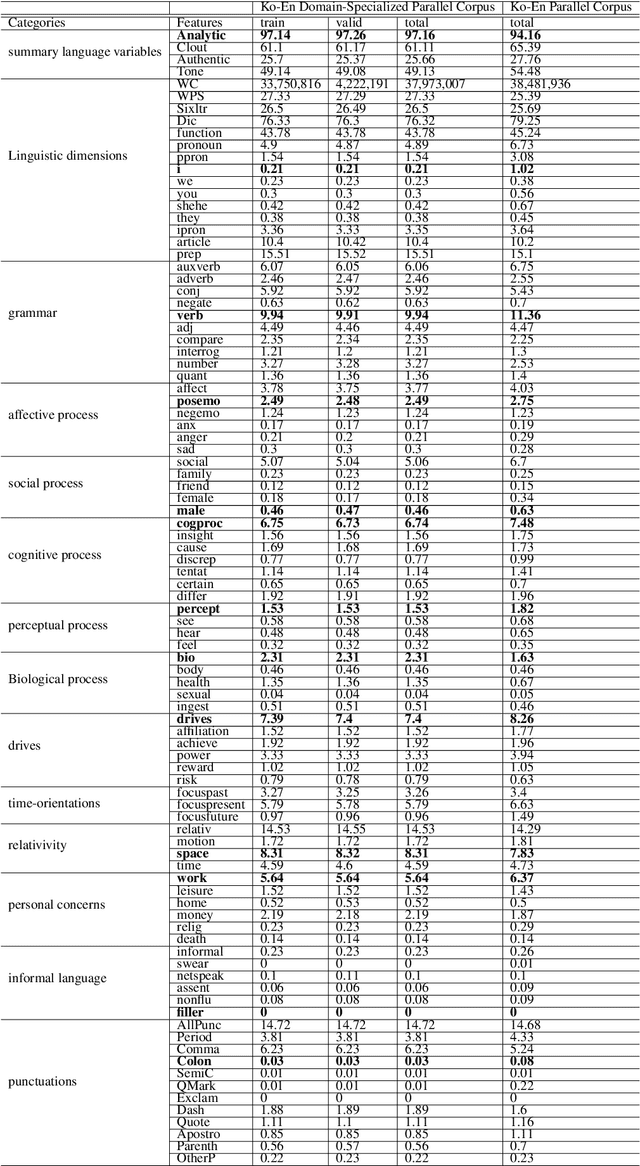

Machine translation (MT) system aims to translate source language into target language. Recent studies on MT systems mainly focus on neural machine translation (NMT). One factor that significantly affects the performance of NMT is the availability of high-quality parallel corpora. However, high-quality parallel corpora concerning Korean are relatively scarce compared to those associated with other high-resource languages, such as German or Italian. To address this problem, AI Hub recently released seven types of parallel corpora for Korean. In this study, we conduct an in-depth verification of the quality of corresponding parallel corpora through Linguistic Inquiry and Word Count (LIWC) and several relevant experiments. LIWC is a word-counting software program that can analyze corpora in multiple ways and extract linguistic features as a dictionary base. To the best of our knowledge, this study is the first to use LIWC to analyze parallel corpora in the field of NMT. Our findings suggest the direction of further research toward obtaining the improved quality parallel corpora through our correlation analysis in LIWC and NMT performance.