 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKanana: Compute-efficient Bilingual Language Models
Feb 26, 2025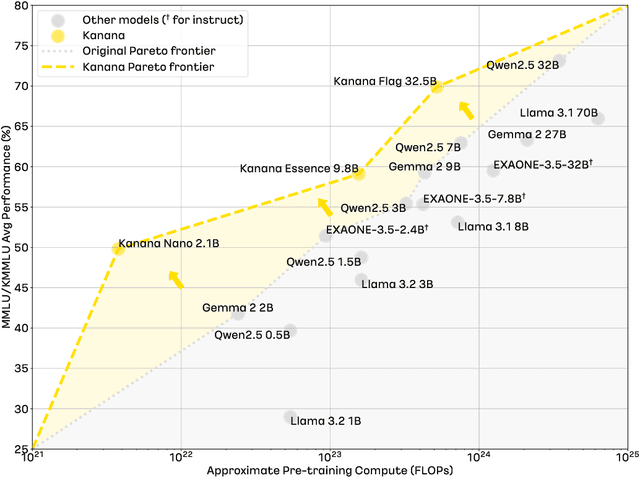



We introduce Kanana, a series of bilingual language models that demonstrate exceeding performance in Korean and competitive performance in English. The computational cost of Kanana is significantly lower than that of state-of-the-art models of similar size. The report details the techniques employed during pre-training to achieve compute-efficient yet competitive models, including high quality data filtering, staged pre-training, depth up-scaling, and pruning and distillation. Furthermore, the report outlines the methodologies utilized during the post-training of the Kanana models, encompassing supervised fine-tuning and preference optimization, aimed at enhancing their capability for seamless interaction with users. Lastly, the report elaborates on plausible approaches used for language model adaptation to specific scenarios, such as embedding, retrieval augmented generation, and function calling. The Kanana model series spans from 2.1B to 32.5B parameters with 2.1B models (base, instruct, embedding) publicly released to promote research on Korean language models.
FunctionChat-Bench: Comprehensive Evaluation of Language Models' Generative Capabilities in Korean Tool-use Dialogs
Nov 21, 2024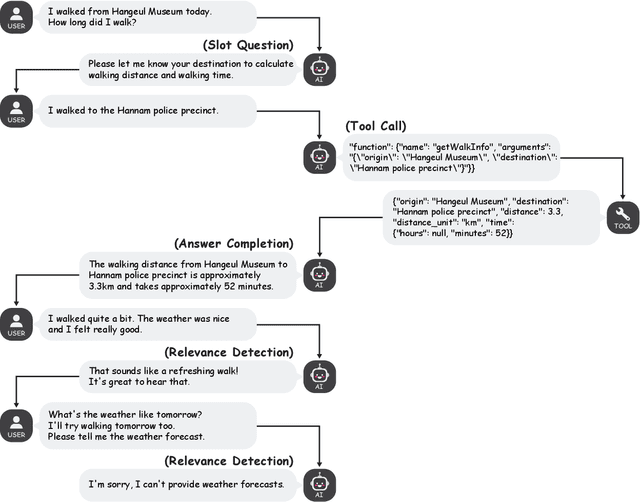
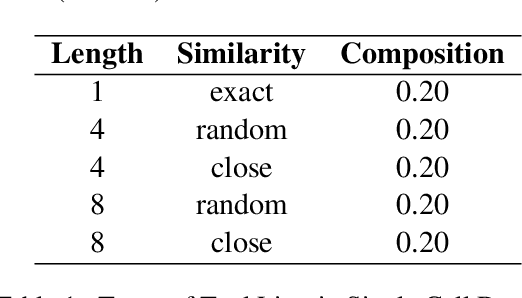
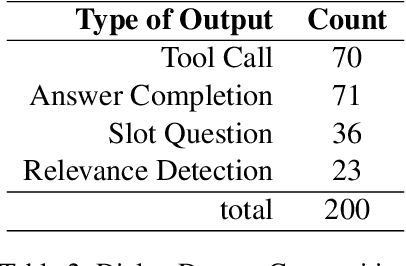

This study investigates language models' generative capabilities in tool-use dialogs. We categorize the models' outputs in tool-use dialogs into four distinct types: Tool Call, Answer Completion, Slot Question, and Relevance Detection, which serve as aspects for evaluation. We introduce FunctionChat-Bench, comprising 700 evaluation items and automated assessment programs. Using this benchmark, we evaluate several language models that support function calling. Our findings indicate that while language models may exhibit high accuracy in single-turn Tool Call scenarios, this does not necessarily translate to superior generative performance in multi-turn environments. We argue that the capabilities required for function calling extend beyond generating tool call messages; they must also effectively generate conversational messages that engage the user.
