 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuxiliary Sequence Labeling Tasks for Disfluency Detection
Oct 24, 2020
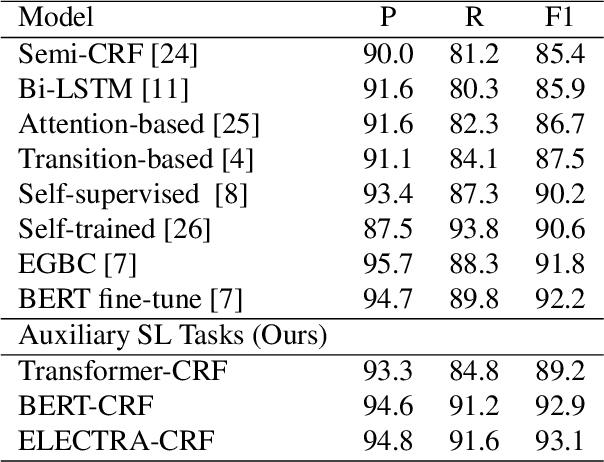
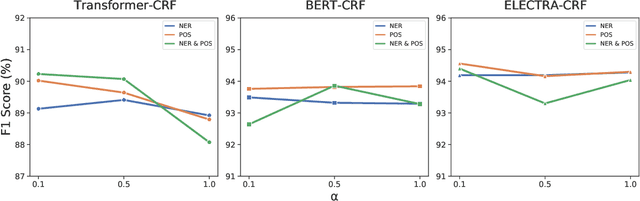
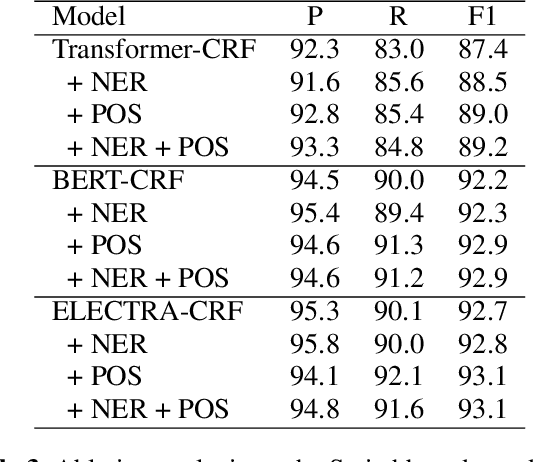
Detecting disfluencies in spontaneous speech is an important preprocessing step in natural language processing and speech recognition applications. In this paper, we propose a method utilizing named entity recognition (NER) and part-of-speech (POS) as auxiliary sequence labeling (SL) tasks for disfluency detection. First, we show that training a disfluency detection model with auxiliary SL tasks can improve its F-score in disfluency detection. Then, we analyze which auxiliary SL tasks are influential depending on baseline models. Experimental results on the widely used English Switchboard dataset show that our method outperforms the previous state-of-the-art in disfluency detection.
Reference and Document Aware Semantic Evaluation Methods for Korean Language Summarization
Apr 29, 2020
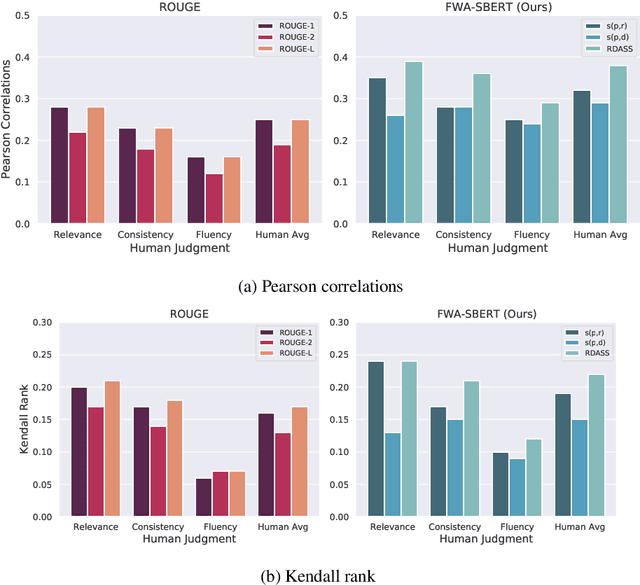

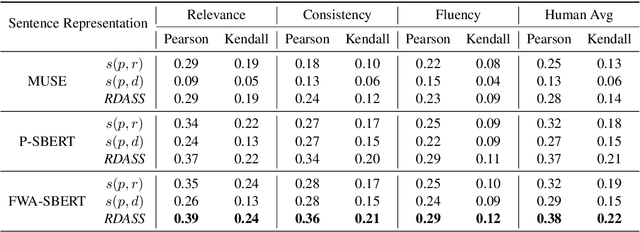
Text summarization refers to the process that generates a shorter form of text from the source document preserving salient information. Recently, many models for text summarization have been proposed. Most of those models were evaluated using recall-oriented understudy for gisting evaluation (ROUGE) scores. However, as ROUGE scores are computed based on n-gram overlap, they do not reflect semantic meaning correspondences between generated and reference summaries. Because Korean is an agglutinative language that combines various morphemes into a word that express several meanings, ROUGE is not suitable for Korean summarization. In this paper, we propose evaluation metrics that reflect semantic meanings of a reference summary and the original document, Reference and Document Aware Semantic Score (RDASS). We then propose a method for improving the correlation of the metrics with human judgment. Evaluation results show that the correlation with human judgment is significantly higher for our evaluation metrics than for ROUGE scores.