Auxiliary Sequence Labeling Tasks for Disfluency Detection
Oct 24, 2020
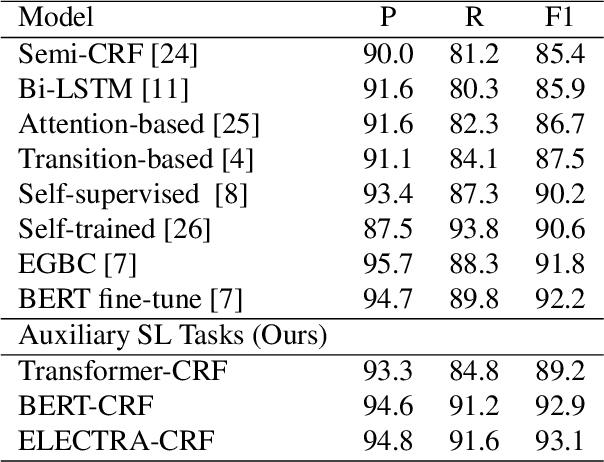
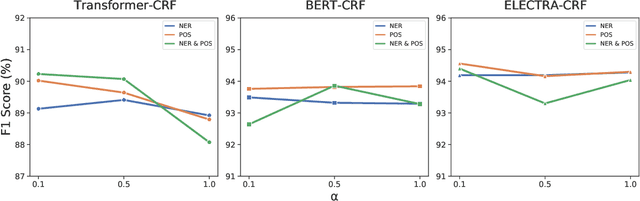
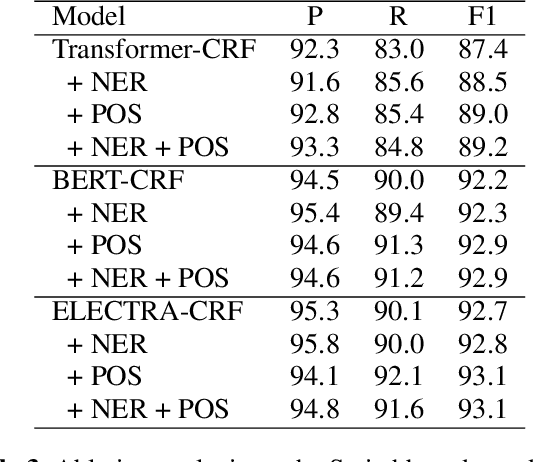
Detecting disfluencies in spontaneous speech is an important preprocessing step in natural language processing and speech recognition applications. In this paper, we propose a method utilizing named entity recognition (NER) and part-of-speech (POS) as auxiliary sequence labeling (SL) tasks for disfluency detection. First, we show that training a disfluency detection model with auxiliary SL tasks can improve its F-score in disfluency detection. Then, we analyze which auxiliary SL tasks are influential depending on baseline models. Experimental results on the widely used English Switchboard dataset show that our method outperforms the previous state-of-the-art in disfluency detection.
Reference and Document Aware Semantic Evaluation Methods for Korean Language Summarization
Apr 29, 2020
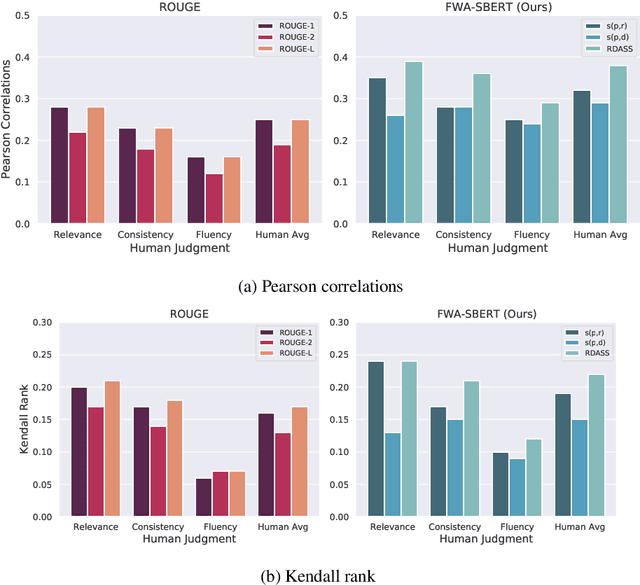

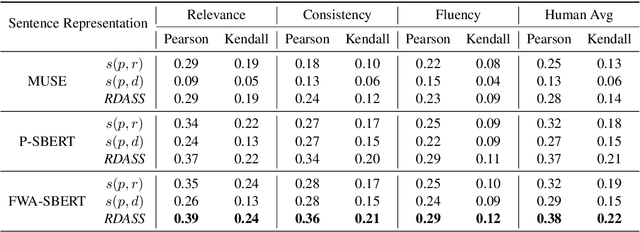
Text summarization refers to the process that generates a shorter form of text from the source document preserving salient information. Recently, many models for text summarization have been proposed. Most of those models were evaluated using recall-oriented understudy for gisting evaluation (ROUGE) scores. However, as ROUGE scores are computed based on n-gram overlap, they do not reflect semantic meaning correspondences between generated and reference summaries. Because Korean is an agglutinative language that combines various morphemes into a word that express several meanings, ROUGE is not suitable for Korean summarization. In this paper, we propose evaluation metrics that reflect semantic meanings of a reference summary and the original document, Reference and Document Aware Semantic Score (RDASS). We then propose a method for improving the correlation of the metrics with human judgment. Evaluation results show that the correlation with human judgment is significantly higher for our evaluation metrics than for ROUGE scores.
SYSTRAN's Pure Neural Machine Translation Systems
Oct 18, 2016
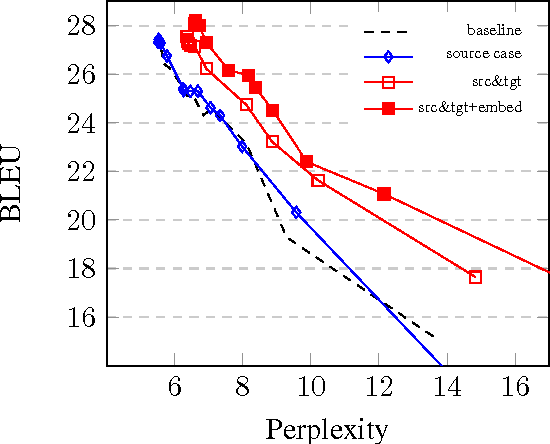
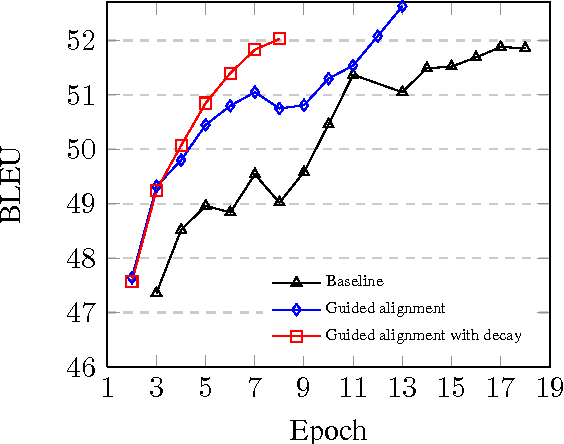
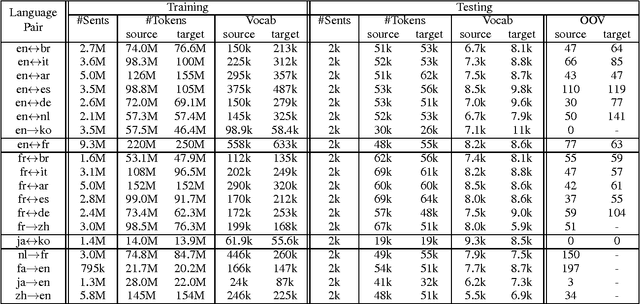
Since the first online demonstration of Neural Machine Translation (NMT) by LISA, NMT development has recently moved from laboratory to production systems as demonstrated by several entities announcing roll-out of NMT engines to replace their existing technologies. NMT systems have a large number of training configurations and the training process of such systems is usually very long, often a few weeks, so role of experimentation is critical and important to share. In this work, we present our approach to production-ready systems simultaneously with release of online demonstrators covering a large variety of languages (12 languages, for 32 language pairs). We explore different practical choices: an efficient and evolutive open-source framework; data preparation; network architecture; additional implemented features; tuning for production; etc. We discuss about evaluation methodology, present our first findings and we finally outline further work. Our ultimate goal is to share our expertise to build competitive production systems for "generic" translation. We aim at contributing to set up a collaborative framework to speed-up adoption of the technology, foster further research efforts and enable the delivery and adoption to/by industry of use-case specific engines integrated in real production workflows. Mastering of the technology would allow us to build translation engines suited for particular needs, outperforming current simplest/uniform systems.